
Artificially intelligent machines are becoming smarter in every day. Deep learning and machine learning techniques enable machines to perform many tasks at the human level. In some cases, they even surpass human abilities. Machine intelligence can analyze big data faster and more accurately than a human possibly can. Even though they cannot think yet, they see, sometimes better than humans (read our computer vision and machine vision articles), they can speak, and they are also good listeners. Known as “automatic speech recognition” (ASR), “computer speech recognition”, or just “speech to text” (STT) enables computers to understand spoken human language.
Note:Speech recognition and speaker recognition are different terms. While speech recognition is to understand what is told, speaker recognition is to know the speaker instead of understanding the context of the speech that can be used for security measures. These two terms are confusing and voice recognition is often used for both.
This is END TO END model, given audio data that convert Analog-to-Digital using (ADC) converter, then extract features form audio using some Signinal-Processing algorithms like Sort-Time-Fourier-Transform(STFT), Then using some Deep-Learning based techniques (like CNN's, LSTM's and GRU's) convert audio features into text representation
Some articles and reference blogs about ths problem statement
We are referred to some research papers and open source projects/repositories maintained below
- Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
- Jasper: An End-to-End Convolutional Neural Acoustic Model
- Listen,Attend and Spell
Our objective is to build End-To-End Speech Recognition System using existing research and Try verious architectures, Then find out which one works better for us.
- Latency: Given a audio (.wav) file the model predict Text what's spoken in that audio file, depending on application what you are using latency important
- Interpretability: As long as the speaker has spoken he/she wanted to check what are they spoken, they don't what to know how the model predicting that, so in this case, interpretability not importent.
- Word Error Rate: Word error rate (WER) is a common metric of the performance of a speech recognition or machine translation system. The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one).
Our goal is to train best model that gives low Word Error Rate(WER)
We want to use some open-source datasets, that are available online
- National Speech Corpus: Contains 2000 hours of locally accented audio and text transcriptions
- LibriSpeech: Dataset consists of a large-scale corpus of around 1000 hours of English speech
- TIMIT: A collection of recordings of 630 speakers of American English
- L2-ARCTIC: A non-native English speech corpus
Everybody know Siri, the smart assistant of iPhone users. Siri is the most common example of voice recognition application. The other assistants like Microsoft’s Cortana or Amazon’s Alexa are the best examples of voice recognition-powered programs. Or maybe some of you can recall Jarvis from Ironman.
I guess many of you did use the Google’s voice to learn the true pronunciation of a word from Google translate. In that case, natural language processing is also used with voice recognition.
YouTube also uses speech recognition to automatically generate subtitles for the videos. When you upload a video that includes speeches or talks, YouTube detects it and provide a transcription. You can also have the minute-by-minute text of the transcribed speech.
There are many applications that voice recognition is implemented. Even in health care, voice recognition is used. Doctors can determine a person’s mental state whether he/she is depressed or suicidal by analyzing his/her voice.
- Automatic subtitlingwith speech recognition (YouTube)
- Automatic translation
- Court reporting(Realtime Speech Writing)
- eDiscovery(Legal discovery)
- Hands-free computing: Speech recognition computer user interface
- Mobile telephony, including mobile email
- Interactive voice response
Given a Input sound wave through the model(neural network) one chunk at a time, we'll end up with a mapping of each audio chunk to the letters most likely spoken during that chunk. Here’s what that mapping looks like for me saying “Hello”

The standerd measurement to assess the performance of an speech recognition system is the so-called Word Error Rate (WER).
- WER:
source:https://www.rev.ai/blog/how-to-calculate-word-error-rate/
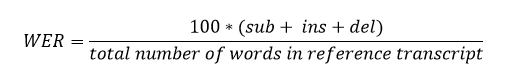
- Substitutions are anytime a word gets replaced (for example, “twinkle” is transcribed as “crinkle”)
- Insertions are anytime a word gets added that wasn’t said (for example, “trailblazers” becomes “tray all blazers”)
- Deletions are anytime a word is omitted from the transcript (for example, “get it done” becomes “get done”)

data --> train --> wav --> 1.wav
--> 2.wav
--> .....
--> .....
--> lastid.wav
--> txt --> 1.txt
--> 2.txt
--> .....
--> .....
--> lastid.txt
--> test --> wav --> 1.wav
--> 2.wav
--> .....
--> .....
--> lastid.wav
--> txt --> 1.txt
--> 2.txt
--> .....
--> .....
--> lastid.txt
--> val --> wav --> 1.wav
--> 2.wav
--> .....
--> .....
--> lastid.wav
--> txt --> 1.txt
--> 2.txt
--> .....
--> .....
--> lastid.txt
--> train_mainfile.csv
--> text_mainfile.csv
--> val_mainfile.csv
1. Create new folder calleddata
2. Create new folders data/train, data/text, data/val
3. Create new folders data/train/wav, data/train/txt && data/test/wav, data/test/txt && data/val/wav, data/val/txt
4. We are trying to put all traing .wav files in data/train/wav and all text files corresponding to .wav files put in data/train/txt, test and val also
5. Then we create a train_mainfile.csv, text_mainfile.csv, val_mainfile.csv those contains all file paths of .wav and .txt corresponding folders.
1. Download LibriSpeech datasets train-clean-360.tar.gz, test-clean.tar.gz and dev-clean.tar.gz keep in data folder
2. Then extract each file and move .wav files into corresponding files we are created
3. The folders look like this

Know we extract all .wav and .txt files, move to correspoinding folders
Then create train_mainfile.csv and test_mainfile.csv those contains information about wav_paths and txt_paths for train and test data.
Check the code in Notebook
- 1. Load
train_mainfile.csv - 2. for EDA we take sample of data
wav file : 1859-145701-0003.wav
Text : AND THE OLD KING FELL ON HER NECK AND KISSED HER BUT SHE WAS VERY MUCH TROUBLED AND SAID DEAR FATHER LISTEN TO WHAT HAS BEFALLEN ME I SHOULD NEVER HAVE COME HOME AGAIN OUT OF THE GREAT WILD WOOD IF I HAD NOT COME TO AN IRON STOVE
Wav Plot :



Observation: From above two plots we observe that most of durations in between 10sec to 16sec


Observation: From above two plots we observe that most of text lengths in between 30 and 60

Observation: both are very different distributions

Observation: From above frequency the most frequecy characters are ' '(space), 'E', 'T' and the low frequency characters are 'Z', 'X', ''', 'J' , 'Q'
Number of unique words : 16421




Observation: from the above plots we observe very few words have high frequency, most of words are low frequency
-
Extracting features from audio data, The most importent step in ML is extracting features from raw data.
-
In this section we will see how to extract features from raw audio/speech
-
- What is simple wave and how it look likes ?
-
- What is complex wave and how it look likes ?
-
- What is audio/speech wave and how it look likes ?
-
- Frequncy domine and time domine ?
-
- converting time domine to frequency domine (fft fast foure trasfram)
-
- What are the methodes to extract features from audio ?
-
- Mel-Frequency Cepstral Coefficients (MFCC)
Check this notebook : 2.Extracting Features.ipynb
-
For model we are using deepspeech2 implementation
-
For more details check this paper : Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Configuration is done in config.py.
Training command:
python main.py
| Dataset | WER | CER |
|---|---|---|
| Librispeech clean | 11.20 | 3.36 |
For more details check main.py
Download hear