Execute:
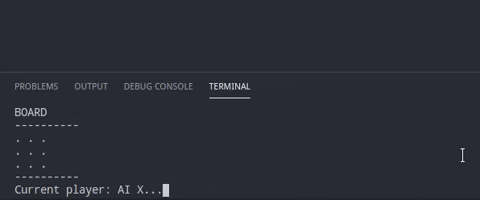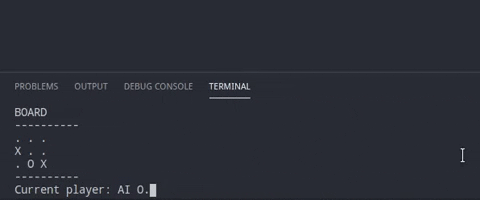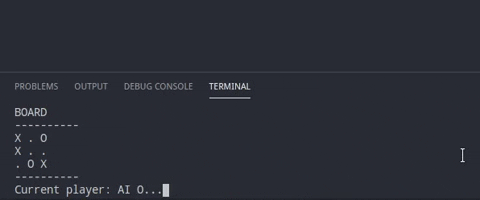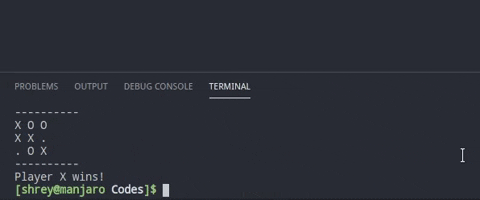
$ python tictactoeRandom.pyThis repository has 3 codes which plays the tic-tac-toe in different ways. Lets understand them one by one. Each code has the same function to check the win conditions. Only the algorithm to place the peg on the board changes.
File: tictactoe-AI/tictacRandom.py
This is as simple as the game can be. The computers just pic a spot randomly and if its not empty they place their peg on the board.
def playPlayer(playerID):
if len(positions) < 1:
return
position = choice(positions)
positions.remove(position)
board[position[0]][position[1]] = playerPeg[playerID]As we can see, if we have positions available, we randomly select one and place the playerPeg on the board.
File: tictactoe-AI/tictacOneStep.py
def getWinningState(board, playerID):
# Place playerPeg in every position and
# get return the winning state if found
for position in positions:
tempBoard = copy.deepcopy(board)
# Place a peg on the board
tempBoard[position[0]][position[1]] = playerPeg[playerID]
if didPlayerWin(tempBoard, playerID):
print('\nWinning position:',position)
return position
# No winning state
return []
def playPlayer(playerID):
if len(positions) < 1:
return
# Get winning position
winPosition = getWinningState(board, playerID)
if len(winPosition)>0:
position = winPosition
else:
position = choice(positions)
positions.remove(position)
board[position[0]][position[1]] = playerPeg[playerID]
This code implements the State Space Search Concept upto 1 Depth or 1 Layer. At each step it calculates if there is any position where the player can place the peg and directly win the game. If there is no such place available then just pick one randomly (as we are only searching for 1 level depth).
We can improve this code by checking if the opponent wins in 1 step and block the opponent.
File: tictactoe-AI/tictacSSS.py
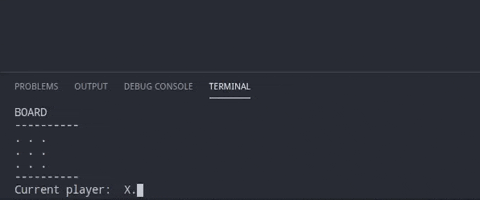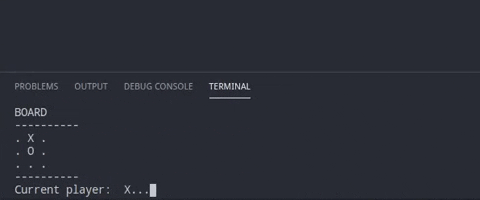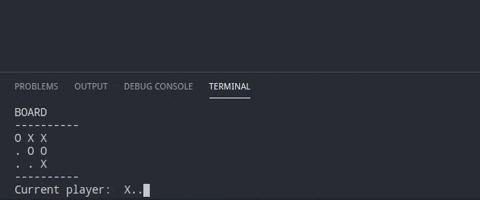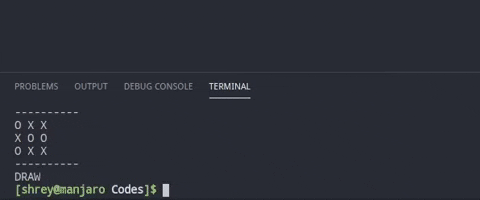
This is the most complex algorithm which searches all possible states to all levels to get the winning state. We then compare the length of the steps taken to reach the winning state and chose the path with least number of steps. At each step we also check if we win in one-step or opponent wins in one-step. In such case we directly place the peg on the winning position or block the opponent from winning.
# Calculate all positions
def positionWins(permBoard, playerID, positions):
if didPlayerWin(permBoard, playerID):
pegCount = countPegs(permBoard, playerID)
return pegCount
for position in positions:
tempBoard = copy.deepcopy(permBoard)
tempPositions = copy.deepcopy(positions)
tempPositions.remove(position)
tempBoard[position[0]][position[1]] = playerPeg[playerID]
return min(positionWins(tempBoard, playerID, tempPositions),
positionWins(permBoard, playerID, tempPositions))
return 20000This function calculates the steps taken by a taking a particular position. We do this by recursively putting a peg on the board one after another until the winning condition is reached. When winning condition is reached we send the path by counting the number of pegs on the old board and the new board.
We do this for all available positions on the board and choose the one with the least number of steps to the winning state. This is the best AI which we can make using State Space Search for this problem.