Информацию с сайтов можно получать с помощью web-scraping. Web-scraping - это получение контента с сайтов. Алгоритм выполняет GET-запросы на сайт и получая ответ, "парсит" (Парсинг - это автоматический сбор информации с какого-либо источника с целью его дальнейшей обработки и преобразования) HTML-документ, ищет заданные пользователем данные и преобразует их в удобный формат.
library(rvest)
library(selectr)
library(xml2)
library(jsonlite)
library(tidyverse)Мы будем анализировать фильмы, вышедшие с 2010 по 2018 годы с количеством голосов не менее 500. Для начала получим общее число фильмов, удовлетворяющих условию отбора, в 2018 году:
# Получение url
url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
# read-html
webpage <- read_html(url)
# Используя скрэпинг получить общее кол-во фильмов за год
number_html <- html_nodes(webpage, ".pagesFromTo")
number <- html_text(number_html)
number <- number[1]
number <- str_replace(number, ".{2,}из", "")
number <- as.numeric(str_trim(number))
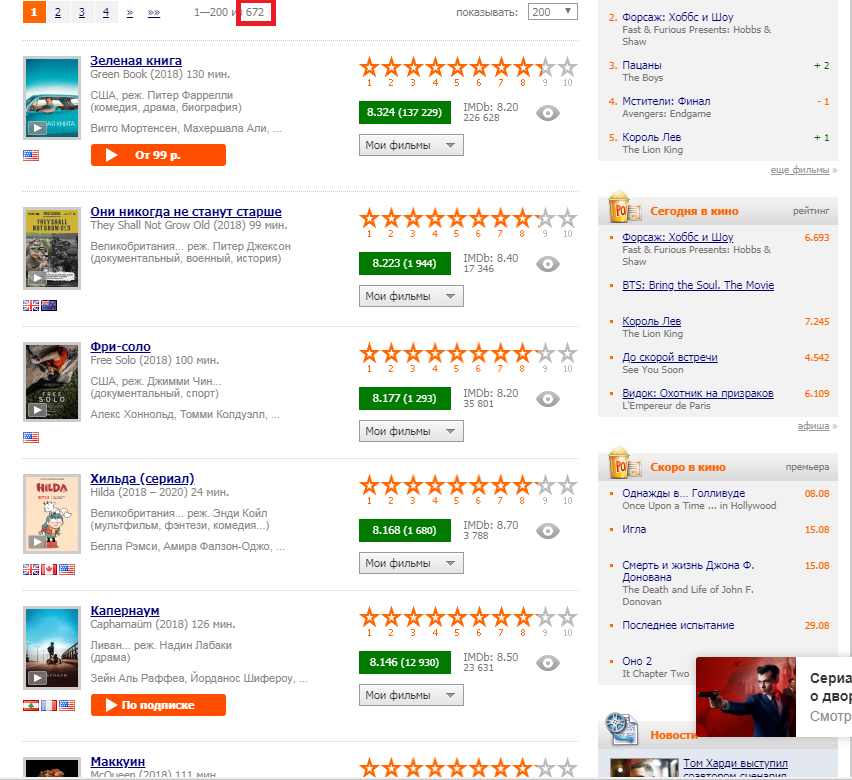
print(number)Рассчитаем количество страниц с нужными данными:
# Расчёт количества страниц с фильмами
page_number <- ceiling(number/200)
print(page_number)Генерируем ссылки на все страницы поиска за 2018 год:
page <- sapply(seq(1:page_number), function(n){
list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/perpage/200/page/", n, "/#results")
})
print(page)Далее запускаем функции, которая "парсит" название фильмов, количество голосов, рейтинг и основные жанры (максимум 3) для каждого из 672 фильмов 2018 года, удовлетворяющих условию отбора:
table <- lapply(page, function(k){
webpage <- read_html(k)
# Получение названия фильмов
# html_nodes - функция извлечения частей HTML-документа
# с помощью css или XPath селекторов
name_html <- html_nodes(webpage, ".name a")
# html_text - функция извлечения текста из HTML-документа
name <- html_text(name_html)
# Замена(удаление) частей текста
name <- str_replace(name, "\\(.{1,}\\)", "")
# Удаление лишних пробелов
name <- str_trim(name, side = "both")
# Перевод всех букв в нижний регистр
name <- tolower(name)
name <- str_replace_all(name, "[:punct:]", "")
# Получение рейтингов фильмов
rating_html <- html_nodes(webpage, ".numVote")
rat_vot <- html_text(rating_html)
rating <- as.numeric(str_trim(str_remove(rat_vot, "\\(.{1,}\\)"), side = "both"))
# str_extract - функция извлечения той части текста,
# которая совпадает с указанным паттерном
votes <- as.numeric(str_replace_all(str_extract(rat_vot, "\\(.{1,}\\)"),
"([:punct:])|([:space:])", ""))
# Получение жанров фильмов
genre_html <- html_nodes(webpage, ".gray_text")
genre <- html_text(genre_html)
genre <- str_replace_all(genre, "\n", "")
# Получение номеров элементов (функция which()), в которых
# есть указанный паттерн (функция str_detect())
detect <- which(str_detect(genre, "(реж\\.)|(\\()"))
genre <- genre[detect]
genre <- str_extract(genre, "\\(.{1,}\\)")
genre <- str_remove_all(genre, "(\\()|(\\))|(\\...)")
# Объединение данных в таблицу
df <- data.frame(NAME = name,
RATING = rating,
VOTES = votes,
GENRE = genre,
YEAR = 2018, stringsAsFactors = FALSE)
})
# Конвертация из списка в таблицу
table <- do.call(rbind.data.frame, table)| NAME | RATING | VOTES | GENRE | YEAR |
|---|---|---|---|---|
| зеленая книга | 8.324 | 137042 | комедия, драма, биография | 2018 |
| они никогда не станут старше | 8.227 | 1942 | документальный, военный, история | 2018 |
| фрисоло | 8.18 | 1291 | документальный, спорт | 2018 |
| хильда | 8.167 | 1678 | мультфильм, фэнтези, комедия | 2018 |
| капернаум | 8.146 | 12884 | драма | 2018 |
Аналогично создаём функцию для парсинга сайта IMDB (код в файле scraping_imdb.R)
Разница (DELTA) оценок считается вычитанием из рейтинга фильма на IMDB рейтинга фильма на Кинопоиске. Если DELTA больше нуля, оценка на IMDB выше, если меньше, то ниже.
# Загружаемые библиотеки
library(data.table)
library(tidyverse)
library(reshape)
library(ggthemes)
# Загрузка данных
kp <- fread("F:/dataset/movie/kinopoisk.csv")
imdb <- fread("F:/dataset/movie/imdb_db.csv")
# Удаление дубликатов
table <- imdb %>%
inner_join(kp, by = c("NAME", "YEAR"))
table2 <- table[which(duplicated(table$NAME)),]
table <- table %>%
anti_join(table2)
# Удаление фильма "Одержимость"
table <- table[-1704,]
# Переименование и удаление столбцов
table <- table %>%
rename_at(vars(ends_with(".x")), list(~str_c(str_extract(., "[A-Z]{1,}"), "_IMDB"))) %>%
rename_at(vars(ends_with(".y")), list(~str_c(str_extract(., "[A-Z]{1,}"), "_KP")))
# Округление рейтинга Кинопоиска до десятых и расчёт разницы в оценках
table <- table %>%
mutate(RATING_KP = round(RATING_KP, digits = 1)) %>%
mutate(DELTA = RATING_IMDB - RATING_KP)
# Гистограмма разницы оценок
gg <- ggplot(table, aes(x = DELTA)) +
geom_histogram(binwidth = 0.1,color = "black", fill = "gray60") +
labs(title = "Гистограмма разницы в оценках фильмов между Кинопоиском и IMDB",
caption = "Источник: kinopoisk.ru\nimdb.com") +
theme_tufte() +
theme(plot.title = element_text(hjust = 0.5, size = 9),
plot.caption = element_text(size = 7),
axis.title = element_text(size = 8),
axis.text = element_text(size = 6))
# t-test для оценок
t_table <- table %>%
select(RATING_IMDB, RATING_KP) %>%
melt(., variable_name = "site") %>%
mutate(site = as.factor(site))
t.test(t_table$value ~ t_table$site)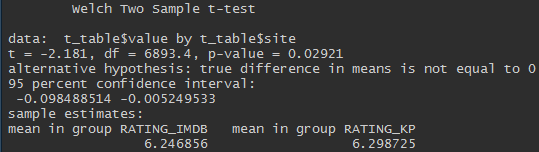
gg1 <- ggplot(table, aes(x = VOTES_KP, y = DELTA)) +
geom_point() +
labs(title = "Диаграмма рассеяния разницы в оценках\n в зависимости от числа голосов на Кинопоиске",
caption = "Источник: kinopoisk.ru\nimdb.com") +
theme_tufte() +
theme(plot.title = element_text(hjust = 0.5, size = 9),
plot.caption = element_text(size = 7),
axis.title = element_text(size = 8),
axis.text = element_text(size = 6))
# Сравнение оценок по жанрам фильма для жанров на Кинопоиске
# Удаление столбца GENRE_IMDB
table_genre <- table[,-4]
# Разделение столбца GENRE на три
table_genre <- table_genre %>%
separate(GENRE_KP, sep = ",", into = c("GENRE_1", "GENRE_2", "GENRE_3"))
table_genre <- setDT(table_genre)
# Преобразование данных в long таблицу
table_genre <- data.table::melt(table_genre, measure = patterns("^GENRE"),
value.name = "GENRE")
# Удаление строк с пропущенными значениями GENRE,
# подсчёт среднего рейтинга и количества упоминаний
table_genre <- table_genre %>%
mutate(GENRE = str_trim(GENRE, side = "both")) %>%
na.omit(.) %>%
group_by(GENRE) %>%
transmute(RATING = round(mean(RATING_KP), digits =1),
COUNT = n()) %>%
ungroup() %>%
unique() %>%
filter(COUNT > 150) %>%
mutate(GENRE = as.factor(GENRE))
# График срдней оценки Кинопоиска по жанрам фильмов
gg2 <- ggplot(table_genre, aes(x = RATING, y = GENRE, size = COUNT, colour = COUNT)) +
geom_point() +
scale_color_viridis_c() +
labs(title = "Средняя оценка фильмов по жанрам на Кинопоиске",
caption = "Источник: kinopoisk.ru") +
theme_tufte() +
theme(plot.title = element_text(hjust = 0.5, size = 9),
plot.caption = element_text(size = 7),
axis.title = element_text(size = 8),
axis.text = element_text(size = 6),
legend.key.size = unit(0.25, "cm"),
panel.grid = element_line(size = 0.3, colour = "grey60", linetype = "dotted"),
legend.text = element_text(size = 6),
legend.title = element_text(size = 7),
axis.ticks = element_blank())
# Сравнение оценок по жанрам фильма для жанров на IMDB
# Удаление столбца GENRE_KP
table_genre1 <- table[,-8]
# Разделение столбца GENRE на три
table_genre1 <- table_genre1 %>%
separate(GENRE_IMDB, sep = ",", into = c("GENRE_1", "GENRE_2", "GENRE_3"))
table_genre1 <- setDT(table_genre1)
# Преобразование данных в long таблицу
table_genre1 <- data.table::melt(table_genre1, measure = patterns("^GENRE"),
value.name = "GENRE")
# Удаление строк с пропущенными значениями GENRE,
# подсчёт среднего рейтинга и количества упоминаний
table_genre1 <- table_genre1 %>%
mutate(GENRE = str_trim(GENRE, side = "both")) %>%
na.omit(.) %>%
group_by(GENRE) %>%
transmute(RATING = round(mean(RATING_IMDB), digits =1),
COUNT = n()) %>%
ungroup() %>%
unique() %>%
filter(COUNT > 150) %>%
mutate(GENRE = as.factor(GENRE))
# График средней оценки Кинопоиска по жанрам фильмов
gg3 <- ggplot(table_genre1, aes(x = RATING, y = GENRE, size = COUNT, colour = COUNT)) +
geom_point() +
scale_color_viridis_c() +
labs(title = "Средняя оценка фильмов по жанрам на IMDB",
caption = "Источник: imdb.com") +
theme_tufte() +
theme(plot.title = element_text(hjust = 0.5, size = 9),
plot.caption = element_text(size = 7),
axis.title = element_text(size = 8),
axis.text = element_text(size = 6),
legend.key.size = unit(0.25, "cm"),
panel.grid = element_line(size = 0.3, colour = "grey60", linetype = "dotted"),
legend.text = element_text(size = 6),
legend.title = element_text(size = 7),
axis.ticks = element_blank())