A tool for converting dictionary files aka glossaries.
The primary purpose is to be able to use our offline glossaries in any Open Source dictionary we like on any OS/device.
There are countless formats, and my time is limited, so I implement formats that seem more useful for myself, or for Open Source community. Also diversity of languages is taken into account. Pull requests are welcome.
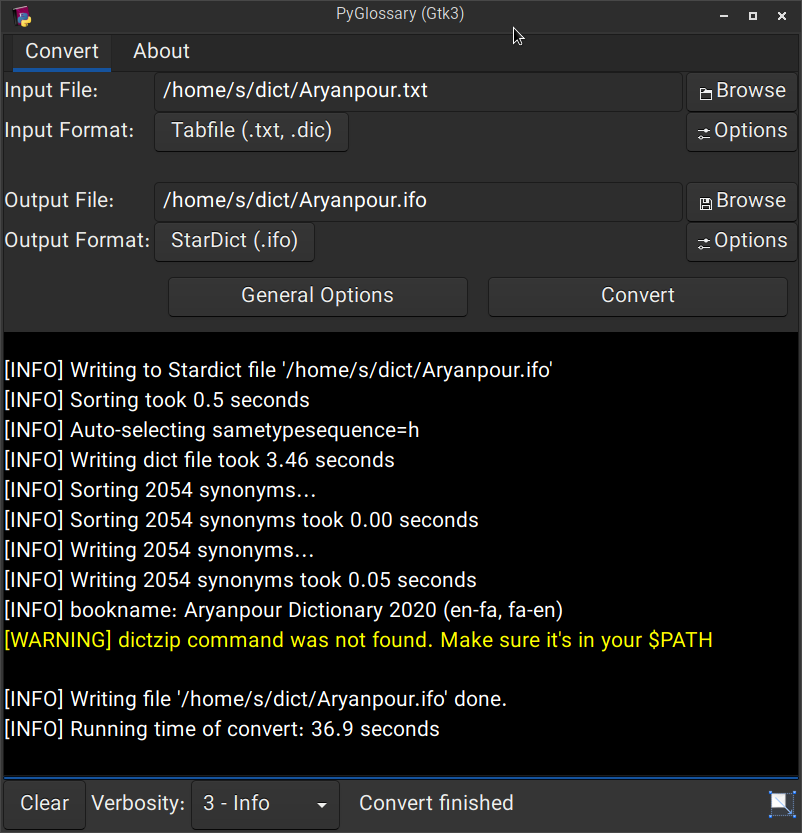
Linux - Gtk3-based interface
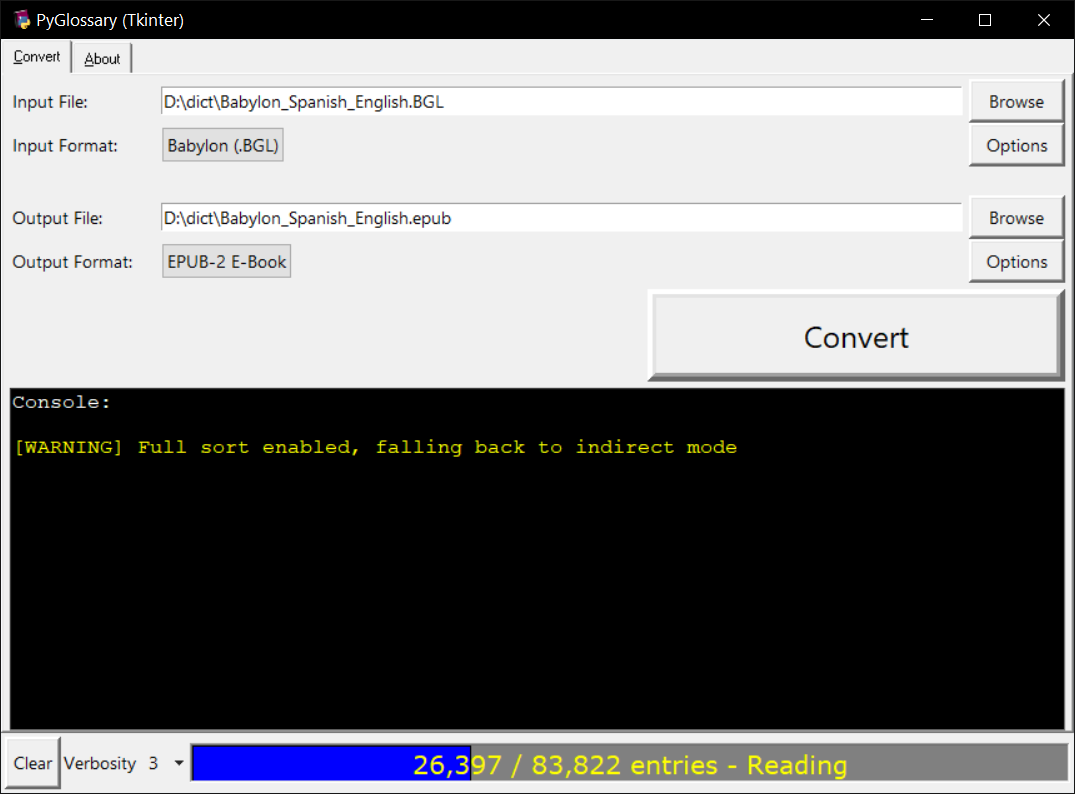
Windows - Tkinter-based interface
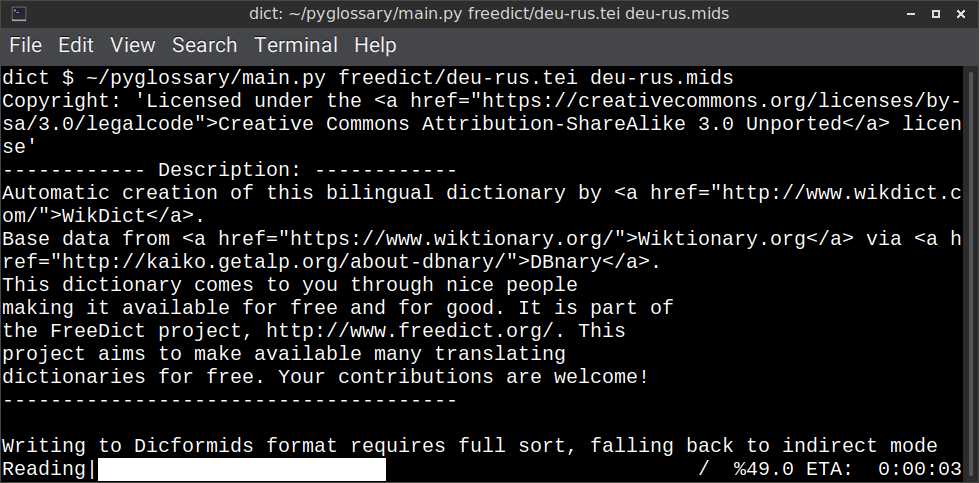
Linux - command-line interface
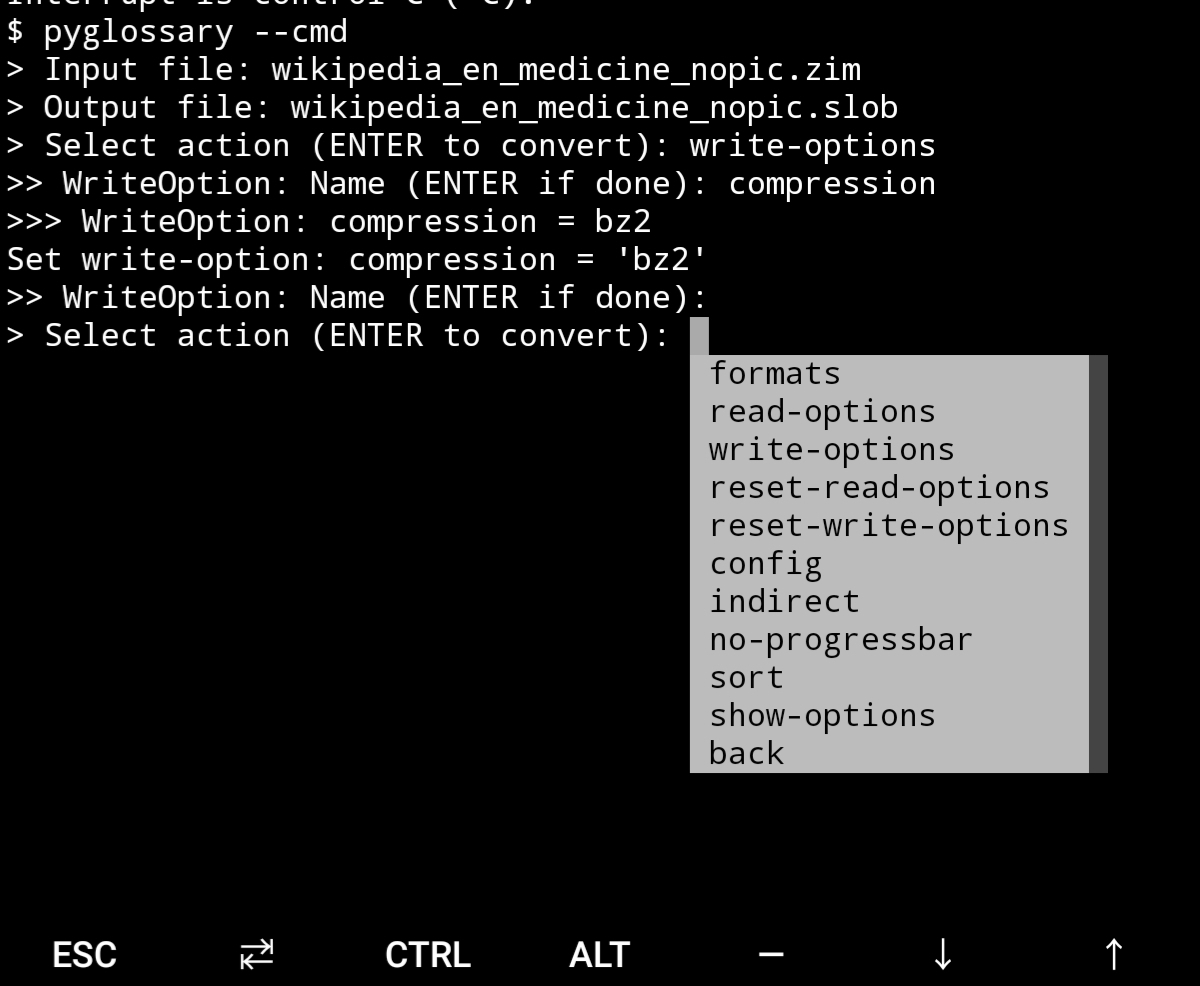
Android Termux - interactive command-line interface
| Format | Extension | Read | Write | |
|---|---|---|---|---|
| Aard 2 (slob) | 🔢 | .slob | ✔ | ✔ |
| ABBYY Lingvo DSL | 📝 | .dsl | ✔ | |
| Almaany.com (SQLite3, Arabic) | 🔢 | .db | ✔ | |
| AppleDict Binary | 📁 | .dictionary | ✔ | ❌ |
| AppleDict Source | 📁 | ✔ | ||
| Babylon BGL | 🔢 | .bgl | ✔ | ❌ |
| CC-CEDICT (Chinese) | 📝 | ✔ | ❌ | |
| cc-kedict (Korean) | 📝 | ✔ | ❌ | |
| CSV | 📝 | .csv | ✔ | ✔ |
| Dict.cc (SQLite3, German) | 🔢 | .db | ✔ | |
| DICT.org / Dictd server | 📁 | (📝.index) | ✔ | ✔ |
| DICT.org / dictfmt source | 📝 | (.dtxt) | ✔ | |
| dictunformat output file | 📝 | (.dictunformat) | ✔ | |
| DictionaryForMIDs | 📁 | (📁.mids) | ✔ | ✔ |
| DigitalNK (SQLite3, N-Korean) | 🔢 | .db | ✔ | |
| DIKT JSON | 📝 | (.json) | ✔ | |
| EDLIN | 📁 | .edlin | ✔ | ✔ |
| EPUB-2 E-Book | 📦 | .epub | ❌ | ✔ |
| FreeDict | 📝 | .tei | ✔ | ❌ |
| Gettext Source | 📝 | .po | ✔ | ✔ |
| HTML Directory (by file size) | 📁 | ❌ | ✔ | |
| JMDict (Japanese) | 📝 | ✔ | ❌ | |
| JSON | 📝 | .json | ✔ | |
| Kobo E-Reader Dictionary | 📦 | .kobo.zip | ❌ | ✔ |
| Kobo E-Reader Dictfile | 📝 | .df | ✔ | ✔ |
| Lingoes Source | 📝 | .ldf | ✔ | ✔ |
| Mobipocket E-Book | 🔢 | .mobi | ❌ | ✔ |
| Octopus MDict | 🔢 | .mdx | ✔ | ❌ |
| QuickDic version 6 | 📁 | .quickdic | ✔ | ✔ |
| SQL | 📝 | .sql | ❌ | ✔ |
| StarDict | 📁 | (📝.ifo) | ✔ | ✔ |
| StarDict Textual File | 📝 | (.xml) | ✔ | ✔ |
| Tabfile | 📝 | .txt, .tab | ✔ | ✔ |
| Wiktextract | 📝 | .jsonl | ✔ | |
| Wordset.org | 📁 | ✔ | ||
| XDXF | 📝 | .xdxf | ✔ | ❌ |
| Yomichan | 📦 | (.zip) | ✔ | |
| Zim (Kiwix) | 🔢 | .zim | ✔ |
Legend:
- 📁 Directory
- 📝 Text file
- 📦 Package/archive file
- 🔢 Binary file
- ✔ Supported
- ❌ Will not be supported
Note: SQLite-based formats are not detected by extension (.db);
So you need to select the format (with UI or --read-format flag).
Also don't confuse SQLite-based formats with SQLite mode.
PyGlossary requires Python 3.10 or higher, and works in practically all modern operating systems. While primarily designed for GNU/Linux, it works on Windows, Mac OS X and other Unix-based operating systems as well.
As shown in the screenshots, there are multiple User Interface types (multiple ways to use the program).
-
Gtk3-based interface, uses PyGI (Python Gobject Introspection) You can install it on:
- Debian/Ubuntu:
apt install python3-gi python3-gi-cairo gir1.2-gtk-3.0 - openSUSE:
zypper install python3-gobject gtk3 - Fedora:
dnf install pygobject3 python3-gobject gtk3 - ArchLinux:
pacman -S python-gobject gtk3- https://aur.archlinux.org/packages/pyglossary/
- Mac OS X:
brew install pygobject3 gtk+3 - Nix / NixOS:
nix-shell -p pkgs.gobject-introspection python38Packages.pygobject3 python38Packages.pycairo
- Debian/Ubuntu:
-
Tkinter-based interface, works in the lack of Gtk. Specially on Windows where Tkinter library is installed with the Python itself. You can also install it on:
- Debian/Ubuntu:
apt-get install python3-tk tix - openSUSE:
zypper install python3-tk tix - Fedora:
yum install python3-tkinter tix - Mac OS X: read https://www.python.org/download/mac/tcltk/
- Nix / NixOS:
nix-shell -p python38Packages.tkinter tix
- Debian/Ubuntu:
-
Command-line interface, works in all operating systems without any specific requirements, just type:
python3 main.py --help- Interactive command-line interface
- Requires:
pip install prompt_toolkit - Perfect for mobile devices (like Termux on Android) where no GUI is available
- Automatically selected if output file argument is not passed and one of these:
- On Linux and
$DISPLAYenvironment variable is empty or not set- For example when you are using a remote Linux machine over SSH
- On Mac and no
tkintermodule is found
- On Linux and
- Manually select with
--cmdor--ui=cmd- Minimally:
python3 main.py --cmd - You can still pass input file, or any flag/option
- Minimally:
- If both input and output files are passed, non-interactive cmd ui will be default
- If you are writing a script, you can pass
--no-interactiveto force disable interactive ui- Then you have to pass both input and output file arguments
- Don't forget to use Up/Down or Tab keys in prompts!
- Up/Down key shows you recent values you have used
- Tab key shows available values/options
- You can press Control+C (on Linux/Windows) at any prompt to exit
- Requires:
- Interactive command-line interface
When you run PyGlossary without any command-line arguments or options/flags,
PyGlossary tries to find PyGI and open the Gtk3-based interface. If it fails,
it tries to find Tkinter and open the Tkinter-based interface. If that fails,
it tries to find prompt_toolkit and run interactive command-line interface.
And if none of these libraries are found, it exits with an error.
But you can explicitly determine the user interface type using --ui
python3 main.py --ui=gtkpython3 main.py --ui=tkpython3 main.py --ui=cmd
- Download and install Python (3.9 or above)
- Open Start -> type Command -> right-click on Command Prompt -> Run as administrator
- To ensure you have
pip, run:python -m ensurepip --upgrade - To install, run:
pip install --upgrade pyglossary - Now you should be able to run
pyglossarycommand - If command was not found, make sure Python environment variables are set up:
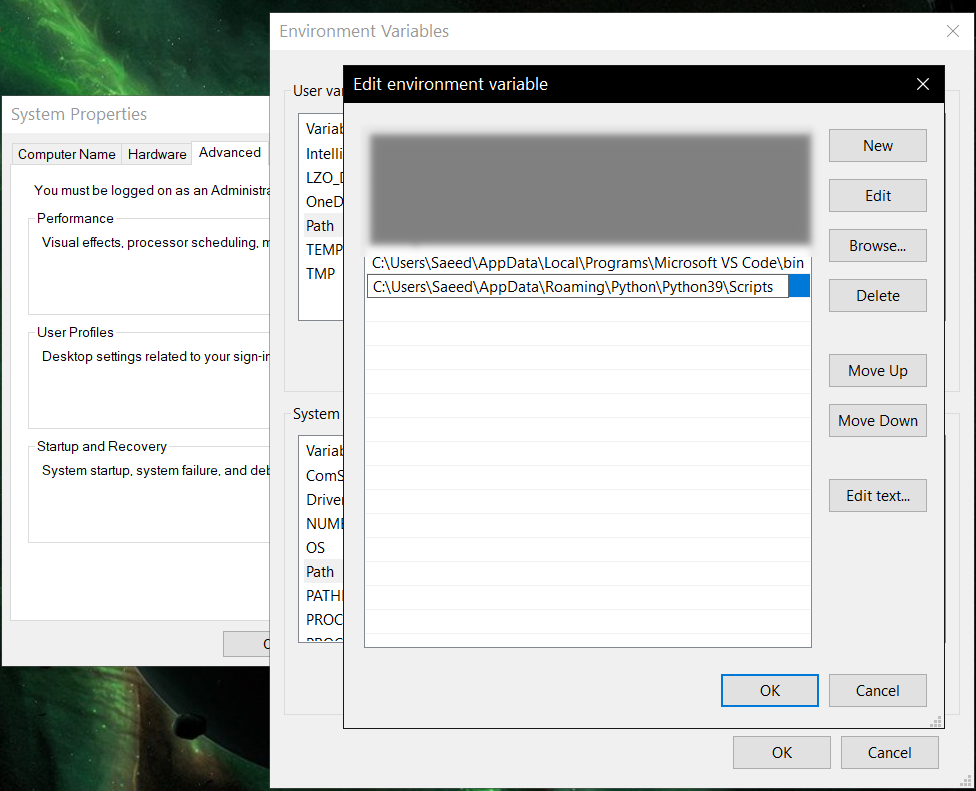
-
Using Sort by Locale feature requires PyICU
-
Using
--remove-html-allflag requires:pip install lxml beautifulsoup4
Some formats have additional requirements. If you have trouble with any format, please check the link given for that format to see its documentations.
Using Termux on Android? See doc/termux.md
See doc/config.rst.
Indirect mode means the input glossary is completely read and loaded into RAM, then converted into the output format. This was the only method available in old versions (before 3.0.0).
Direct mode means entries are one-at-a-time read, processed and written into output glossary.
Direct mode was added to limit the memory usage for large glossaries; But it may reduce the conversion time for most cases as well.
Converting glossaries into these formats requires sorting entries:
That's why direct mode will not work for these formats, and PyGlossary has to switch to indirect mode (or it previously had to, see SQLite mode).
For other formats, direct mode will be the default. You may override this by --indirect flag.
As mentioned above, converting glossaries to some specific formats will need them to loaded into RAM.
This can be problematic if the glossary is too big to fit into RAM. That's when
you should try adding --sqlite flag to your command. Then it uses SQLite3 as intermediate
storage for storing, sorting and then fetching entries. This fixes the memory issue, and may
even reduce running time of conversion (depending on your home directory storage).
The temporary SQLite file is stored in cache directory then
deleted after conversion (unless you pass --no-cleanup flag).
SQLite mode is automatically enabled for writing these formats if auto_sqlite
config parameter is true (which is the default).
This also applies to when you pass --sort flag for any format.
You may use --no-sqlite to override this and switch to indirect mode.
Currently you can not disable alternates in SQLite mode (--no-alts is ignored).
There are two things than can activate sorting entries:
- Output format requires sorting (as explained above)
- You pass
--sortflag in command line.
In the case of passing --sort, you can also pass:
-
--sort-keyto select sort key aka sorting order (including locale), see doc/sort-key.md -
--sort-encodingto change the encoding used for sort- UTF-8 is the default encoding for all sort keys and all output formats (unless mentioned otherwise)
- This will only effect the order of entries, and will not corrupt words / definition
- Non-encodable characters are replaced with
?byte (only for sorting) - Conflicts with
--sort-locale
Cache directory is used for storing temporary files which are either moved or deleted
after conversion. You can pass --no-cleanup flag in order to keep them.
The path for cache directory:
- Linux or BSD:
~/.cache/pyglossary/ - Mac:
~/Library/Caches/PyGlossary/ - Windows:
C:\Users\USERNAME\AppData\Local\PyGlossary\Cache\
If you want to add your own plugin without adding it to source code directory, or you want to use a plugin that has been removed from repository, you can place it in this directory:
- Linux or BSD:
~/.pyglossary/plugins/ - Mac:
~/Library/Preferences/PyGlossary/plugins/ - Windows:
C:\Users\USERNAME\AppData\Roaming\PyGlossary\plugins\
There are a few examples in doc/lib-examples directory.
Here is a basic script that converts any supported glossary format to Tabfile:
import sys
from pyglossary import Glossary
# Glossary.init() should be called only once, so make sure you put it
# in the right place
Glossary.init()
glos = Glossary()
glos.convert(
inputFilename=sys.argv[1],
outputFilename=f"{sys.argv[1]}.txt",
# although it can detect format for *.txt, you can still pass outputFormat
outputFormat="Tabfile",
# you can pass readOptions or writeOptions as a dict
# writeOptions={"encoding": "utf-8"},
)And if you choose to use glossary_v2:
import sys
from pyglossary.glossary_v2 import ConvertArgs, Glossary
# Glossary.init() should be called only once, so make sure you put it
# in the right place
Glossary.init()
glos = Glossary()
glos.convert(ConvertArgs(
inputFilename=sys.argv[1],
outputFilename=f"{sys.argv[1]}.txt",
# although it can detect format for *.txt, you can still pass outputFormat
outputFormat="Tabfile",
# you can pass readOptions or writeOptions as a dict
# writeOptions={"encoding": "utf-8"},
))You may look at docstring of Glossary.convert for full list of keyword arguments.
If you need to add entries inside your Python program (rather than converting one glossary into another), then you use write instead of convert, here is an example:
from pyglossary import Glossary
Glossary.init()
glos = Glossary()
mydict = {
"a": "test1",
"b": "test2",
"c": "test3",
}
for word, defi in mydict.items():
glos.addEntryObj(glos.newEntry(
word,
defi,
defiFormat="m", # "m" for plain text, "h" for HTML
))
glos.setInfo("title", "My Test StarDict")
glos.setInfo("author", "John Doe")
glos.write("test.ifo", format="Stardict")Note: addEntryObj is renamed to addEntry in pyglossary.glossary_v2.
Note: Switching to glossary_v2 is optional and recommended.
And if you need to read a glossary from file into a Glossary object in RAM (without immediately converting it), you can use glos.read(filename, format=inputFormat). Be wary of RAM usage in this case.
If you want to include images, css, js or other files in a glossary that you are creating, you need to add them as Data Entries, for example:
with open(os.path.join(imageDir, "a.jpeg")) as fp:
glos.addEntry(glos.newDataEntry("img/a.jpeg", fp.read()))The first argument to newDataEntry must be the relative path (that generally html codes of your definitions points to).
A glossary contains a number of entries.
Each entry contains:
- Headword (title or main phrase for lookup)
- Alternates (some alternative phrases for lookup)
- Definition
In PyGlossary, headword and alternates together are accessible as a single Python list entry.l_word
entry.defi is the definition as a Python Unicode str. Also entry.b_defi is definition in UTF-8 byte array.
entry.defiFormat is definition format. If definition is plaintext (not rich text), the value is m. And if it's in HTML (contains any html tag), then defiFormat is h. The value x is also allowed for XFXF, but XDXF is not widely supported in dictionary applications.
There is another type of entry which is called Data Entry, and generally contains an image, audio, css, or any other file that was included in input glossary. For data entries:
entry.s_wordis file name (andl_wordis still a list containing this string),entry.defiFormatisbentry.datagives the content of file inbytes.
Entry filters are internal objects that modify words/definition of entries, or remove entries (in some special cases).
Like several filters in a pipe which connects a reader object to a writer object
(with both of their classes defined in plugins and instantiated in Glossary class).
You can enable/disable some of these filters using config parameters / command like flags, which are documented in doc/config.rst.
The full list of entry filters is also documented in doc/entry-filters.md.