Fast and most complete C++ library using parallel computing based on OpenCL. The map has a hexagon cells, which allows you to get the correct model view. All this makes it possible to use the library for high-level scientific works.
Required Packages:
CMake 2.8or higherGit
Dependencies:
OpenCL 1.2OpenCV 3[optional] (for build view and examples)
These steps have been tested for macOS Mojave 10.14 but should work with other unix-based systems as well.
1. $ cd ~/<my_working_directory>
2. $ git clone --branch v1.0 https://github.com/silkodenis/SOM.git
3. $ cd SOM
4. $ mkdir build
5. $ cd build## to build som, view and examples
6. $ cmake -D CMAKE_INSTALL_PREFIX=/usr/local ..
## to build only lib som
6. $ cmake -D CMAKE_INSTALL_PREFIX=/usr/local ../som7. $ make
8. $ make test
9. $ sudo make install9. $ sudo make uninstall## to generate XCode projects use:
6. $ cmake -G Xcode ..## to build dynamic libs, use option: [-D BUILD_SHARED_LIBS=true], for example:
6. $ cmake -D BUILD_SHARED_LIBS=true -D CMAKE_INSTALL_PREFIX=/usr/local ..Below is a brief overview of the examples, the source code of which gives a quick start to work with SOM.
Simple training
Hello world!


Real-time training
A simple example of how to training SOM and get a model view in real time.

Data approximation
A simple example of using one-dimensional SOM for data approximation.

Image as dataset
This example demonstrate using image as a data set. After receiving the clustered map from one image, we apply it to clustering another image.




Single channel analysis
A simple example of analyzing the channels of a trained map.


Deep analysis
This example demonstrates various model view interpretations of a trained map.
- Convolution maps, 3D(rgb) + 1D(v).

- Maps of accumulated distances during training.

- Maps from nodes that have been activated during training.

- Approximation maps. The temperature of the node indicates the frequency of activation during training.

- Single channel maps. These maps show how the resulting clusters depend on the components of the vectors used in training.

Debug training process
This example demonstrate dynamics of map error on the expiration of training epochs. It's important to timely stop training to avoid problem of overfitting. Observation of the convergence dynamics will help you to justify some learning parameters.

Save and load
A simple demonstration of saving and loading your model from a binary file.

Distance metrics can be very importance in the data analyzing using SOM. At the core of learning algorithm is activation(by computing distances from nodes weights to input vector) of the Best Matching Unit. BMU in turn will affect change the weights of its neighbors. The library provides 10 most popular distance metrics:
Definition:
![]()
Euclidean:
It is the natural distance in a geometric interpretation and is classic for many solution.

Minkowski:
Is the generalized Lp-norm of the difference. Can be considered as a generalization of both the Euclidean distance the case of p=2 and the Manhattan distance the case of p=1.

Chebyshev:
Minkowski distance with limiting case of p reaching infinity.

Manhattan(Taxicab):
Special case of the Minkowski distance with p=1 and equivalent to the sum of absolute difference. Also known as Taxicab norm, rectilinear distance or L1-norm. Used in regression analysis since the 18th century.
![]()
Canberra:
It is a weighted version of Manhattan distance. Is often used for data scattered around an origin, as it is biased for measures around the origin and very sensitive for values close to zero.
![]()
Cosine:
Represents the angular distance while ignoring space scale. Is most commonly used in high-dimensional positive spaces and also to measure cohesion within clusters in the field of data mining.
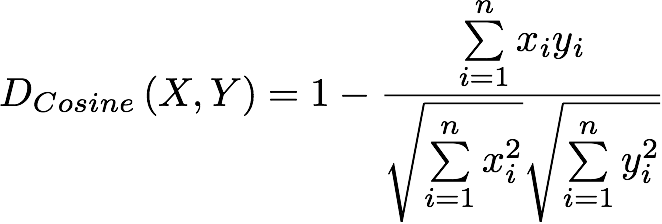
Sum of Absolute Difference(SAD):
Is equivalent to the L1-norm of the difference, also known as Manhattan or Taxicab-norm. The abs function makes this metric a bit complicated, but it is more robust than SSD.
![]()
Sum of Squared Difference(SSD):
Is equivalent to the squared L2-norm, also known as Euclidean norm. It is therefore also known as Squared Euclidean distance. Squares cause it to be very sensitive to large outliers. Is a standard approach in regression analysis.
![]()
Mean-Absolute Error(MAE):
Is a normalized version SAD.
![]()
Mean-Squared Error(MSE):
Is a normalized version SSD.
![]()
View has 20 most popular Matlab and Matplotlib equivalent colormaps.

The colormap have three parameters for adjustment (inversion, colors quantization and limits).

- Denis Silko - Initial work - silkodenis
Thanks to Amit Patel for help in implementing the efficient hexagonal grid.