Las imagenes del challenge se dividen en train (3500 pacientes o 7000 imagenes) y test (500 pacientes o 1000 imagenes), pero solo hay anotaciones para train ya que las de test se usan para evaluar los modelos y entregar los resultados al challenge. Cada fila de las anotaciones contiene información sobre un paciente, siendo lo más relevante los filenames de los ojos izquierdo y derecho y las labels (por ejemplo: [0,0,1,0,0,1,0,0]).
Se trata de un problema de clasificación de imágenes multi-label (cada sample puede pertenecer a más de una clase), pero tiene la peculiaridad de que cada sample son dos imágenes (la gran mayoría de los modelos están pensados para recibir una sola imagen de entrada).
La implementacion del Dataset en pytorch, se puede encontrar aquí. Como se puede ver devuelve dos imágenes y los labels de esas dos imágenes.
Se usa la resnet50 de pytorch preentrenada en Imagenet, pero no se podía usar en su forma por defecto ya que está pensada para una sola imagen de entrada (un batch de ellas).
Investigando, encontré este paper que también intenta clasificar ODIR. En él se propone como baseline una arquitectura que usa las dos imágenes como entrada y que está formada por una resnet feature extractor, es decir sin la dense layer clasificadora del final, y un clasificador que usa las features de las dos imágenes concatenadas.
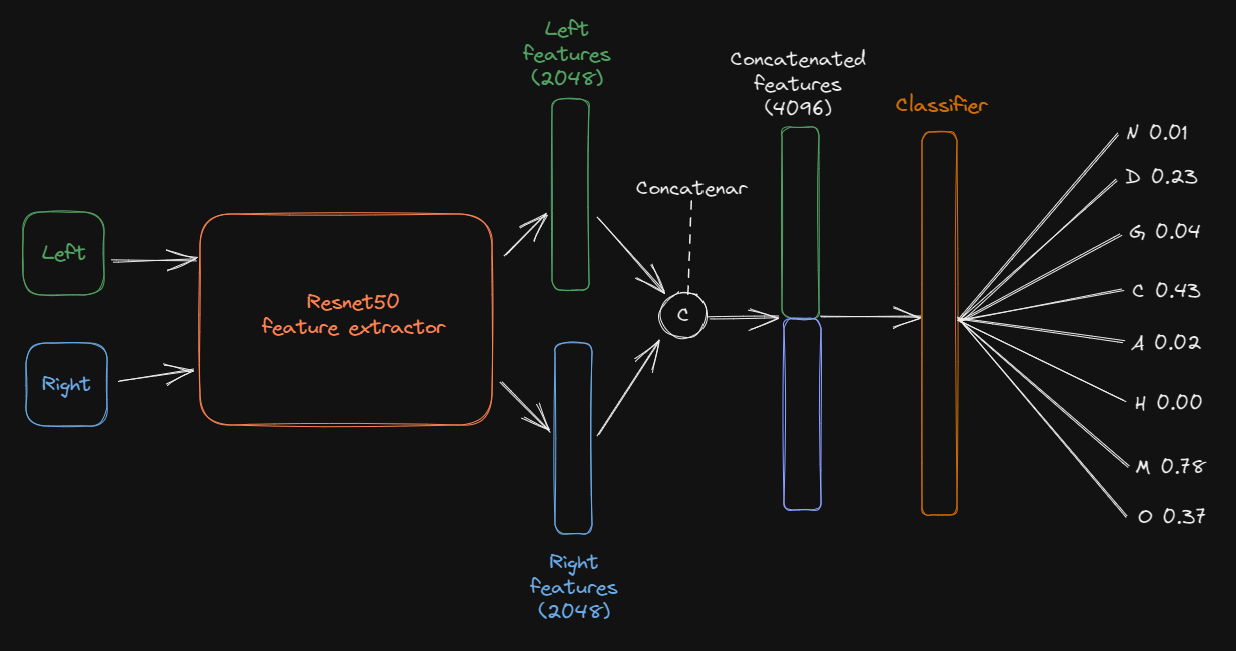
Usando una idea similar a la planteada en el paper, se implementa el modelo. Se experimenta con 3 versiones, en cada una el clasificador de features es diferente. Cabe destacar que se congelan todos los parametros excepto los del clasificador.
Se usan las mismas métricas que en el challenge: Kappa score, F1, AUC y score final (este es igual a la media de los tres primeros). Umbral=0.5.
Además del dataset, en el challenge se proporciona un script con un ejemplo de cálculo de estas métricas. Sin embargo, no es muy convencible cómo están calculadas así que se usan unas propias (se pueden ver aquí, en la función compute_challenge_metrics).
Los entrenamientos se trackean con tensorboard. Cada experimento tiene su propio enlace de TensorBoard.dev, pero aquí se pueden ver todos juntos.
Cada experimento está contenido en una notebook. Se pueden ejecutar en google colab clicando en el botón 'Open in Colab' arriba a la izquierda, pero no hace falta ya que incluyen los outputs. Todas ellas tienen la misma estructura:
- Separar las anotaciones en train y validación
- Entrenamiento: Para entrenar cada modelo de cada experimento se usa un mismo script (train.py) al que se le pasan diferentes argumentos (como el learning rate que se quiere usar). Se obtienen como salida el modelo entrenado, la carpeta de tensorboard con las métricas a lo largo de las épocas y un fichero .xlsx que contiene también esta métricas.
- Tensorboard: Visualizar las métricas de entrenamiento a lo largo de las epochs
- Test: Se evalúa el modelo en el dataset de validación con este script (es similar al de train). Se obtienen como salida dos ficheros .xlsx, uno con las probabilidades de cada paciente de este dataset y otro con las labels ground truth de los mismos.
- Test con el script de evaluación del challenge: Como ya se dijo, se implementan otras métricas diferentes a las de este script, pero se ejecuta igualmente.
- Resultados cuantitativos: además de las métricas de salida del script de test se muestra el classification report de sklearn y una matriz de confusión para cada label.
- Resultados cualitativos: Se muestra un sample de cada label con el ground truth y las predicciones.
- Dónde: experiment_0.ipynb
- Experimento 0 en TensorBoard.dev
- Motivación: Al ser el primer experimento se van a listar muchos hyperparametros:
- Se usan las imágenes originales con resize a (224, 224). Son estas
- Split 80/20 de las anotaciones de train para obtener train y val datasets.
- Se normalizan las imágenes con la media y desviación típica de Imagenet.
- Versión 0 de la resnet dual
- loss function: torch.nn.BCEWithLogitsLoss
- optimizer: torch.optim.SGD con lr=0.001 y momentum=0.9
- Epochs = 50
- Sistema de early stopping con paciencia 5
- torch.sigmoid para pasar los logits a probabilidades
- Discusión: Como se puede ver en las gráficas de entrenamiento, el modelo aprende muy lento y, aunque parece que se puede entrenar por más epochs, da resultados muy malos (score final: 0.2464).
- Dónde: experiment_1.ipynb
- Experimento 1 en TensorBoard.dev
- Motivación: Se decide no entrenar por más epochs el modelo anterior y se plantea otro entrenamiento con imágenes preprocesadas para tener un único formato de imagen. Se teme que el modelo aprenda los ratios de las mismas así que se plantean dos transformaciones: una para extraer el FOV (cropear los píxeles no negros) y otra para cropear de forma circular la retina (esto hace que quepan las retinas que por defecto no caben en la imagen, a coste de eliminar un trozo del exterior). Se aplican en este orden: FOVExtraction --> CircleCrop --> FOVExtraction --> Resize(224,224). Aquí estan las imágenes preprocesadas.
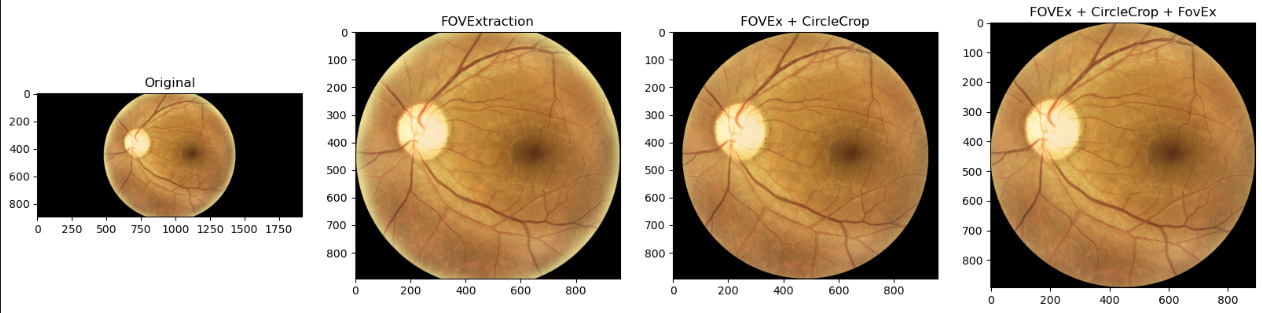
- Discusión: Al igual que en el primer experimento, el modelo aprende muy lento y cuando se detiene el entrenamiento los resultados son muy malos (score final: 0.2229), pero con este preprocesado se intuye que la red se va a fijar más en la propia retina y no tanto en los ratios de la imagen. A partir de ahora se van a usar estas imágenes.
- Dónde: experiment_2.ipynb, experiment_3.ipynb, experiment_4.ipynb
- Experimento 2 en TensorBoard.dev, Experimento 3 en TensorBoard.dev, Experimento 4 en TensorBoard.dev
- Motivación: Se busca que la red aprenda más de prisa, así que se prueba con dos lr schedulers: torch.optim.lr_scheduler.LinearLR y torch.optim.lr_scheduler.CyclicLR
- Se aumentan las epochs a 100
- Se aumenta la paciencia a 20
- Experimento 2: lr=0.01, LinearLR con total_iters=50 y end_factor=0.1
- Experimento 3: lr=0.05, LinearLR con total_iters=50 y end_factor=0.1
- Experimento 4: CyclicLR con base_lr=0.001, max_lr=0.1, step_size_up=10 y mode='triangular2'
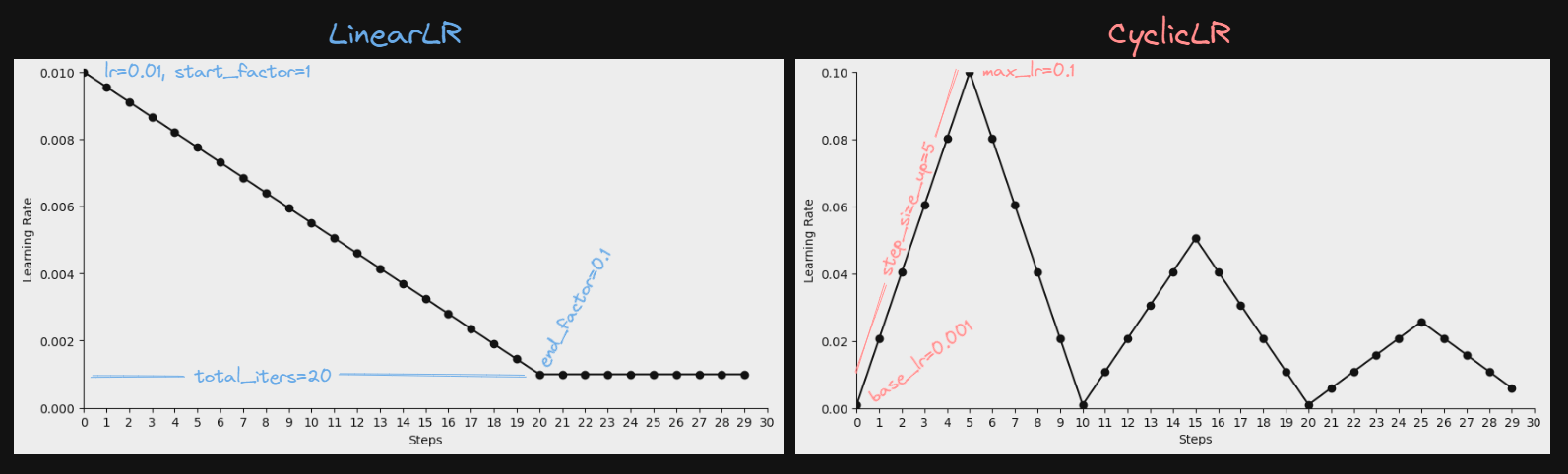
- Discusión: Las redes aprenden mucho más rápido que en los experimentos anteriores, llegando a converger. Lo malo es que no llegan a alcanzar los final scores esperados (0.3870, 0.4551, 0.4536). Cabe destacar algo que se repetirá mucho en los siguientes experimentos: Los modelos clasifican con un alto éxito C (cataratas) y en M (miopía), y un bajo éxito (nulo en estos experimento) A (AMD) y H (hypertensión). A partir de ahora se va a usar el LinearLR del experimento 3.
- Dónde: experiment_5.ipynb, experiment_6.ipynb, experiment_7.ipynb
- Experimento 5 en TensorBoard.dev, Experimento 6 en TensorBoard.dev, Experimento 7 en TensorBoard.dev
- Motivación: Pensando que quizá la arquitectura de red usada en los experimentos anteriores no sea suficientemente compleja, se plantean dos nuevas, NCNV1 y NCNV2 (se pueden ver en models.py).
- Experimento 5: se usa la resnet dual v1
- Experimento 6: se usa la resnet dual v2
- Experimento 7: se usa la resnet dual v2 dejando que llegue a las 100 epochs de entrenamineto.
- Discusión: Los resultados son similares a los del mejor experimento hasta ahora (el 3) en el caso del experimento 5 (score final: 0.4544), no sorprende ya que solo se añade una layer dropout. Son peores en el caso de los experimentos 6 y 7 (scores finales: 0.4023 en ambos), donde el clasificador es bastante más complejo. En estos últimos dos experimentos se ve por primera vez, en la gráfica de loss, que hay overfitting. A falta de seguir experimentando con la v2, se va a seguir usando la v0 del experimento 3.
- Dónde: experiment_8.ipynb, experiment_9.ipynb
- Experimento 8 en TensorBoard.dev, Experimento 9 en TensorBoard.dev
- Motivación: Se decide usar data augmentation esperando que la red no memorice el train dataset. Se repite el experimento 3 (el mejor) y el 7 (donde hay overfitting) con data augmentation. Se usa:
- transforms.RandomHorizontalFlip(p=0.5)
- transforms.RandomVerticalFlip(p=0.5)
- transforms.RandomRotation(degrees=30)
- transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1)
- Discusión: Repetir el experimento 3 con data augmentation no funcionó, los resultados empeoran (final score: 0.3944). Repetir el experimento 7 hizo, como se esperaba, que no haya overfitting, pero los resultados son peores a los de original (final score: 0.3469).
- Dónde: experiment_10.ipynb
- Experiment 10 en TensorBoard.dev
- Motivación: Se generan nuevas imágenes de entrenamiento con el mismo formato que las del experimento 1, pero esta vez de 512x512 (en vez de 224x224):
- Discusión: El entrenamiento llega más lejos que ningún otro (80 epochs) y se supera el mejor score hasta ahora, pero por muy poco (0.4569 frente a 0.4551). Sorprende más salto en tiempo de entrenamiento. Cabe destacar que es la primera vez que un modelo clasifica AMD (label A), y acierta 2 de 5.
- Dónde: experiment_11.ipynb
- Experiment 11 en TensorBoard.dev
- Motivación: Pensando que quizás los malos resultados obtenidos hasta ahora se deban al desbalanceo del dataset, se prueba uno de los varios métodos para tratar con este problema: usar una función de loss basada en pesos.
- Discusión: Se consiguen mejorar los resultados! --> kappa: 0.3487, f1: 0.4866, AUC: 0.7036, score final: 0.5130. Uno de los mejores experimentos era el 3 y tenía peores resultados --> kappa: 0.2814, f1: 0.3762, AUC: 0.7076, score final: 0.4551. Cabe destacar que, mientras que la precisión empeora un poco, el recall mejora mucho. Esto se puede ver en las probabilidades de los resultados cualitativos, se ve que el modelo arriesga más que antes (era más común que predijese pocas o ninnguna label para un sample). Otra cosa a destacar es la mejora en las predicciones de las labels A y H que, aunque siguen teniendo un f1 bajo (0.22 y 0.20), en la mayoría de los experimentos anteriores era nulo (sólo en el 10, el label A conseguía un f1 de 0.10).
-
Dónde: experiment_12.ipynb
-
Motivación: Este método, al igual que el anterior, también trata el desbalanceo. Balancear datasets multilabel es más complejo que hacerlo para las multiclase, ya que al resamplear una label se puede dar el resampleo de otras al mismo tiempo. En otros poyectos se usa oversampling en las clases minoritarias o undersampling en las mayoritarias, aquí se opta por un sampler que selecciona la label menos sampleada de manera aleatoria, parando cuando ya se han seleccionado len(dataset) samples (es decir, el tamaño del dataset es el mismo). No se usa la weighted loss del experimento anterior.
-
Discusión: Aunque los resultados (kappa: 0.3073, f1: 0.2494, AUC: 0.6713, score final: 0.4093) empeoran bastante con respecto a los mejores hasta ahora, la precisión (0.58) es mayor.