This script uses the sampling facilities built into Qumulo Core to provide an overview of capacity consumption first by user, and then by area/path of the filesystem tree. It reports the file owner whether it's a local Qumulo admin, NFS user, or AD/LDAP user managed externally. It has the added feature of being able to assign a dollar amount to capacity to report the capacity utilization in money terms in addition to bytes consumed.
Imagine you have a hundred or a thousand artists or researchers all busily collaborating on a project. They create data, and sometimes they forget to go clean it up. You want to get your army of talented professionals to reduce their capacity consumption. What do you tell them? This script breaks down a tree by user and then shows, for each user, where that user consumes space in the tree.
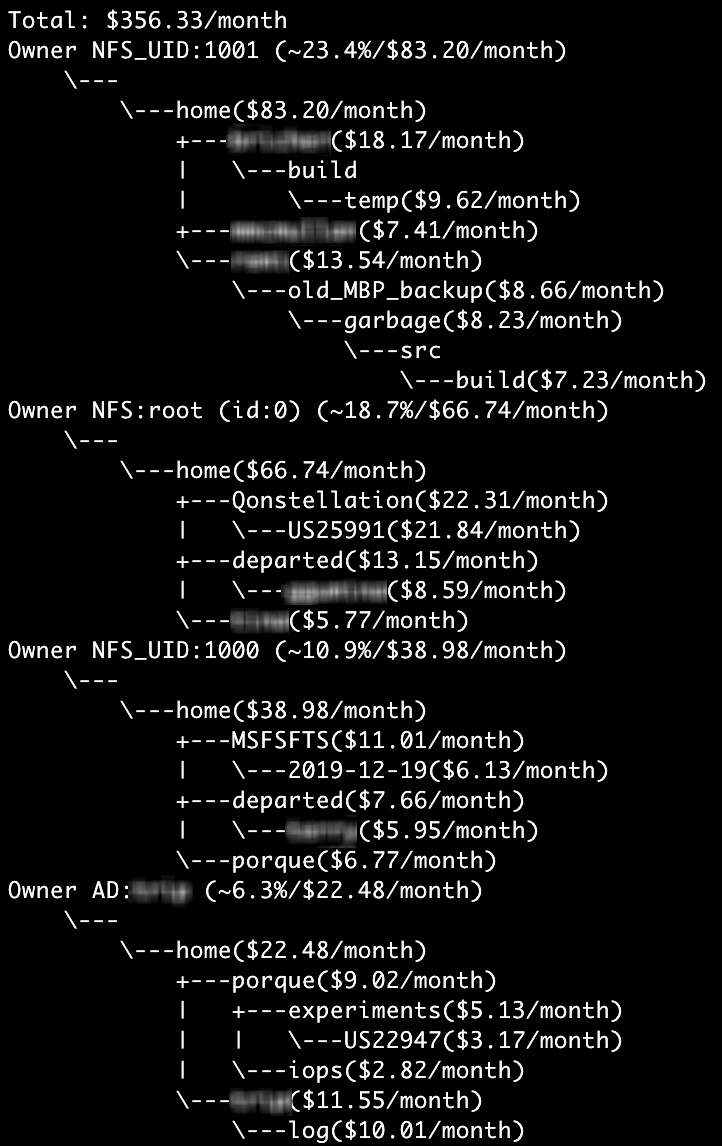
python3 capacity_by_user.py -C qumulo.local -U admin -P $PASS /home -s 10000 -x 3 -D 50
This command will look at a sampled set of items from the "/home" directory and subdirectories (which in this case is mostly users' scratch space). It assigns a value of $50 to the cost per terabyte (maybe that's the amount you bill your users per month). It will limit the output to a maximum of 3 leaves per user to keep things succinct.
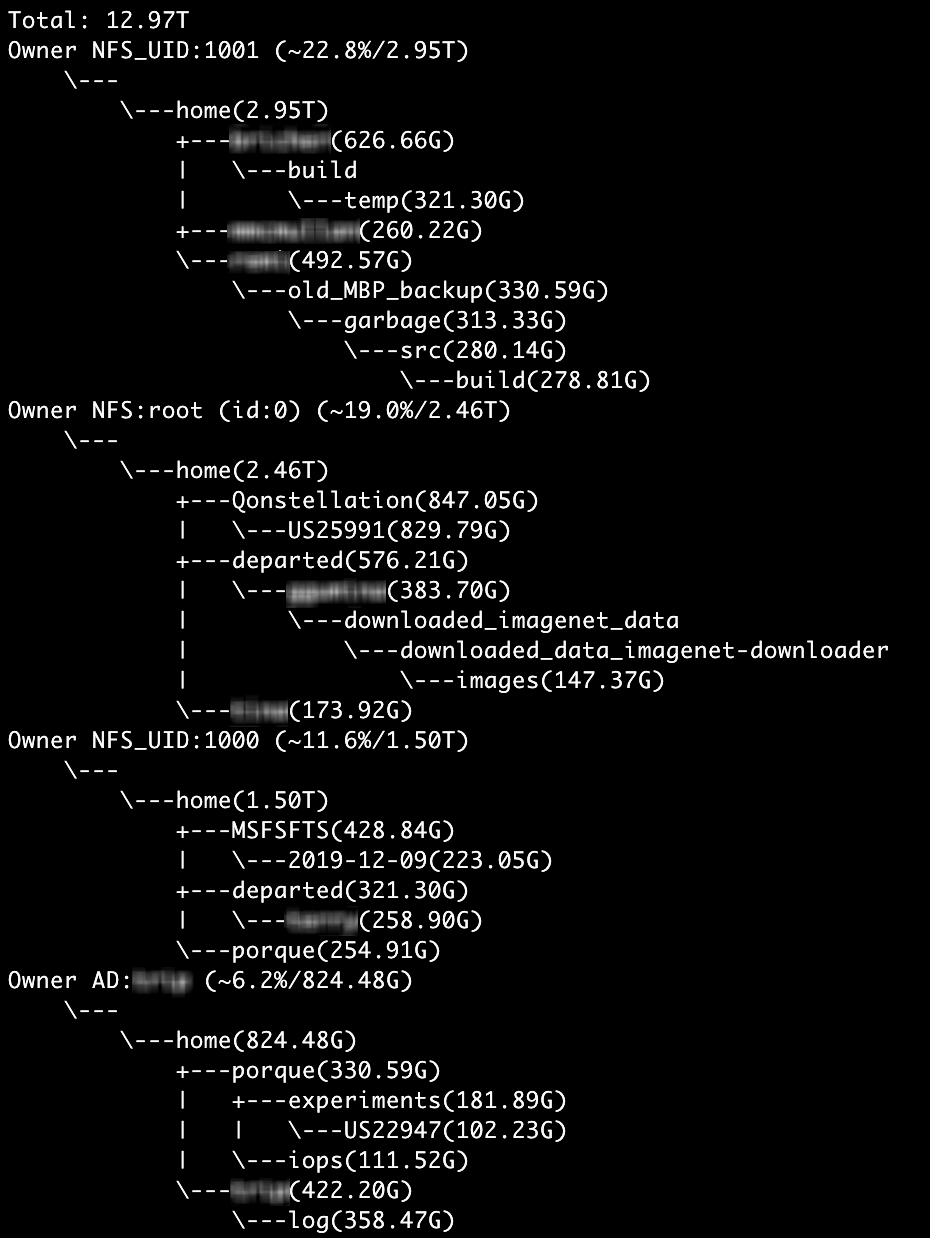
python3 capacity_by_user.py -C qumulo.local -U admin -P $PASS /home -s 10000 -x 3
This command is the same as the first example. It reports by capacity rather than dollar amounts as the -D 50 argument was removed.
Requirements
- python 3.4.11 or newer
- python qumulo_api package 4.0.0 or newer
usage: capacity_by_user.py [-h] [-U USER] [-P PASSWORD] [-C CLUSTER] [-p PORT]
[-s SAMPLES] [-c CONCURRENCY] [-m MIN_SAMPLES]
[-x MAX_LEAVES] [-D DOLLARS_PER_TERABYTE] [-i] [-A]
path
positional arguments:
path Filesystem path to sample
optional arguments:
-h, --help show this help message and exit
-U USER, --user USER The user to connect as (default: admin)
-P PASSWORD, --password PASSWORD
The password to connect with (default: admin)
-C CLUSTER, --cluster CLUSTER
The hostname of the cluster to connect to (default:
qumulo)
-p PORT, --port PORT The port to connect to (default: 8000)
-s SAMPLES, --samples SAMPLES
The number of samples to take (default: 2000)
-c CONCURRENCY, --concurrency CONCURRENCY
The number of threads to query with (default: 10)
-m MIN_SAMPLES, --min-samples MIN_SAMPLES
The minimum number of samples to show at a leaf in
output (default: 5)
-x MAX_LEAVES, --max-leaves MAX_LEAVES
The maximum number of leaves to show per user
(default: 30)
-D DOLLARS_PER_TERABYTE, --dollars-per-terabyte DOLLARS_PER_TERABYTE
Show capacity in dollars. Set conversion factor in
$/TB/month
-i, --confidence-interval
Show 95% confidence intervals
-A, --allow-self-signed-server
Silently connect to self-signed servers