-
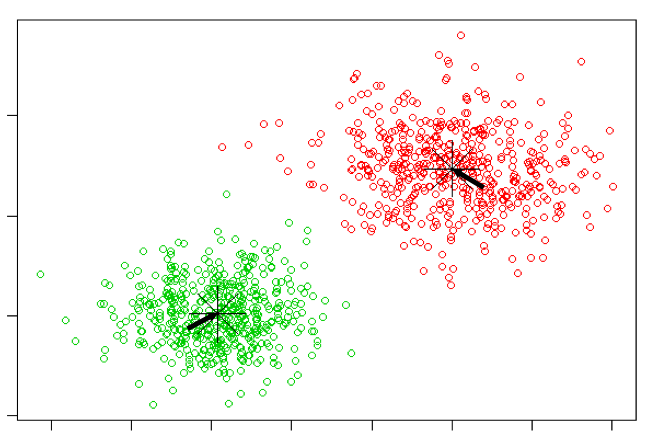
Our objective is to group the unlabeled data into k clusters. K-Means is an iterative algorithm. So, first we are going to randomly initialize k points (since we want to group the data into k clusters), known as cluster centroids.
-
The algorithm goes through each of the examples and depending on which cluster centroid they are closer to, it assigns each of the data points to one of the cluster centroids. This step is called the “Cluster Assignment Step”.
-
The second part of the iteration is called the “Move Centroid Step”. The two cluster centroids are taken and moved to the average of their corresponding data points. Specifically, we are going to compute the mean of the points’ location for each of the two clusters already formed and move the centroids to their respective cluster means.
-
The algorithm continues with the specified number of iterations performing Cluster Assignment and Move Centroid steps iteratively and eventually K-Means converges.
The K-Means Algorithm scales really well to large datasets, generalized to clusters of various shapes and guarantees convergence after a specific number of iterations. However, it fails to yield accurate results if outliers are present or density of the spread of data is not even. Nevertheless, equipped with the quality of adapting easily to new examples, K-Means is still the most widely used Unsupervised Learning Algorithm.

To know more about the K-Means Clustering Algorithm, you may check out my article here.