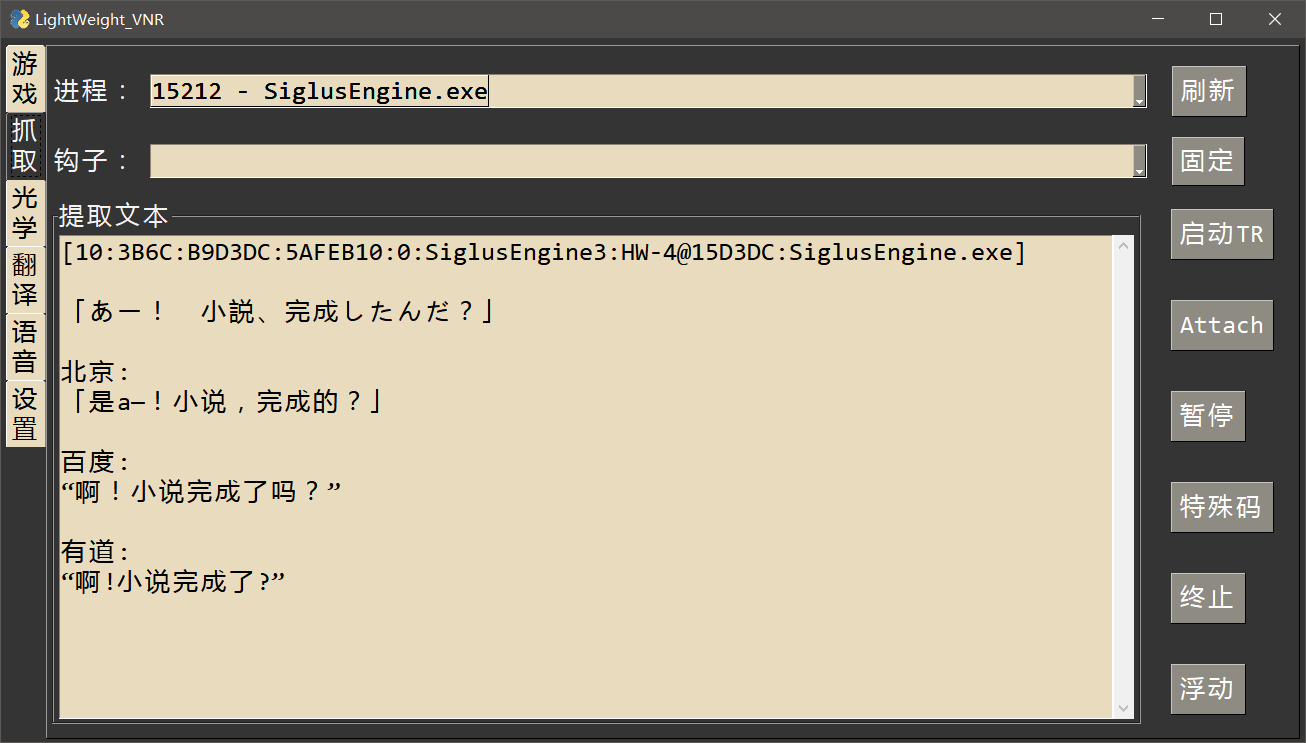
- 抓取界面
- 小窗口



- 本项目可调用
Textractor来抓取Galgame的游戏文本 - 本项目可调用
Tesseract-OCR来抓取文字,支持日文、简体中文、繁体中文、英文 - 本项目可调用
JBeijing、有道词典、百度翻译来实现翻译功能 - 本项目可调用
Yukari、Tamiyasu、VOICEROID2等来实现文本阅读功能 - 本项目可满足离线使用的需求
- 填好
游戏名称(可不填)、程序目录、启动方式、特殊码(没有可不填)后添加即可程序目录、启动方式必须填,游戏名称若为空,添加时将程序名作为游戏名称- 转区运行需在
设置-游戏中设置Locale Emulator路径
- 修改游戏信息后按
添加即可修改信息 - 选择一项游戏后按
删除即可删除 - 选择一项游戏后按
启动游戏即可启动游戏,并自动启动Textractor注入dll
- 设置
Textractor目录,确保目录下有TextractorCLI.exe和texthook.dll - 点击
启动TR,选择游戏进程,再Attach注入dll- 若从
游戏列表中启动游戏,则无需进行此步骤 游戏进程栏也可手动输入游戏进程的pid
- 若从
- 选择
钩子并固定- 若
钩子列表频繁刷新,可先暂停再选择并固定,之后再继续 - 若
钩子过长导致看不到文本内容,可按住鼠标左键向右拖动
- 若
dll注入后,游戏进程不关,则再次打开程序只需启动TR并选择、固定钩子即可特殊码使用之前必须确保dll已注入,且特殊码格式必须正确
- 设置
Tesseract-OCR路径- 确保该路径下至少包含:
展开查看
├── tessdata │ ├── chi_sim.traineddata │ ├── chi_sim_vert.traineddata │ ├── chi_tra.traineddata │ ├── chi_tra_vert.traineddata │ ├── eng.traineddata │ ├── jpn.traineddata │ └── jpn_vert.traineddata │ ├── libgcc_s_seh-1.dll ├── libgif-7.dll ├── libgomp-1.dll ├── libjbig-2.dll ├── libjpeg-8.dll ├── liblept-5.dll ├── liblzma-5.dll ├── libopenjp2.dll ├── libpng16-16.dll ├── libstdc++-6.dll ├── libtesseract-5.dll ├── libtiff-5.dll ├── libwebp-7.dll ├── libwinpthread-1.dll ├── tesseract.exe └── zlib1.dll
- 确保该路径下至少包含:
截取屏幕上的某一区域,用鼠标划定区域,划定完按Enter- 截取完会直接显示截图图片和文本
- 按
ESC键退出截取界面
截取后按连续,则开始以某一间隔在同一位置进行连续识别- 按
结束则结束连续识别
- 按
- 根据程序显示的图片效果,可以调整
阈值化方式和阈值,来减小背景的影响
JBeijing启用并保存即可
- 注意:
有道调用的不是API,而是本地的有道词典程序(不可最小化) - 设置好
有道词典路径后,点击启动有道,并切换到词典翻译页面 - 若本程序获取的翻译文本
错位,可尝试增加翻译间隔 - 可以取消
抓取翻译,并将词典的翻译栏拖在游戏窗口下方
- 注意:
百度翻译是在线翻译,需要使用百度账号免费申请api,流程如下:
- https://api.fanyi.baidu.com/进入百度翻译开放平台
- 按照指引完成api开通,只需要申请
通用翻译API - 完成申请后点击顶部
管理控制台,在申请信息一栏可获取APP ID与密钥
- 启用百度翻译前需要填写
APP ID与密钥并且保存
- 设置好
Yukari路径后,点击启动Yukari即可(可最小化) 连续阅读:连续阅读抓取文本,即抓取到新文本时读取新文本阅读内容:勾上的内容会读取,反之忽略- 判断依据:有
「、『、(、(的为角色对话,反之为旁白
- 同上
- 设置好
VOICEROID2路径并启用即可(不需要打开) - 可选择
VOICEROID2已拥有的的角色阅读- 角色名字为
VOICEROID2路径下的Voice文件夹内的各个子文件夹名称
- 角色名字为
- 可调整各项参数,同
VOICEROID2软件界面的下方
文本去重数:文本重复的次数- 类型(重复2次为例)
aabbcc -> abcabcabc -> abc
智能去重:根据句子自动判断重复次数并去重,勾上后文本去重数失效
- 类型(重复2次为例)
垃圾字符表:去除文本中含的垃圾字符,垃圾字符以空格分隔正则表达式:将正则表达式中的所有()部分连接,剩下的去除
- 打开浮动窗口,会隐藏主窗口,并显示设置中启用的条目,包括原文、各种翻译
- 可在
抓取和光学界面中打开浮动
- 可在
- 浮动窗口可通过按
ESC和右键关闭的方式退出 - 浮动窗口包含
暂停和阅读的功能键,快捷键以及功能如下:暂停:;,即暂停Textractor或OCR的文本抓取阅读:',即阅读当前抓取的文本
- 本项目可用
Pyinstaller打包,命令:pyinstaller -Fw main.py- 注意要在32位
Python环境下,否则某些功能可能会不可用
- 注意要在32位
- 因界面排版问题,选择
Microsoft YaHei Mono字体 - 调用
J北京、Yukari、Tamiyasu的代码参考了VNR的源码 - 调用
VOICEROID2的代码参考了Nkyoku/pyvcroid2项目