-
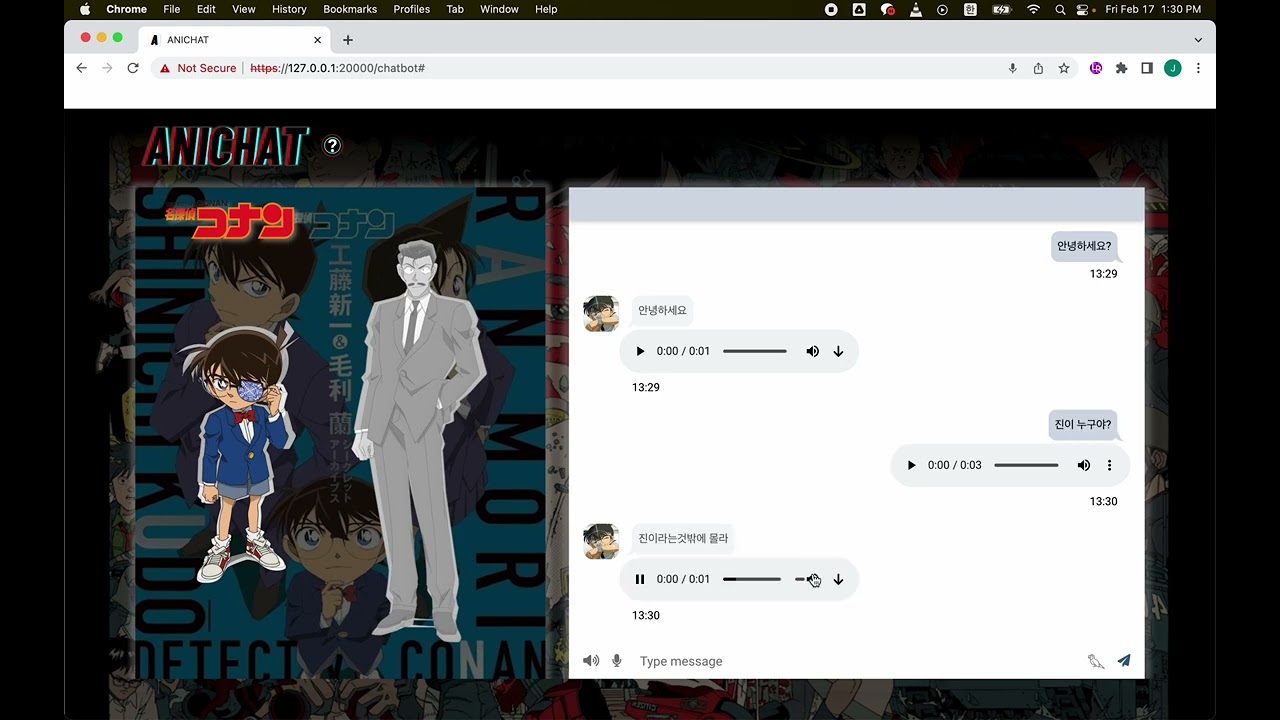
B2B Target Character Voice Chatbot Service
-
The feeling of learning the character's worldview, personality, voice, and tone of speech and having a real conversation with my favorite character.
-
Market Size


- Creation of a new content market attracts investment from companies and secures a new fan base
- Expandable to B2B industry
- Possibility of indirect experience that is closer to direct experience
- 전민정 (Leader)
- Overall project management
- In charge of TTS(Text-To-Speech)
- Model serving
- Web development
- Making data
- 이연교
- In charge of Chatbot
- Data examination
- Training models
- Making data
- 박영준
- In charge of TTS(Text-To-Speech)
- Making PPT
- Making data
- 이현중
- In charge of Chatbot
- Making PPT
- Web publishing
- Making data
- 곽형민
- Making data
- Search performance metrics
| Section | Date | Details | Note |
|---|---|---|---|
| Preliminary project | 01/03 ~ 01/15 | Planning a project, selecting a topic, and making a project proposal. | 01/09 1st reference sharing |
| Collecting Data and preprocessing | 01/03 ~ 01/27 | Collecting Data and preprocessing | 01/16 2nd reference sharing |
| Modeling | 01/11 ~ 02/06 | Designing and training model | |
| Build a service | 02/06 ~ 02/13 | Performance Improvements, Web Page Implementation, Model Serving and Rehearsing | |
| Total | 01/03 ~ 02/17 (7 weeks) |
- Use two characters voice of Japanese animation 'Detective Conan's korean dubbing' (Conan, Mori Kogoro)
- Collect voice and subtitle data from 27 animations that are approximately 90 ~ 110 minutes long
- Use the video editing program 'Vrew' to export only the utterance section to mp4(mp3), srt, and then split.
- Use spleeter to remove background sounds
- Converting Hangul into a phonemic symbol
- Final Data is as follows
| Section | Total | Conan | Mori Kogoro |
|---|---|---|---|
| Total Clips | 4,011 | 3,089 | 922 |
| Total Words | 25,205 | 18,868 | 6,337 |
| Total Characters | 94,404 | 70,837 | 23,567 |
| Mean Words per Clip | 6.28 | 6.11 | 6.87 |
| Distinct Words | 11,351 | 8,790 | 3,955 |
| Total Duration | 227.6 min | 169.2 min | 58.4 min |
| Mean Clip Duration | 3.405 sec | 3.287 sec | 3.801 sec |
| Min Clip Duration | 0.23 sec | 0.23 sec | 0.42 sec |
| Max Clip Duration | 14.29 sec | 14.29 sec | 12.06 sec |
- Train, Validation set
| Set | Conan | Mori Kogoro |
|---|---|---|
| train | 3,089 | 872 |
| val | 50 | 50 |
- Create chatbot data while watching animations or reviews.
- Up to 4 questions of a similar type per answer 1,926 answers + 7,657 questions
- Train : Validation = 8 : 2
- Train data set = Question and answer consists of correct or not / Answer: Incorrect = 1:15
- Validation data set = Question and answer consists of correct answer / Answer: Incorrect = 1:63
We didn't training STT. we just use whisper. added it to our pipeline. so no data.


- Fully End-To-End TTS Model that generates audio when you enter text
- Text-To-Speech Synthesis SOTA rank 2 which use LJSpeech DataSet from Papers with Code (2023.02.21)

because vits source code is for english so we add korean cleaner from here and add symbols. so we had to modify vits/text/symbols.py and we use korean and IPA, so there is several things to add alphabet.
- Retrieval-Based Model
- Faster than Cross Encoder, more accurate than Bi-encoder
- A real-time automatic voice recognition/translation open source system that learns 680,000 hours of multilingual and multi-business data collected from the web.
-
Batch Size: 16
-
Epoch: 3677(single, conan, 711000 step), 12581(single, mori kogoro, 390000 steps), 18471(multi, 1570000 steps)
-
Single Speaker Conan

-
Single Speaker Mori Kogoro

-
Multi Speaker

- We use pretrained Poly-Encoder model trained by Korean Benchmark Data, KLUE(Korean Language Understanding Evaluation)
- Reconfigure Poly-Encoder by changing to KLUE-RoBERTa-base with similar performance but faster convergence than KLUE-BERT-base
- Batch Size: 32
- Maximum Question Length : 256
- Maximum Answer Length : 256
- Epoch: 100
- Learning Rate: 5e-5
- Leave room at the beginning and end of sentences when cutting speech into sentences so that you can learn spacing well
- Add more data with additional noise cancellation
- Additional refinement by setting maximum and minimum voice lengths
- Use KorEDA(Korea Easy Data Augmentation)
- RS: A가 B를 왜 죽였어 -> A가 왜 죽였어 B를
- Back translation using google translator
- Korean -> English -> Korean
- Unused due to too much noise
- Use special token
- The KLUE tokenizer vocab dictionary consists of common words used in Korea.
- In the case of animation, there are many words that are used only in the animation world.
- The characters, regional names in the animation world, and words that are key keywords are judged to be enough information to be provided by the animation production company, so the words are designated as special token.
-
MOS (Mean Opinion Score)
- Originally, it was a method of listening and measuring directly by human MOS ratings, but it was measured with a model learned by human MOS ratings.
- Out of five.
-
MCD (mel-cepstral distortion)
- It is an indicator that measures the difference between the mel-keptrum between the original and synthetic voices, and the unit is dB.
- Measure the difference between the two sequences of mel cepstral
- The lower the number, the better.
| MOS | MCD | |
| Baseline - Conan | 3.02 | - |
| Baseline - Mori | 2.85 | - |
| Single speaker - Conan | 2.24 | 6.00 |
| Single speaker - Mori | 1.51 | 5.54 |
| Multi Speaker - Conan | 2.03 | 17.90 |
| Multi Speaker - Mori | 1.87 | 5.40 |
| Handling | KLUE/bert-base | KLUE/roberta-base | ||||
| poly_m | 16 | 16 | 16 | 16 | 8 | 8 |
| Use Augmentation | X | O | X | O | X | O |
| Accuracy | 0.5662 | 0.4259 | 0.6861 | 0.6228 | 0.5418 | 0.6934 |
- It's a problem that words that don't appear a lot due to little data can't pronounce well.
- Incomplete due to insufficient data count
- Unable to put in hard voting during demonstration due to multiprocessing is not possible due to resource problems.
- Add data to eliminate data imbalances and complete natural pronunciation
- Support for a wide range of animated characters
- Multilingual support
- Implementing chatbot voting function through multiprocessing configuration
- IDE(Integrated Development Environment) : Visual Studio Code
- VCS(Version Control System) : Git
- Specification Sheet :

- split-video-with-srt.py : using pysrt library, spliting one video to several videos using srt file's timestamps.
python split-video-with-srt.py -i [mp4 file] -if [srt file] -o [save folder]-
make-dataset.py : this file makes text file for vits model training. you can make text file for single or multispeakers. but you need to use vits/preprocessing.py to make .txt.cleaned file. that is real text file used by model.
-
text-augmentation.py : for chatbot model, we generated texts but we think it is not enough for model. so we find some text augmentation techniques from here. and we want to use the RD from this paper. but we think random deletion is kind of risky in our data so we made adv deletion. because our language is korean so we use konlpy mecab for pos tagging.
-
text2speech2text.py : because we have to load several models and use them, we have to test. it is test python file for using 3 models in same environment.
- Kim, Jaehyeon, Jungil Kong, and Juhee Son. "Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech." International Conference on Machine Learning. PMLR, 2021.
- MLAHumeau, Samuel, et al. "Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring." arXiv preprint arXiv:1905.01969 (2019).
- Radford, Alec, et al. "Robust speech recognition via large-scale weak supervision." arXiv preprint arXiv:2212.04356 (2022).