


blog_reprint是用来将在线或者本地的HTML转换为markdown格式文件的工具,现在内置支持的博客包括:
- CSDN
- 博客园
- 简书
- 印象笔记(导出本地HTML文件)
- 自建博客
usage: blog_parse.py [-h] [-b {cnblogs,csdn,evernote,jianshu,others}]
[-p OUT_PATH] [-o OUT_FILE] [-u URL] [-c CONTENT_ID]
[-t TITLE_ID] [-l LOCAL_HTML] [-i CLOUT_IMAGE_BASE]
[-f CLOUT_IMAGE_FOLDER]
reprint blog with markdown
optional arguments:
-h, --help show this help message and exit
common parameters in common blogs:
-b {cnblogs,csdn,evernote,jianshu,others}, --blog_name {cnblogs,csdn,evernote,jianshu,others}
which blog the url is from(default cnblogs)
-p OUT_PATH, --out_path OUT_PATH
path to save markdown file( default current folder)
-o OUT_FILE, --out_file OUT_FILE
file to save markdown
blog(other than evernote) specific parameters:
-u URL, --url URL url to parse
-c CONTENT_ID, --content_id CONTENT_ID
xpath of content body
-t TITLE_ID, --title_id TITLE_ID
xpath of title
evernote specific parameters:
-l LOCAL_HTML, --local_html LOCAL_HTML
full path of local evernote export html
-i CLOUT_IMAGE_BASE, --clout_image_base CLOUT_IMAGE_BASE
aliyun image link base
-f CLOUT_IMAGE_FOLDER, --clout_image_folder CLOUT_IMAGE_FOLDER
aliyun image link folder- 博客园:
python blog_parse.py -u https://www.cnblogs.com/zhaof/p/6953241.html -p C:/Users/14910/Desktop - CSDN:
python blog_parse.py -b csdn -u https://blog.csdn.net/work_you_will_see/article/details/84638750 -p C:/Users/14910/Desktop - 简书博客:
python blog_parse.py -b jianshu -u https://www.jianshu.com/p/95331e7a98cd -p C:/Users/14910/Desktop
- 得到title的xpath:
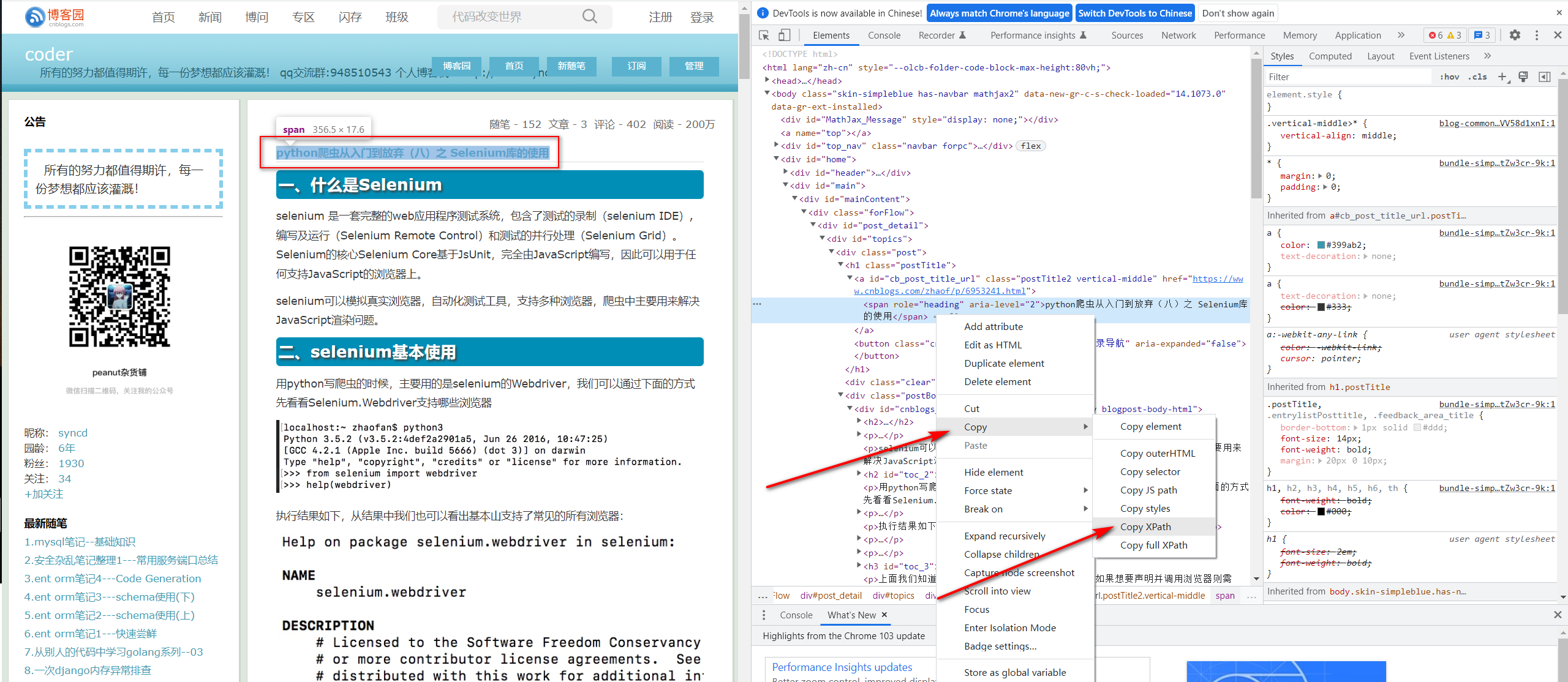
- 得到content的xpath:

- 使用命令:
python blog_parse.py -b others -c content_xpath -t title_xpath -u post_url -p C:/Users/14910/Desktop
- 将笔记导出单个html文件
- 将图片上传到图床,如果上传到图床的某个文件夹,需要指定下面的
-f参数 - 使用命令:
python blog_parse.py -l "C:/Users/14910/Desktop/VS code配置.html" -f VS_code配置 -b evernote
-
启动这个项目 2019-3-21
-
印象笔记转载-API
- 爬虫的方法,enml-这个就相当于使用印象笔记转markdown的那些工具,效果不好
- 爬虫,模拟登陆--- failed
- 既然能够模拟登陆了,那就不用在使用分享链接了啊,直接在网页版的印象笔记操作即可--->
failed
-
博客园
-
CSDN
-
其他自建博客
-
爬取文章标题作为新建的markdown文件的标题
-
提供多种方法,加上另一个html转markdown的工具--->
do not have the need -
图片链接会自动换行,导致图片显示不出来
fixed with set body_width = 0 -
图片保留html形式,设置images_as_html=True,但没有起作用
-
印象笔记导出之前需要将其图片名称进行修改--->两图片的空格替换为
%20 -
参数分组
-
爬取博客分类然后转化为markdown--->比如这个链接内的内容
-
增加requirements.txt