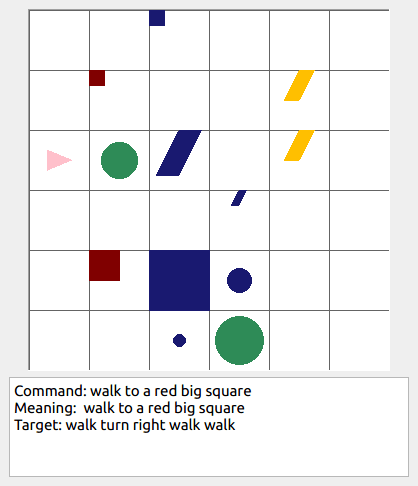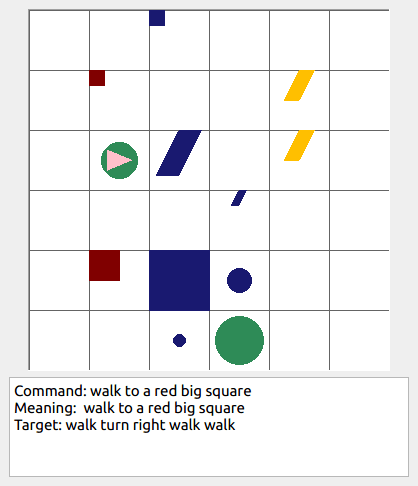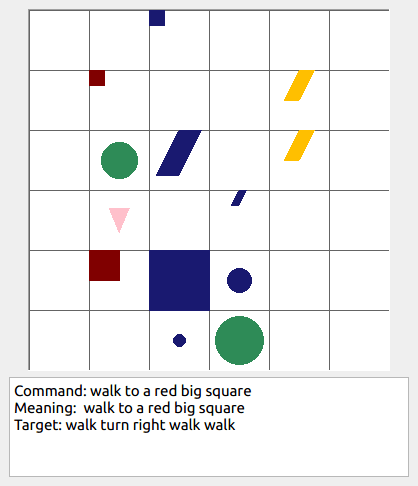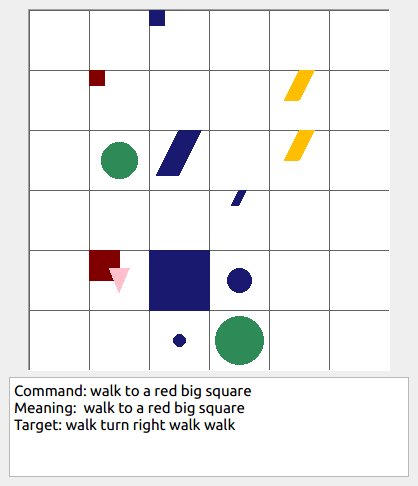
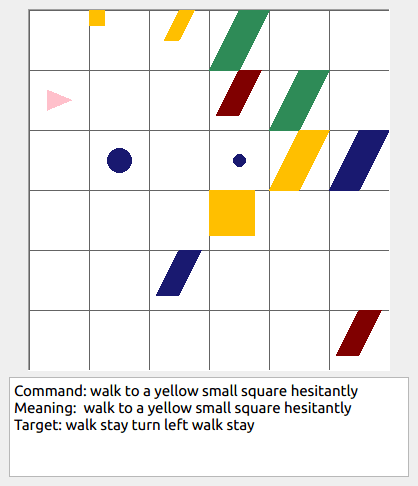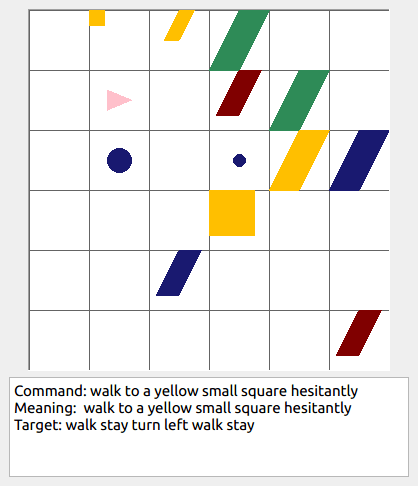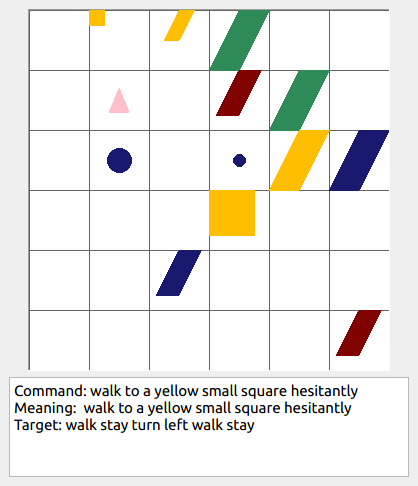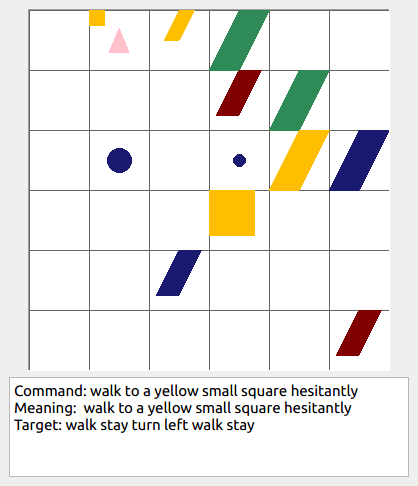
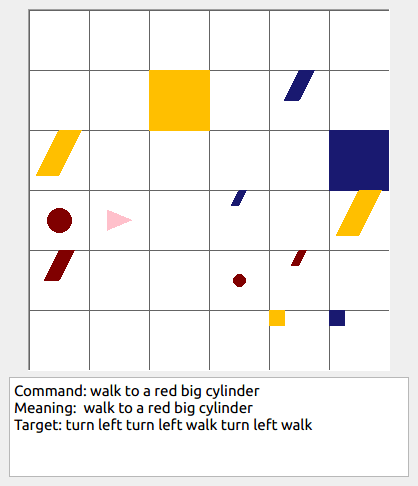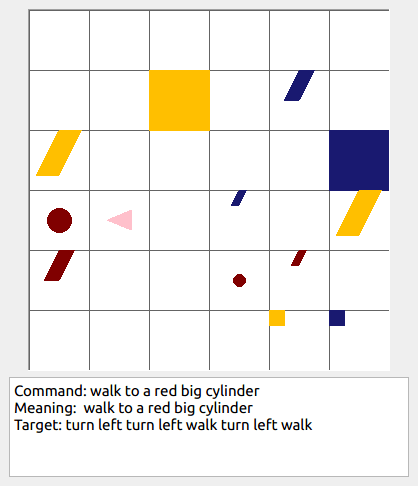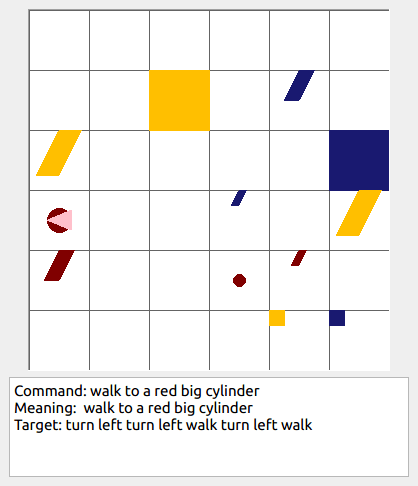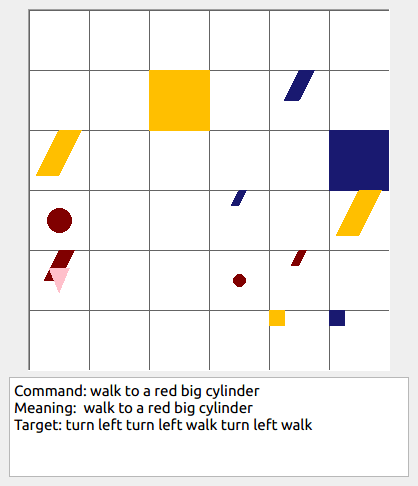
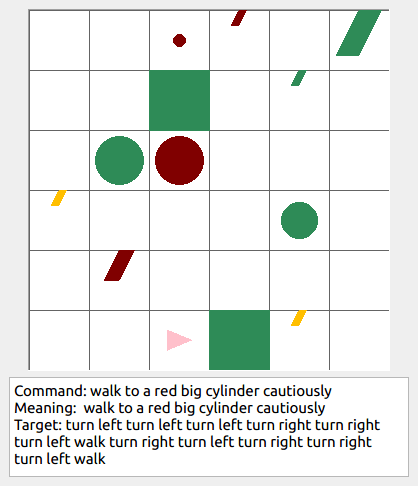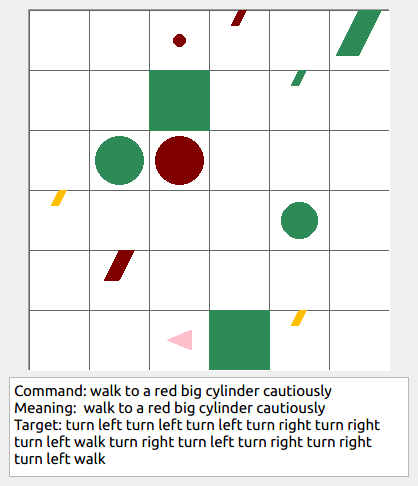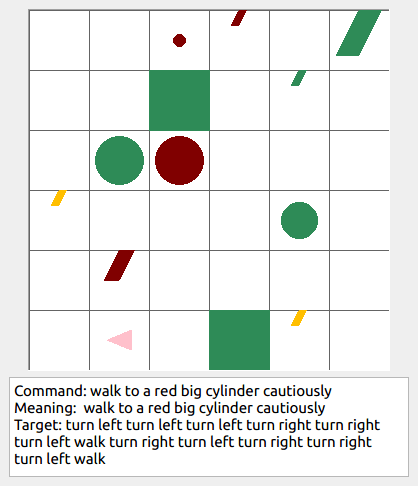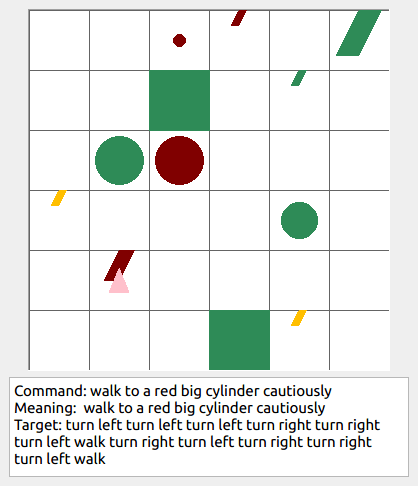
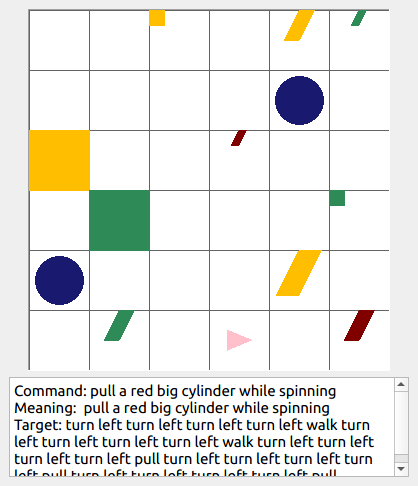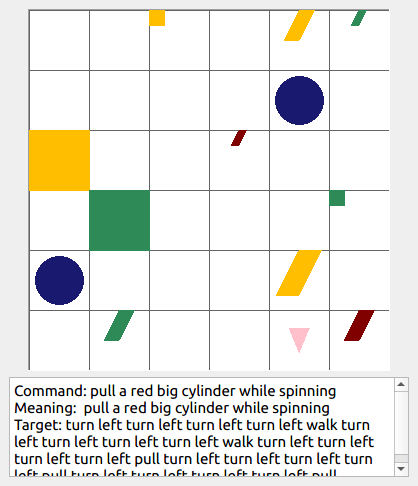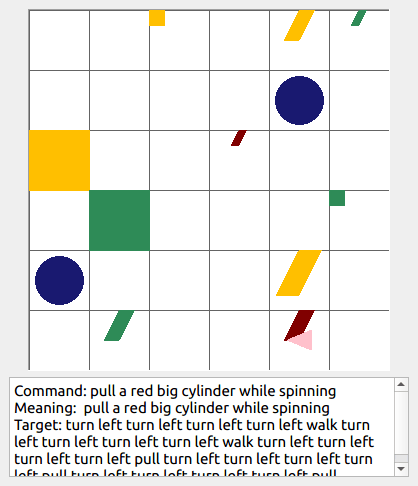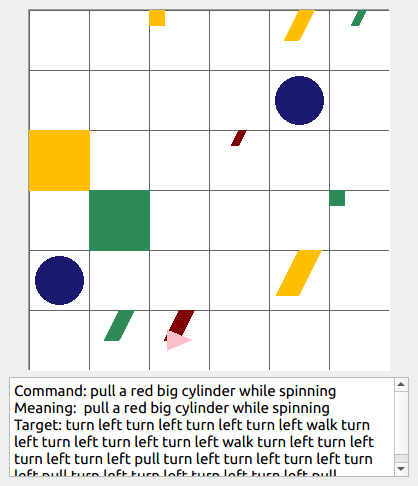
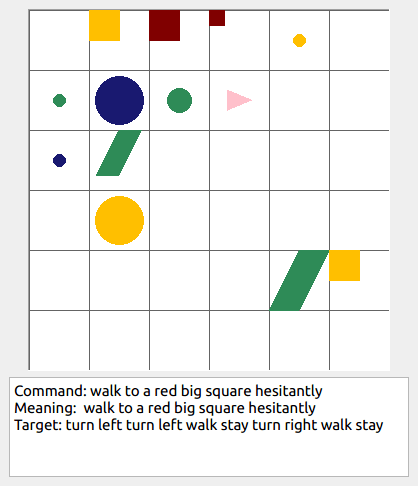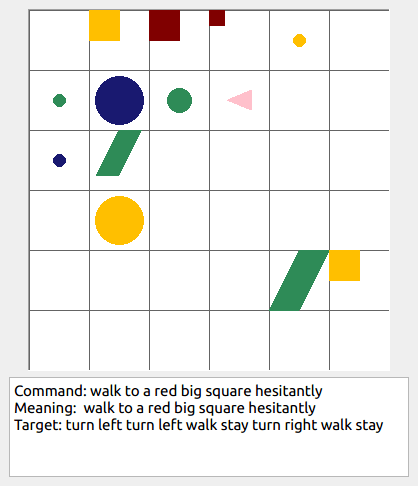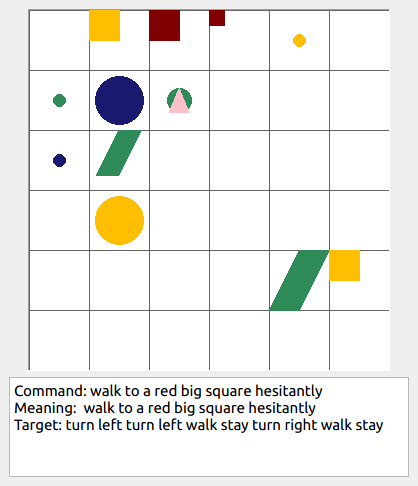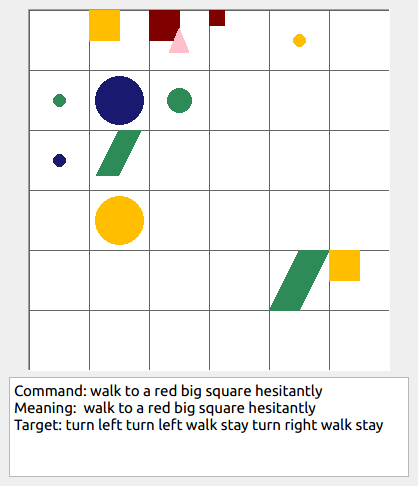
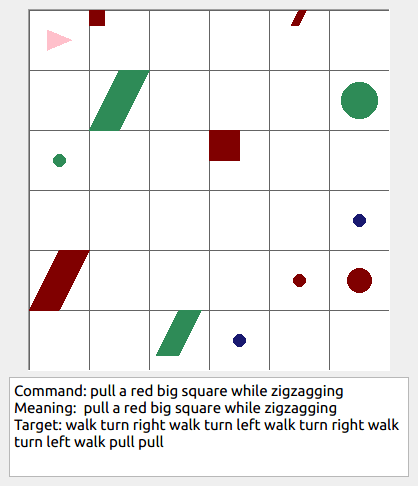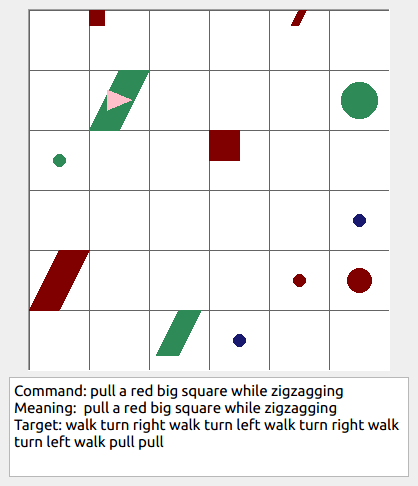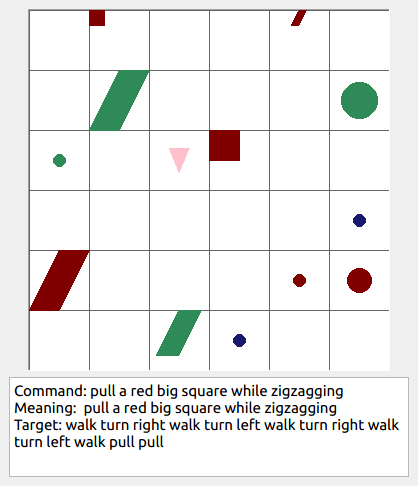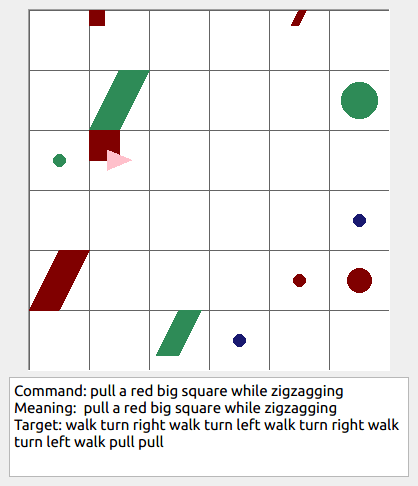
This repository contains the code for generating the grounded SCAN benchmark. Grounded SCAN poses a simple task, where an agent must execute action sequences based on a synthetic language instruction.
The agent is presented with a simple grid world containing a collection of objects, each of which is associated with a vector of features. The agent is evaluated on its ability to follow one or more instructions in this environment. Some instructions require interaction with particular kinds of objects.
NB: for reinforcement learning mode see branch rlmode. Please note that the full reward function including interactions and manners has not been tested with a learned policy yet.
The data used in the grounded SCAN paper can be found in the folder data of this repository. This data can be used to train models with the multi-modal baseline from the paper. The exact match accuracies reported in the paper can then be reproduced with the mode error_analysis in this repository.
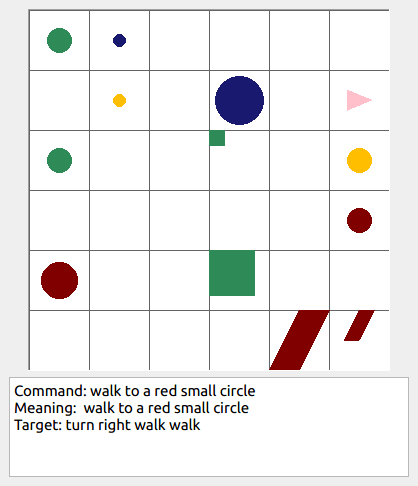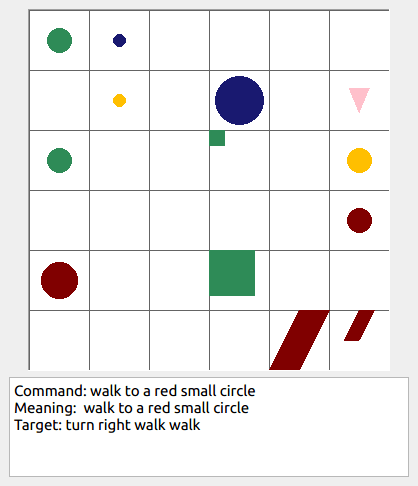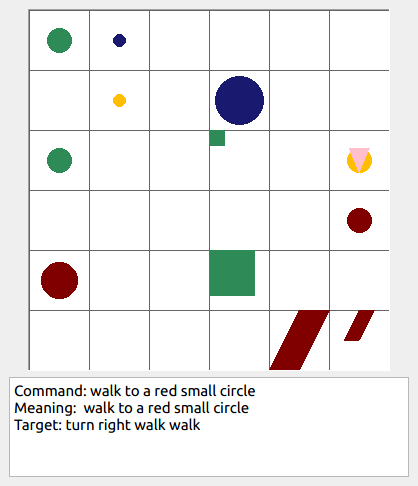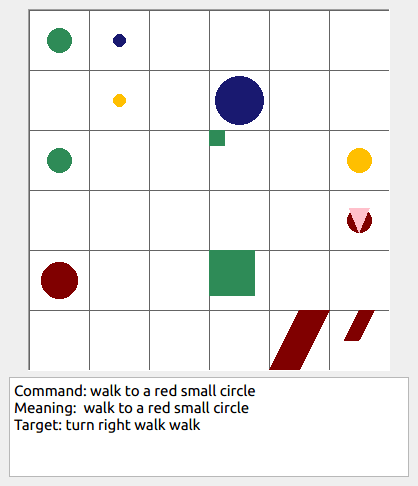
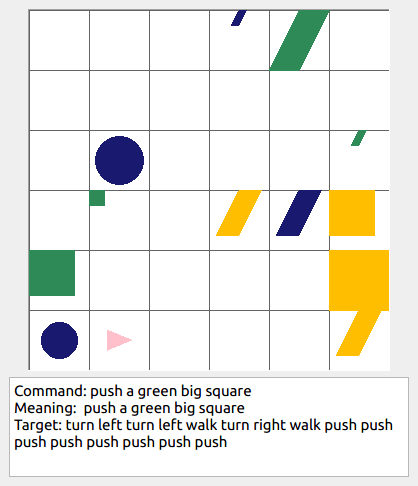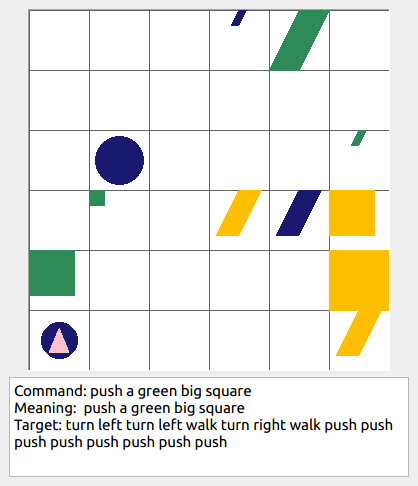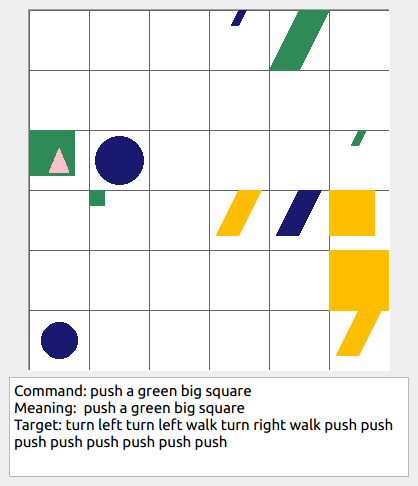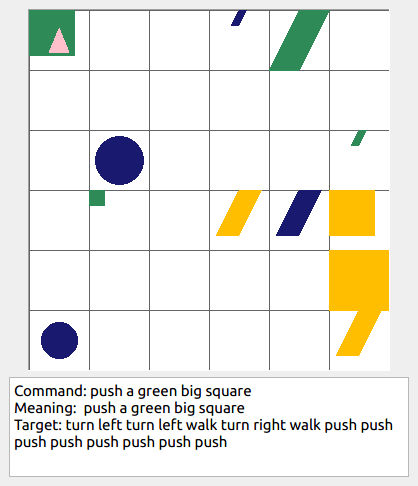
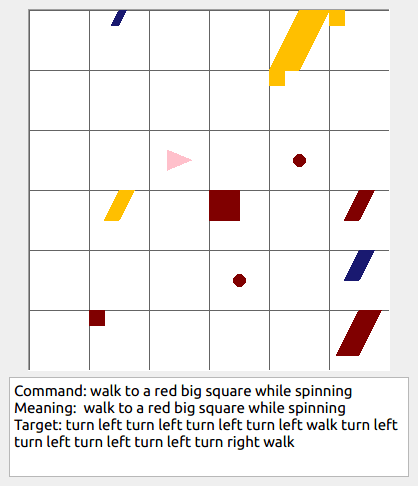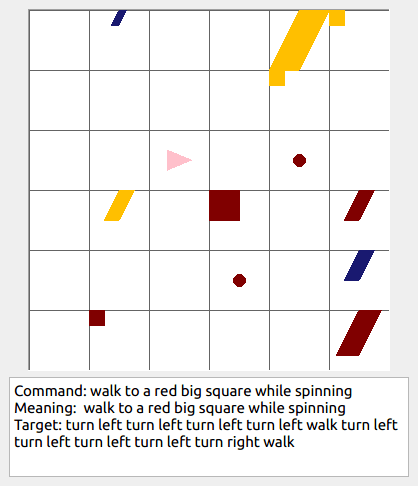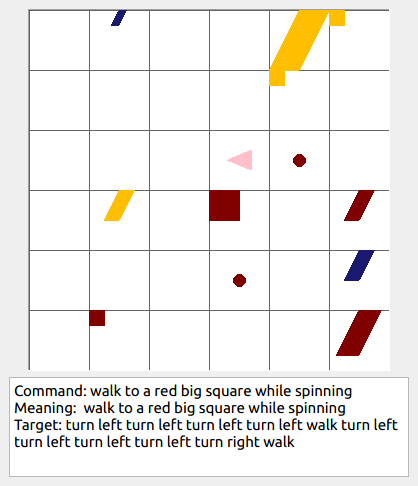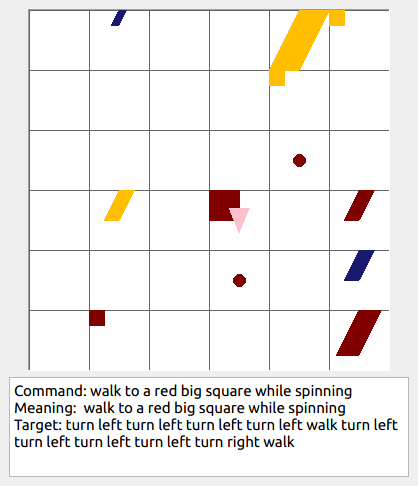
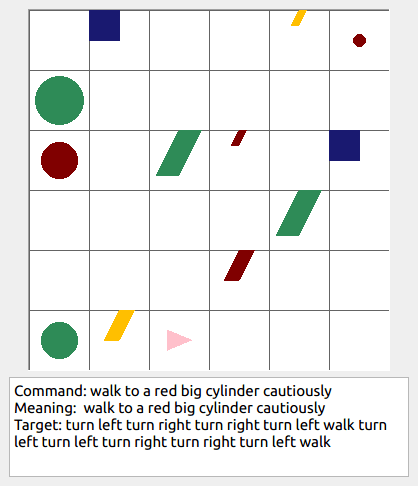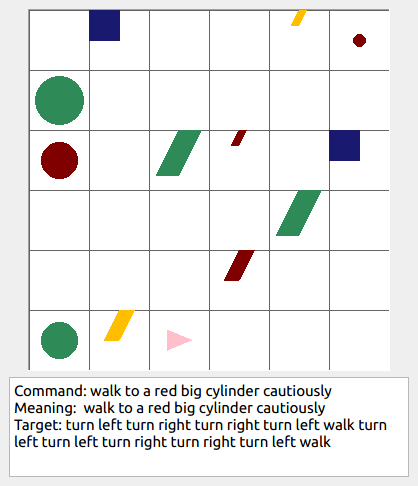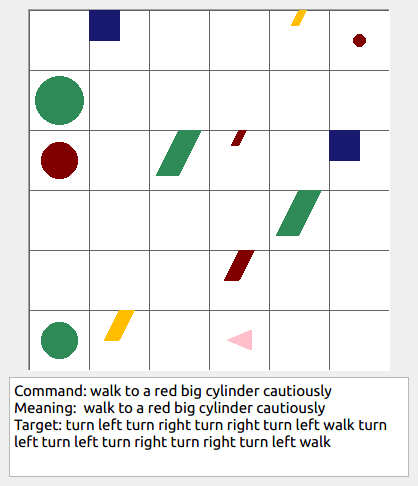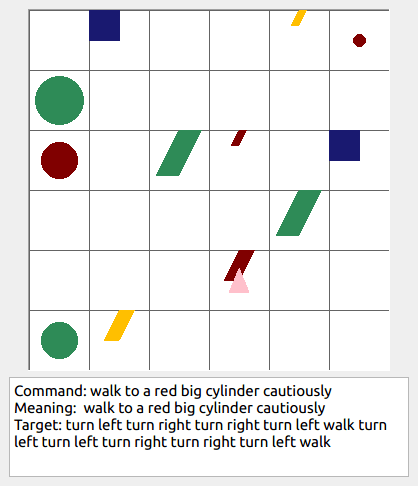
Some data examples (more at bottom of this file, and a demo dataset can be found in data/demo_dataset/.):
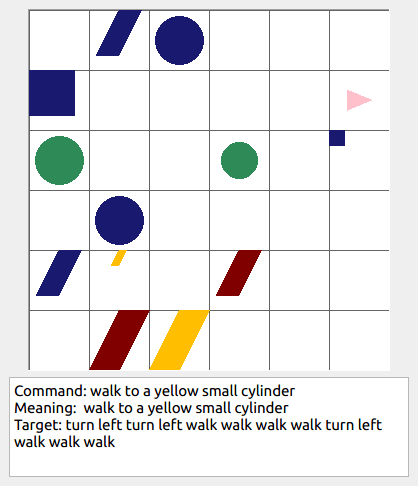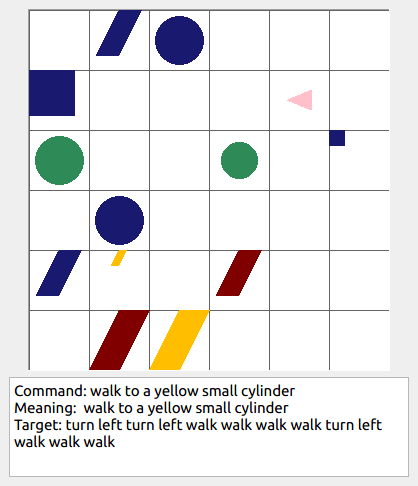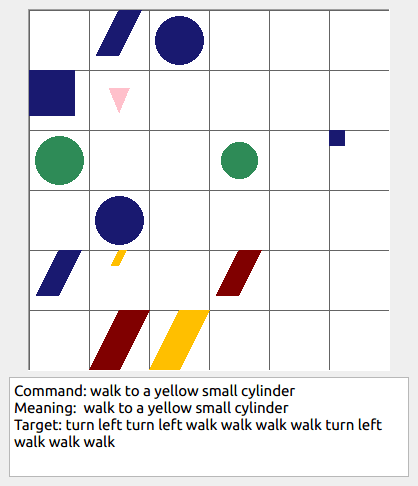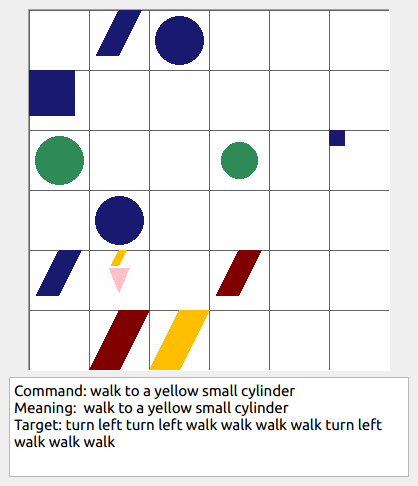
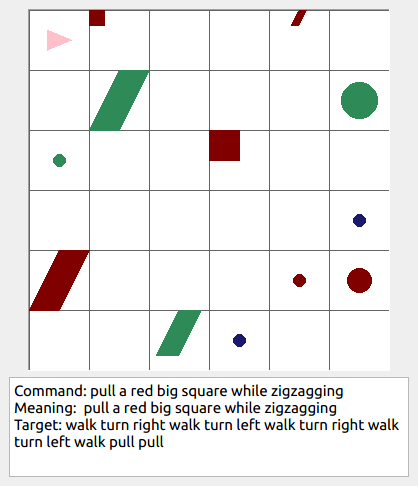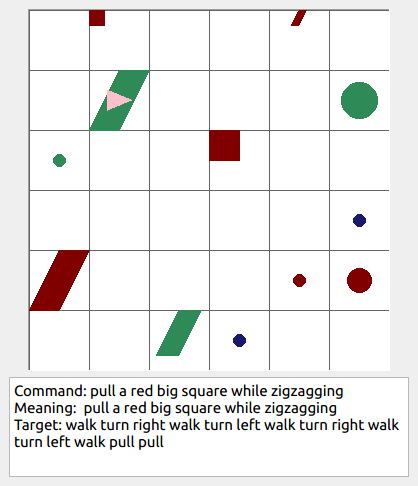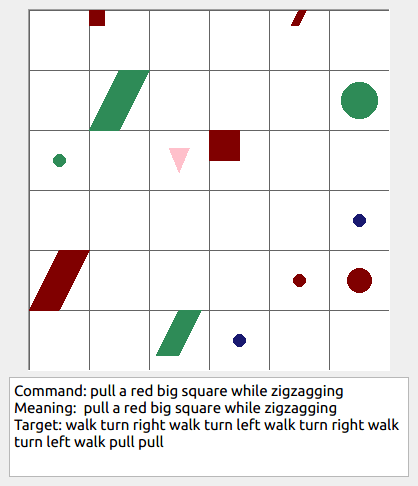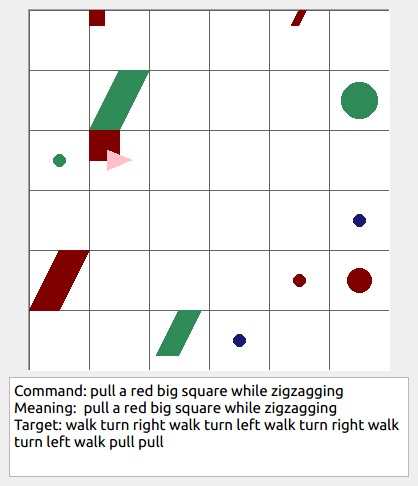
This section contains the leaderboard for scores obtained by papers on gSCAN. To add scores please consider a pull request.
| Baseline | GECA | [1] | [2] | [3] | [4] | [5] | [6] | |
|---|---|---|---|---|---|---|---|---|
| A: Random | 97.69 +- 0.22 | 87.6 +- 1.19 | 97.32 | 94.19 +- 0.71 | 98.6 +- 0.95 | - | 74.7 | 99.95 +/- 0.02 |
| B: Yellow Squares | 54.96 +- 39.39 | 34.92 +- 39.30 | 95.35 | 87.31 +- 4.38 | 99.08 +- 0.69 | - | 81.3 | 99.90 +/- 0.06 |
| C: Red Squares | 23.51 +- 21.82 | 78.77 +- 6.63 | 80.16 | 81.07 +- 10.12 | 80.31 +- 24.51 | - | 78.1 | 99.25 +/- 0.91 |
| D: Novel Direction | 0.00 +- 0.00 | 0.00 +- 0.00 | 5.73 | - | 0.16 +- 0.12 | - | 0 | 0.0 +/- 0.0 |
| E: Relativity | 35.02 +- 2.35 | 33.19 +- 3.69 | 75.19 | 52.8 +- 9.96 | 87.32 +- 27.38 | - | 53.6 | 99.02 +/- 1.16 |
| F: Class Inference | 92.52 +- 6.75 | 85.99 +- 0.85 | 98.63 | - | 99.33 +- 0.46 | - | 76.2 | 99.98 +/- 0.01 |
| G: Adverb k=1 | 0.00 +- 0.00 | 0.00 +- 0.00 | 11.94 | - | - | - | 0.0 | 0.00 +/- 0.00 |
| G: Adverb k=5 | 0.47 +- 0.14 | - | 10.31 | - | - | - | - | - |
| G: Adverb k=10 | 2.04 +- 0.95 | - | 33.28 | - | - | 4.87 | 4.87 | - |
| G: Adverb k=50 | 4.63 +- 2.08 | - | 40.78 | - | - | - | - | - |
| H: Adverb to Verb | 22.70 +- 4.59 | 11.83 +- 0.31 | 21.95 | - | 33.6 +- 20.81 | 28.03 | 21.8 | 22.16 +/- 0.01 |
| I: Length | 2.10 +- 0.05 | - | - | - | - | - |
[1] Yen-Ling Kuo, Boris Katz, and Andrei Barbu. 2020. "Compositional networks enable systematic generalization for grounded language understanding."
[2] Christina Heinze-Deml and Diane Bouchacourt. 2020. "Think before you act: A simple baseline for compositional generalization." in EMNLP 2020
[3] Tong Gao, Qi Huang, Raymond J. Mooney. 2020. "Systematic Generalization on gSCAN with Language Conditioned Embedding" in AACL-IJCNLP 2020.
[4] Yichen Jiang and Mohit Bansal. 2021. "Inducing Transformer’s Compositional Generalization Ability via Auxiliary Sequence Prediction Tasks"
[5] Maxwell Nye, Michael Henry Tessler, Joshua B. Tenenbaum, Brenden M. Lake. 2021. "Improving Coherence and Consistency in Neural Sequence Models with Dual-System, Neuro-Symbolic Reasoning"
[6] Linlu Qui, Hexiang Hu, Bowen Zhang, Peter Shaw, Fei Sha. 2020. "Systematic Generalization on gSCAN: What is Nearly Solved and What is Next?"
All data used in the paper can be found in compressed folders in data.
To see how to read this data for a computational model and train models on it please refer to this repository. Here the code for data generation, error analysis, and visualizing examples lives.
Find a term glossary in documentation/glossary.md.
Make a virtualenvironment that uses Python 3.7 or higher:
>> virtualenv --python=/usr/bin/python3.7 <path/to/virtualenv>
Activate the environment and install the requirements with a package manager:
>> { source <path/to/virtualenv>/bin/activate; python3.7 -m pip install -r requirements; }
Make sure all tests run correctly:
(virtualenv) >> python3.7 -m GroundedScan --mode=test
In the folder data/demo_dataset a very small example dataset can be found that can be inspected to get a feel for the data. It contains an example of the compositional generalization splits you could create with a simple intransitive grammar (i.e., without size modifiers, adverbs, or transitive verbs), with a grid size of 4, and only 2 shapes. When taking a look in the folder, one can also see all the extra statistics and plots that are generated when generating a benchmark dataset. The actual data that can be used for training computational models can be found in dataset.txt. To see a summary of the statistics of each data split in dataset.txt, inspect the separate split text files named <split>_dataset_stats.txt (e.g., train_dataset_stats.txt). This demo dataset is generated by the following command:
>> python3.7 -m GroundedScan --mode=generate --output_directory=data/dummy_dataset --num_resampling=1 --grid_size=4 --type_grammar=simple_intrans --nouns=circle,square --percentage_dev=0.1 --make_dev_set
See an demonstration of training a multi-modal neural model on this demo dataset here.
To generate data for the compositional generalization splits:
(virtualenv) >> python3.7 -m GroundedScan --mode=generate --output_directory=compositional_splits --type_grammar=adverb --split=generalization
in a directory containing the folder GroundedScan. This will generate a dataset in the folder compositional_splits.
The dataset will be in compositional_splits/dataset.txt and for each split there will be an associated compositional_splits/<split>_stats.txt
and plots visualizing the statistics of the data in that particular split (e.g. the number of examples totally, broken down per grid location, per referred target, etc.).
For an example dataset see the folder data/compositional_splits.zip, containing the data used for the paper.
grid_sizespecifies the number of columns and rows in the world. If set higher, more examples will be generated and the maximum target length will be higher.num_resamplingthis determines how often you want to resample an example with the same specifications in terms of input instruction, target referrent, and relative position of the agent versus the target. If set to higher than 1, the code samples new random agent and target locations that still satisfy the constraints. Like setting a higher grid size, this parameter can also be used to generate more data.splitdetermines for which splits we are generating data. Can be set to uniform (i.e. no systematic difference between training and test), generalization (i.e. the compositional generalization splits), or target_lengths (i.e. generalizing to larger target lengths). For this latter split make sure to also setcut_off_target_lengthvisualize_per_templateis an integer determining how many gifs to make per template example (see glossary.md for explanation of template).type_grammarif set toadverbjust gives the fully implemented grammar from the paper, but you can also set it tonormalto exclude adverbs, or tosimple_intransandsimple_transto use only intransitive or transitive verbs respectively.
To do an error analysis over a predictions file generated by a model trained on the data, run:
(virtualenv) >> python3.7 -m GroundedScan --mode=error_analysis --output_directory=error_analysis --load_dataset_from=compositional_splits/dataset.txt --predicted_commands_file=predict.json
The predicted commands file must be a file generated with a trained model in test mode in the provided model code. The file example_prediction.json contains 1 data example with a prediction that can be used for trying out the error analysis and execute commands modes. The error analysis will generate plots in
the output directory specified, as well as a .txt and .csv file summarizing all the results for own anaylsis.
The .csv outputs were used in the paper.
NB: this mode is used to get the exact match accuracies reported in the paper.
To make gifs of predictions use the mode execute_commands:
(virtualenv) >> python3.7 -m GroundedScan --mode=execute_commands --load_dataset_from=compositional_splits/dataset.txt --output_directory=visualized_examples
--predicted_commands_file=predict.json
This will visualize the predictions in predict.json that should be placed in the folder specified by --output_directory and visualize the execution in a gif in the specified output directory. NB: this will make one gif (including as many images as there are time-steps in that prediction) for each data point in predict.json. If you want to only inspect the errors, set --only_save_errors. The file example_prediction.json contains 1 data example with a prediction that can be used for trying out the error analysis and execute commands modes.
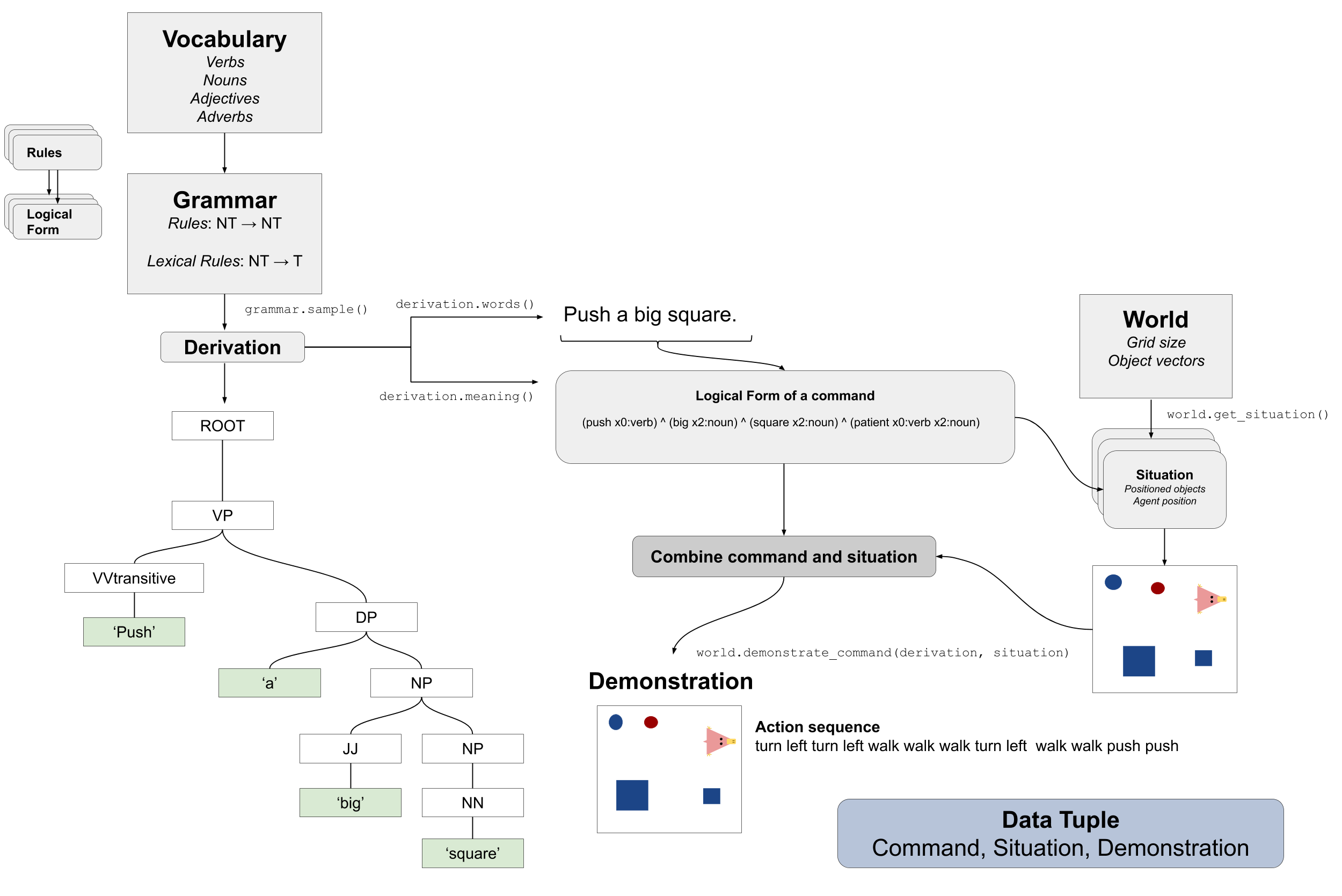
We
construct a Grammar that produces transitive and intransitive sentences (with
a depth-limited recursive operation for introducing adjectives and adverbs). Sentences are of the form
((Adverb* Verb (Adjective* Noun)?)+
It is possible to sample from a Grammar to obtain paired sentences
(sequences of tokens) and meanings (hacky neo-Davidsonian logical forms). For
example, the sentence
push a big square
gets associated with the logical form
lambda $v1. exists $n. push($v1) and patient($v1, $n) and big($n) and
square($n)
represented in the code by
(push x0:verb) ^ (big x2:noun) ^ (square x2:noun) ^ (patient x0:verb x2:noun)
In order to pair instructions with demonstrations, we need to map from meanings to sequences of low-level environment actions.
The example logical form depicted above specifies one action: a square-pushing
action. It must be performed in a grounded context. In
this library, computations associated with grounding live in world.py. The
grounded context for a specific instruction is represented by a Situation.
Situations are generated from Worlds. A situation is what is used for one example to specify all the important information
to generate a visualization as well as input grid world for a computational model. The function to visualize a current situation in
an RGB image is World.get_current_situation_image() in world.py and to get the simplified input to a model (see paper Section 3 (World Model) for explanation)
run the function World.get_current_situation_grid_repr(). This is all done automatically when generating the data.
Important semantics:
walk: means walking somewhere with action commandwalk, and for navigationturn leftandturn right.push: means pushing an object to the front of the agent until it hits a wall or another object, to move it 1 grid cell takes 1pushaction if the object is of size 1 or 2, and 2 push actionspush pushif it is of size 3 or 4.pull: means pulling an object to the back of the agent until it hits a wall or another object, withpull-actions, again needing 1 action for light objects (size 1 and 2), and 2 for heavy ones (size 3 and 4).while spinning: generate a sequence ofturn left turn left turn left turn left(i.e. one spin) every time before executing the actions to move a grid cell.cautiously: generate a sequence ofturn right turn left turn left turn right(i.e. look to the right and left) each time before you move over a grid line (note the distinction with when to execute the sequence from while spinning, see examples at bottom of this page for clarification).hesitantly: generate a action command tostayevery time after moving a grid cell.while zigzagging: instead of walking all the way horizontally first and then vertically, alternate between horizontal and vertical until in line with the target, from then go straight.
For a schematic depiction of how exactly the code is setup see the following image:
After instructions have been generated, we construct various held-out sets
designed to test different notions of compositional generalization. This is done in the class method GroundedScan.assign_splits()
in GroundedScan/dataset.py
object properties
- visual: all examples where red squares are the target object.
- visual_easier: all examples where yellow squares are referred to with a color and a shape at least.
situational:
- situational_1: all examples where the target object is to the South-West of the agent.
- situational_2: all examples where the target object is a circle of size 2 and is being referred to with the small modifier.
contextual
- contextual: all examples where the agent needs to push a square of size 3.
adverb:
- adverb_1: all examples with the adverb 'cautiously', of which we randomly select k to go in the training set.
- adverb_2: all examples with the adverb 'while spinning' and the verb 'pull'.
target_lengths
- target_lengths: all examples with a target length above
--cut_off_target_length