此项目基于Scrapy爬虫框架,爬取百度百科中医疗相关数据,使用MongoDB存储解析得到的结构化数据,最后使用neo4j构建知识图谱并进行可视化展示
抛砖引玉,目前项目还处于打磨阶段,后续可以进一步拓宽和深化爬虫的能力,构建更大更完善的知识图谱
安装完毕MongoDB后,进入MongoDB安装目录
cd <你的MongoDB安装目录>随后执行以下命令启动MongoDB服务,其中--dbpath参数指定了数据库存放位置
./bin/mongod --dbpath data/可以通过以下python脚本测试MongoDB服务是否正确启动:
from pymongo import MongoClient
client = MongoClient('localhost')
print(client)期望得到以下输出:
MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True)
neo4j需要匹配相应版本的java才能使用,经测试在本项目中可以使用neo4j Community 3.5 和 Java SE 11 的组合
可以通过以下方法查看本机的Java版本:
java --version安装neo4j后,进入neo4j安装目录:
cd <你的neo4j安装目录>执行以下命令启动neo4j服务:
./bin/neo4j console测试以及配置neo4j数据库,在浏览器中访问:
localhost:7474
若neo4j服务正常启动,则可以进入neo4j的可视化页面,初始用户名与密码均为neo4j,初次登录后会要求重新设置密码后才可使用
splash能够帮助我们爬取使用JavaScript脚本动态渲染的html页面,百度百科页面大量采用动态渲染机制,因此需要splash帮助我们成功爬取到有用信息
splash依赖于docker部署,docker安装, docker教程
安装完docker后,执行以下命令拉取splash镜像:
docker pull scrapinghub/splash使用以下docker命令启动splash服务:
docker run -p 8050:8050 scrapinghub/splash也可以通过docker的可视化界面(如果安装了)来启动splash,点击任务栏中的小鲸鱼即可呼出docker图形界面
启动百度百科爬虫,可以通过调整BaikeMedical.py文件中的start_urls来增加爬取的内容:
cd MedicalKG
python3 run.py爬取百度百科页面目标区域:
 在MongoDB中查看爬取得到的数据:
在MongoDB中查看爬取得到的数据:
 完成数据的爬取操作后,执行脚本进行知识图谱的构建:
完成数据的爬取操作后,执行脚本进行知识图谱的构建:
python3 create_KG.py \
--mongo_url <MongoDB服务访问地址,默认为localhost> \
--neo4j_url <neo4j服务访问地址,默认为bolt://localhost:7687> \
--neo4j_name <neo4j数据库用户名> \
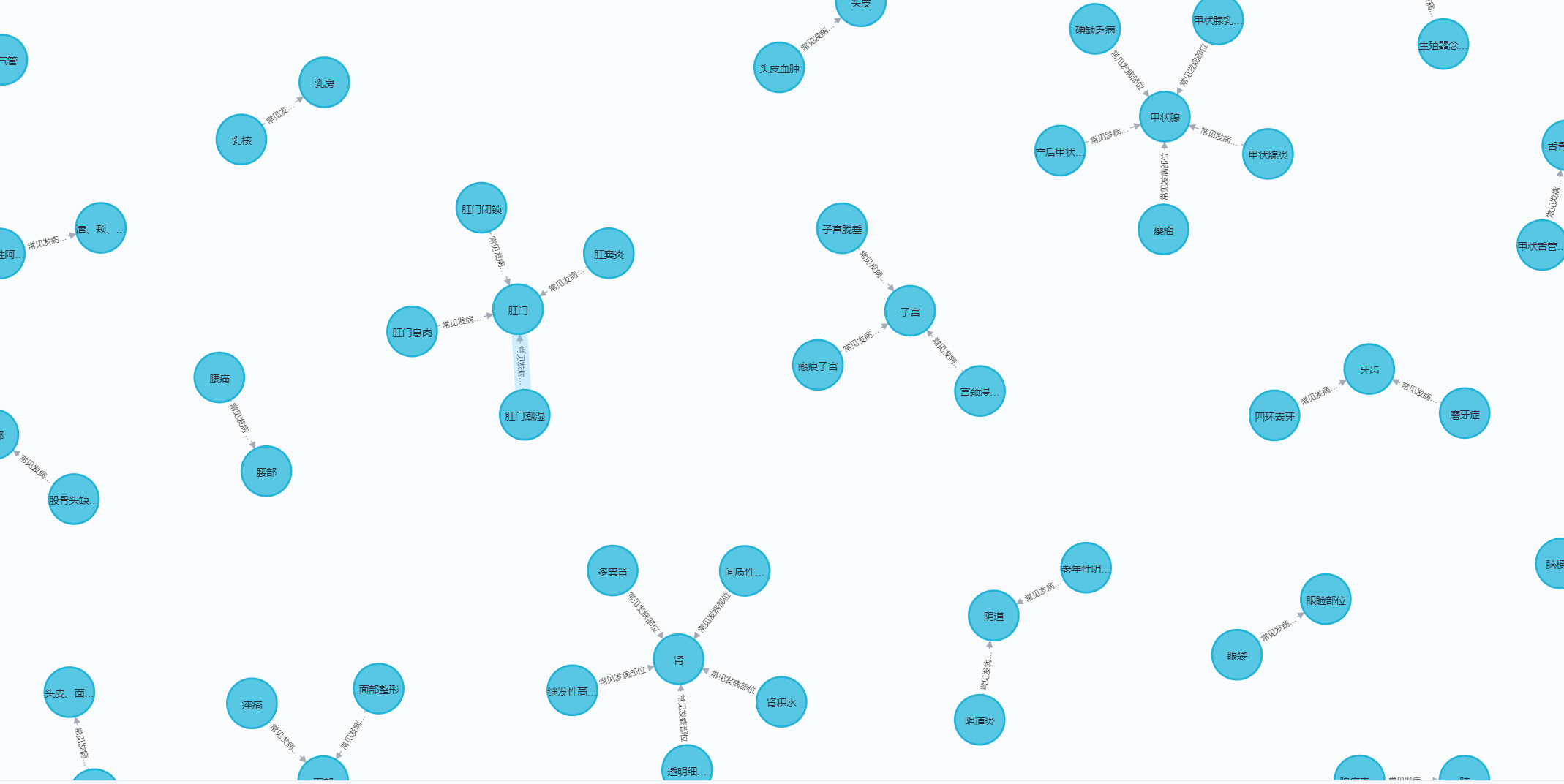
--neo4j_password <neo4j数据库访问密码>可通过访问 localhost:7474来查看知识图谱构建情况: