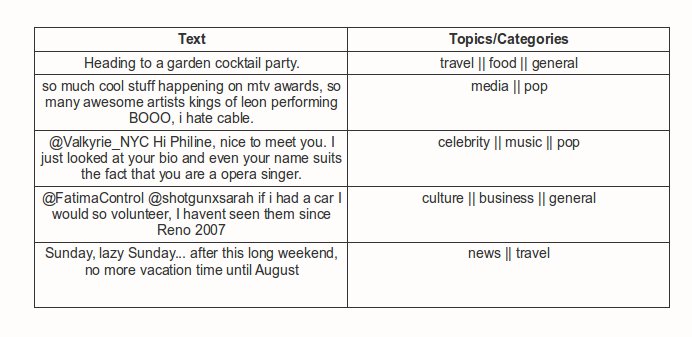
To categorize any form of text into 22 different topics
The categorizerClass.py and mcategorizerClass.py has the categorizer class with the function: getCategory(text)
- categorizerClass.py - based on 22 cluster seeds
- mcategorizerClass.py - based on 700+ cluster seeds (more precise)
- Create an object for any of the above two classes and pass text to this function to get the category
catObj = mcategorizerClass.Categorize()
cat = catObj.getCategory(text)
- Refer to csvInput and dumpInput python files for bulk topic processing
vectors.binfile is the W2V vectors bin, download the bigger 3.5 GB W2V vectors bin for better results. Link: code.google.com/p/word2vec/
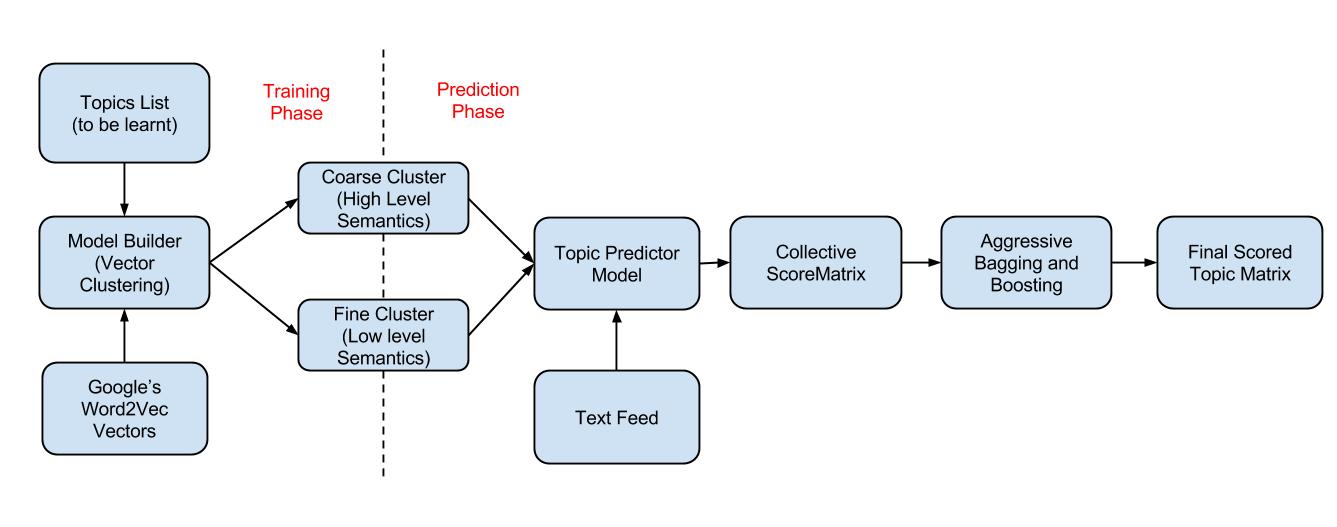
The Basic Idea
We use these Word2Vec vectors to form clusters by feeding the desired topics to be learnt as seeds to the model, we follow a unique approach in performing the clustering, that ultimately leads to the formation of clusters that capture the semantics of any topic fed into it.
USP's of our model,
- It is capable of predicting topics based on the context in which a word/phrase of the text occurs.
-
Example,
- Text 1: The number of by-products derived from cow’s milk is just unbelievable.
- Text 2: All the products sold by Flipkart are of high quality.
-
Our model is capable of determining that Text 1 is about FOOD Products and Text 2 is about any GENERAL product based on the context of the sentence.
-
It is equipped to learn any number of topics and the best part is you could specify what topics it needs to learn and categorize any given document into.
-
Example,
- You could specify that you want to learn 2 topics, say, Sports and Technology and the model will train itself for these two categories/topics and later the trained model could be used to predict to which topic any wild document could come under.
- A unique scoring mechanism has been developed, thus enabling us to tell how probable is each of the topics/categories given any document, we even rank the topics in descending order given any document (we don’t give out the scores as part of our results, maybe in future we would include that feature) before returning to the customer.
- The model has also been crafted in a way that, it does not learn all the noisy topics from the text,meticulous evaluations are done before we tag the text under any topic (The algorithms that we use to achieve this is our secret recipe), thus ensuring the accuracy of the model.
- We do analysis at both coarse and finer levels of topics, thus enabling our model to be bang on when it does a prediction.
* We currently have a set of 22 coarse topics that in turn have 750+ finer topics contained in them.
Eg. Music is a coarse topic and Jazz, Pop, Melody, etc are finer topics.
-
As our model is semi supervised we don’t have train or test data to evaluate our model, but we did randomly sample a set of 5 tweets from twitter and have presented the results below (we got 4 out of 5 right !).