A pretrained Korean-specific Sentence-BERT model (Reimers and Gurevych 2019) developed by Computational Linguistics Lab at Seoul National University.
We recommend Python 3.6 or higher and sentence-transformers v2.2.0 or higher.
>>> from sentence_transformers import SentenceTransformer, util
>>> model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
>>> sentences = ['잠이 옵니다', '졸음이 옵니다', '기차가 옵니다']
>>> vectors = model.encode(sentences) # encode sentences into vectors
>>> similarities = util.cos_sim(vectors, vectors) # compute similarity between sentence vectors
>>> print(similarities)
tensor([[1.0000, 0.6577, 0.2732],
[0.6577, 1.0000, 0.2730],
[0.2732, 0.2730, 1.0000]])You can see the sentence '잠이 옵니다' is more similar to '졸음이 옵니다' (cosine similarity 0.65774536) than '기차가 옵니다' (cosine similarity 0.27321893).
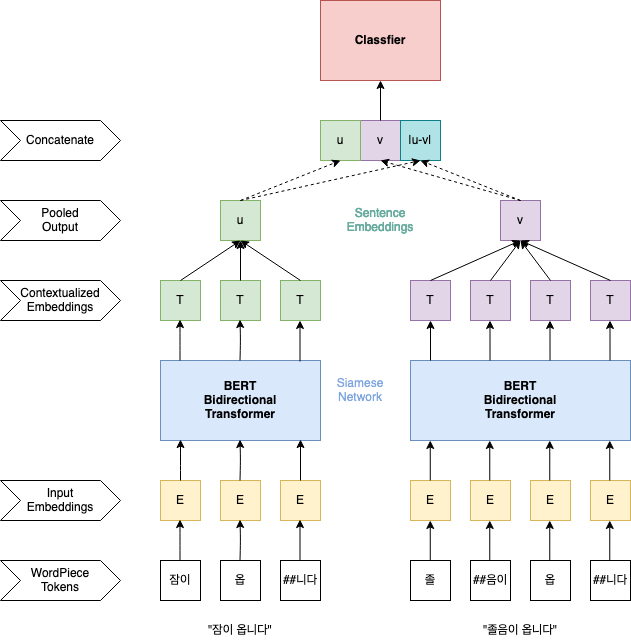
Using a pre-trained BERT model, a sentence is segmented into WordPiece tokens, of which contextualized output vectors are mean-pooled into a single sentence vector. We use KR-BERT-V40K, a variant of KR-BERT.
Two sentence vectors are fed into a classifier for fine-tuning. Then, a siamese network trains the BERT weight parameters to reflect the relation between the two sentences. Finally, we fine-tune the SBERT model on the KLUE-NLI dataset and the augmented KorSTS dataset.
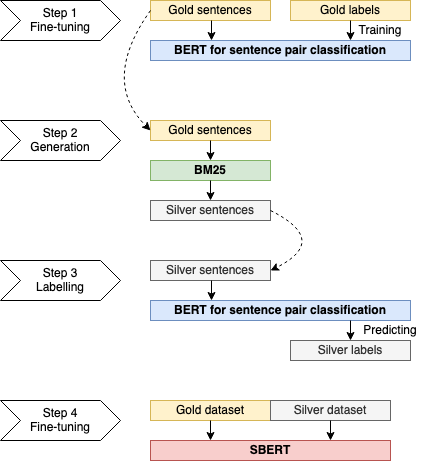
We augment the KorSTS dataset using the in-domain straregy proposed by Thakur et al. (2021).
from sentence_transformers import SentenceTransformer, util
import pandas as pd
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
data = pd.read_csv('path/to/the/dataset')
vec1 = model.encode(data['sent1'], show_progress_bar=True, batch_size=32)
vec2 = model.encode(data['sent2'], show_progress_bar=True, batch_size=32)
data['similarity'] = [
util.cos_sim(sent1, sent2).squeeze()
for sent1, sent2 in tqdm(zip(vec1, vec2), total=len(data))
]
data[['paraphrase', 'similarity']].to_csv('paraphrase-results.csv')Tutorial in Google Colab: https://colab.research.google.com/drive/1S6WSjOx9h6Wh_rX1Z2UXwx9i_uHLlOiM
| Model | Accuracy |
|---|---|
| KR-SBERT-Medium-NLI-STS | 0.8400 |
| KR-SBERT-V40K-NLI-STS | 0.8400 |
| KR-SBERT-V40K-NLI-augSTS | 0.8511 |
| KR-SBERT-V40K-klueNLI-augSTS | 0.8628 |
sentence_transformers(https://github.com/UKPLab/sentence-transformers)
@misc{kr-sbert,
author = {Park, Suzi and Hyopil Shin},
title = {KR-SBERT: A Pre-trained Korean-specific Sentence-BERT model},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/snunlp/KR-SBERT}}
}