Данный репозиторий является решением "Кейс №1: Защита редких животных" от команды "ML Princess [Napoleon IT]"
- app - папка содержащая реализацию бэка, всю логику работы моделей, инициализацию моделей
- telebot - папка содержащая реализацию бота, логику обработки ответов модели и их вывод пользователю
- backend.py - вспомогательный файл для запуска сервиса
- docker-compose.yml - конфиг докера для сборки и поднятия сервиса и бота с нужными портами и тд
- Dockerfile - докер файл сервиса, отвечающий за окружение и установку нужных пакетов, библиотек
- inference_model.py - скрипт для инференса моделей(прогон изображений через модели и составление csv таблицы с результатами работы)
- requirements.txt - файл со всеми необходимыми библиотеками для работы сервиса
Для того чтобы поднять сервис на локальной/удаленной машине нужно:
- убедиться, что указанные порты в
docker-compose.ymlдоступны на вашей машине - запустить скрипт сборки docker контейнеров:
docker-compose build
- запустить скрипт поднятия сервисов:
docker-compose up
- Поздравляем, сервисы подняты
В сервисе используются 3 обученные модели:
- Две каскадные модели для детекции животных
- Визуальный трансформер ViT с ArcFace для классификации солодых и взрослых особей, найденных на предыдущем шаге
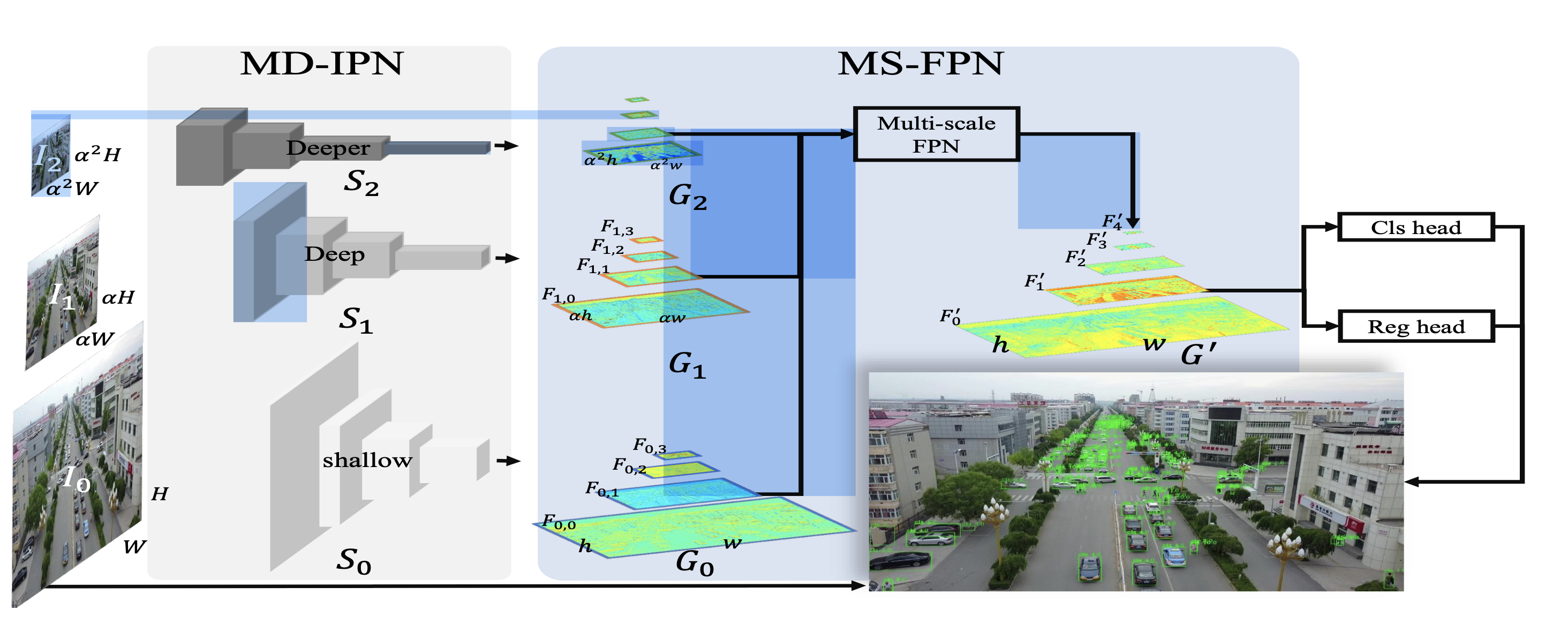
Мы реализовали сервис с моделями детекции, который производит подсчет моржей на лежбище по принятым изображениям Структурно наше решение можно представить следующим образом
graph TD
A(Start Service) --> P[Images request]
P --> B[Preprocessing]
B --> C[Detection Service]
C --> D[HRNet model]
C --> E[Cascade RCNN model]
D --> F[sahi sliced detection]
E --> J[sahi sliced detection]
F --> K[Detection Ensemble]
J --> K[Detection Ensemble]
K --> Y[Draw contours]
Y --> V[Save and Visualize]
V --> X[Sum up the statistics]
X --> Z(Send response)
Мы провели ряд экспериментов с разными архитектурами и подходами в обучении моделей детекции. Одной из особенностей данной задачи является проблема детекции мелких объектов на high resolution изображениях. Подходы к решению данной проблемы рассмотрены в ряде статей:
- HRDNet: High-resolution Detection Network for Small Objects - https://arxiv.org/pdf/2006.07607.pdf
- Small Object Detection using Deep Learning - https://arxiv.org/pdf/2201.03243.pdf
После изучения данной проблемы и полученных данных мы решили провести эксперименты и мы подсчитывали кастомную метрику:
Здесь будет формула для подсчета метрики
| model | method/arch |
|---|---|
| Cascade + ResNet-50 | RFP |
| Cascade + ResNet-50 | SAC |
| Cascade R-CNN | HRNet |
| FCOS | HRNet |
| Faster R-CNN | FPN |
| Yolo | V5 |
| Yolo | X |
После анализа результатов мы приняли выбрали 2 модели, которые показали по нашей метрике лучшие результаты:
- CASCADE_RCNN_HRNET
- CASCADE_RCNN


Мы решили заняться тюнингом данных моделей для улучшения распознований, но к значительным изменениям это не привело, в следствии чего мы углубились в ресерч.
Из статей мы вынесли основную мысль - мы хотим обученной моделью предиктить не сразу все изображение, а делать это определенным слайдом. Данный механизм присутствует в библиотеке sahi (ссылка на исходник):
 Данным механизмом мы улучшили наши метрики на
Данным механизмом мы улучшили наши метрики на 30%. В итоге мы решили полноценно внедрить данную технологию.
Как мы выяснили из экспериментов и статей:
- Модель
HRNetхорошо работает наhigh resolutionизображениях и хорошо детектит мелкие элементы - Модель
Cascade RCNNхорошо справляется с детекцией элементов на ближних изображениях
После данных наблюдений мы решили попробовать сделать ансамбль из данных моделей (в связке с sahi) с неким усреднением bboxes с каждой модели - если кратко, то целью было брать объекты, которые нашла одна модель, а другая не справилась с этим.
По итогу мы механизмом ансамблирования лучших моделей мы улучшили качество на 9%.