![]()





Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when interacting with data. It does that today by indexing data resources (tables, dashboards, streams, etc.) and powering a page-rank style search based on usage patterns (e.g. highly queried tables show up earlier than less queried tables). Think of it as Google search for data. The project is named after Norwegian explorer Roald Amundsen, the first person to discover the South Pole.

Amundsen is hosted by the LF AI & Data Foundation. It includes three microservices, one data ingestion library and one common library.
- amundsenfrontendlibrary: Frontend service which is a Flask application with a React frontend.
- amundsensearchlibrary: Search service, which leverages Elasticsearch for search capabilities, is used to power frontend metadata searching.
- amundsenmetadatalibrary: Metadata service, which leverages Neo4j or Apache Atlas as the persistent layer, to provide various metadata.
- amundsendatabuilder: Data ingestion library for building metadata graph and search index.
Users could either load the data with a python script with the library
or with an Airflow DAG importing the library.
- amundsencommon: Amundsen Common library holds common codes among microservices in Amundsen.
- amundsengremlin: Amundsen Gremlin library holds code used for converting model objects into vertices and edges in gremlin. It's used for loading data into an AWS Neptune backend.
- amundsenrds: Amundsenrds contains ORM models to support relational database as metadata backend store in Amundsen. The schema in ORM models follows the logic of databuilder models. Amundsenrds will be used in databuilder and metadatalibrary for metadata storage and retrieval with relational databases.







- Python = 3.6 or 3.7
- Node = v10 or v12 (v14 may have compatibility issues)
- npm >= 6
Please note that the mock images only served as demonstration purpose.
-
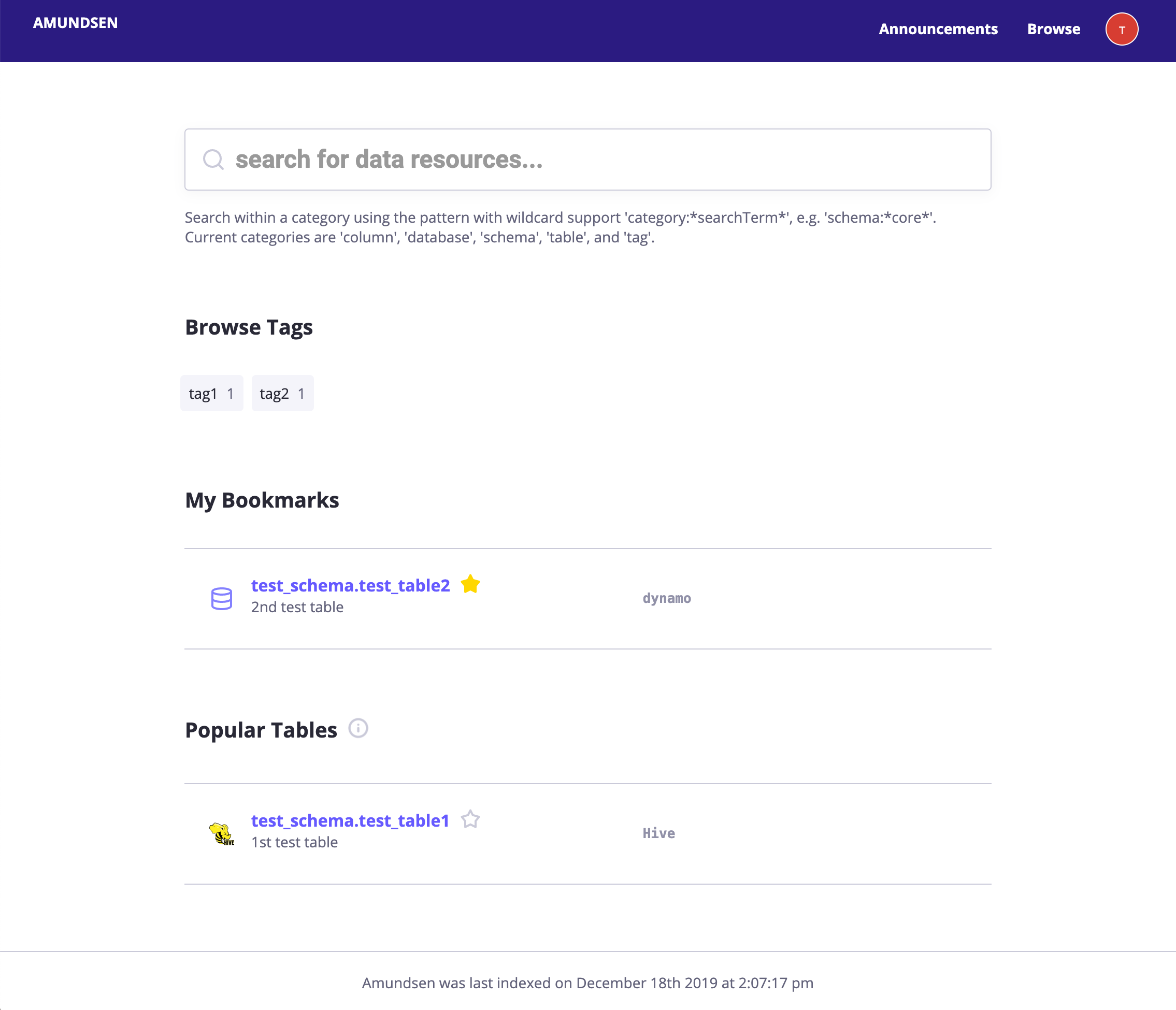
Landing Page: The landing page for Amundsen including 1. search bars; 2. popular used tables;
-
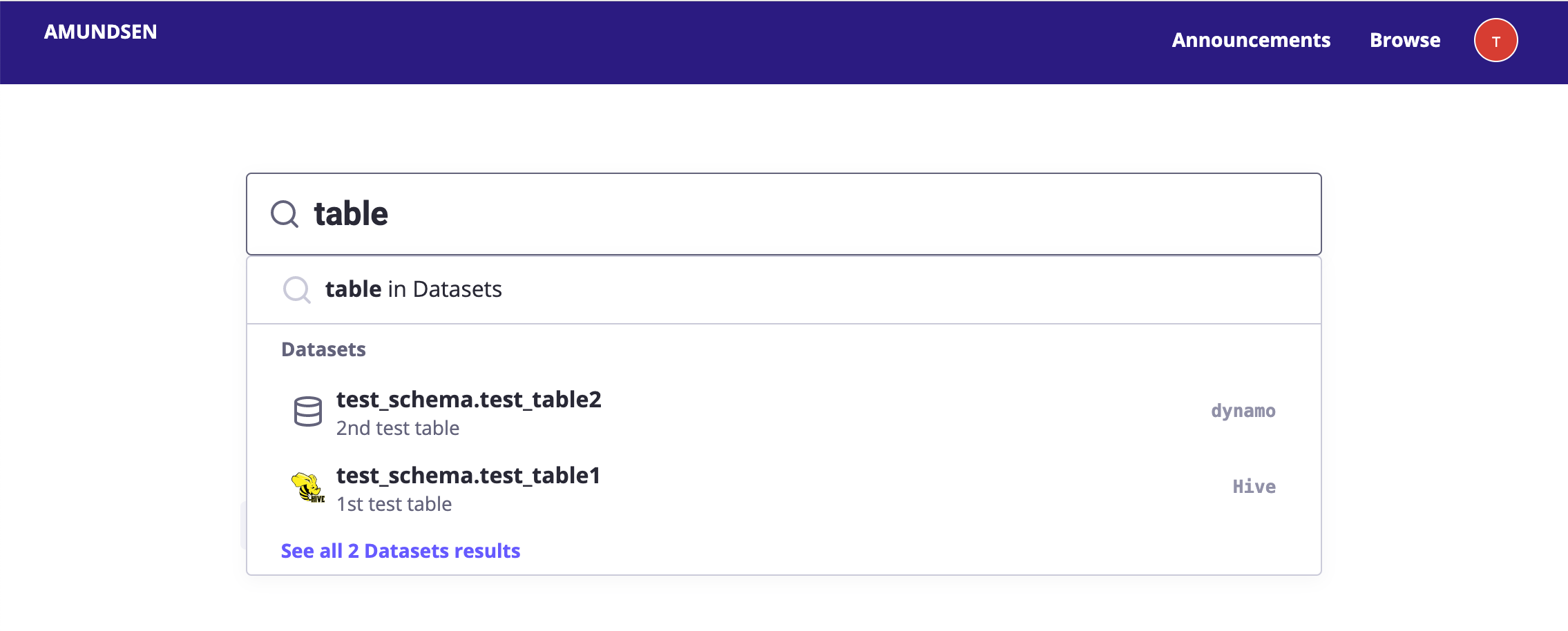
Search Preview: See inline search results as you type
-
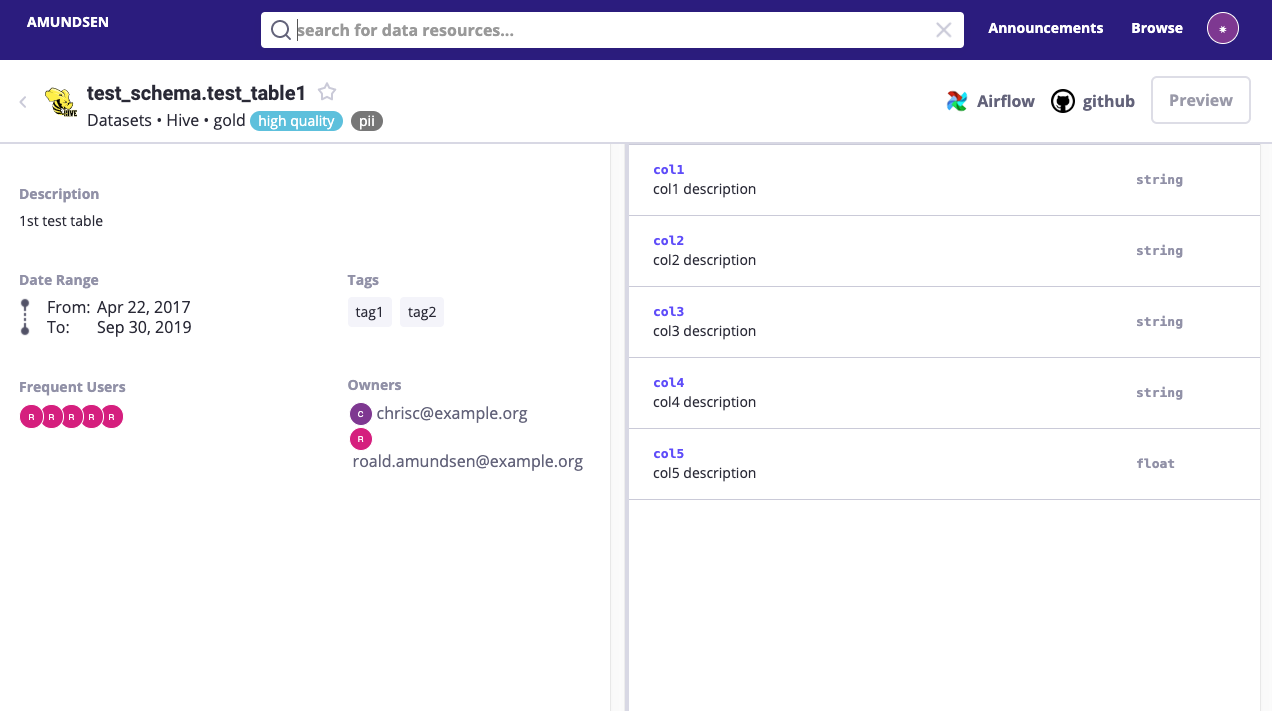
Table Detail Page: Visualization of a Hive / Redshift table
-
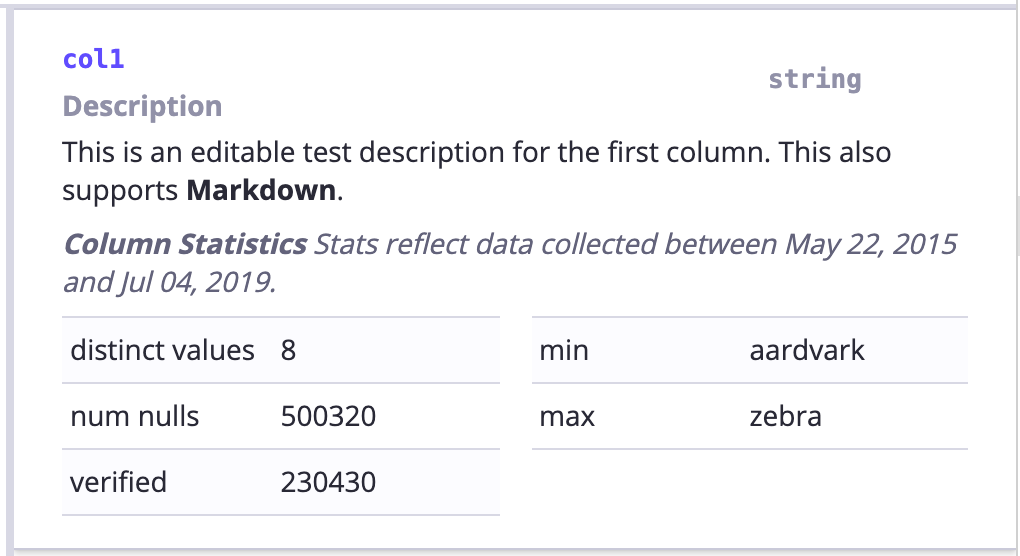
Column detail: Visualization of columns of a Hive / Redshift table which includes an optional stats display
-
Data Preview Page: Visualization of table data preview which could integrate with Apache Superset or other Data Visualization Tools.
Want help or want to help? Use the button in our header to join our slack channel. Contributions are also more than welcome! As explained in CONTRIBUTING.md there are many ways to contribute, it does not all have to be code with new features and bug fixes, also documentation, like FAQ entries, bug reports, blog posts sharing experiences etc. all help move Amundsen forward. If you find a security vulnerability, please follow this guide.
Please visit the Amundsen installation documentation for a quick start to bootstrap a default version of Amundsen with dummy data.
Please visit Architecture for Amundsen architecture overview.
- Tables (from Databases)
- People (from HR systems)
- Dashboards
- Amazon Athena
- Amazon Glue and anything built over it (like Databricks Delta - which is a work in progress).
- Amazon Redshift
- Apache Cassandra
- Apache Druid
- Apache Hive
- CSV
- Delta Lake
- Google BigQuery
- IBM DB2
- Microsoft SQL Server
- MySQL
- Oracle (through dbapi or sql_alchemy)
- PostgreSQL
- Trino (formerly Presto SQL)
- Vertica
- Snowflake
Amundsen can also connect to any database that provides dbapi or sql_alchemy interface (which most DBs provide).
Please visit Installation guideline on how to install Amundsen.
Please visit Roadmap if you are interested in Amundsen upcoming roadmap items.
- Amundsen - Lyft's data discovery & metadata engine (April 2019)
- Software Engineering Daily podcast on Amundsen (April 2019)
- How Lyft Drives Data Discovery (July 2019)
- Data Engineering podcast on Solving Data Discovery At Lyft (Aug 2019)
- Open Sourcing Amundsen: A Data Discovery And Metadata Platform (Oct 2019)
- Adding Data Quality into Amundsen with Programmatic Descriptions by Sam Shuster from Edmunds.com (May 2020)
- Facilitating Data discovery with Apache Atlas and Amundsen by Mariusz Górski from ING (June 2020)
- Using Amundsen to Support User Privacy via Metadata Collection at Square by Alyssa Ransbury from Square (July 14, 2020)
- Amundsen Joins LF AI as New Incubation Project (Aug 11, 2020)
- Amundsen: one year later (Oct 6, 2020)
- Disrupting Data Discovery {slides, recording} (Strata SF, March 2019)
- Amundsen: A Data Discovery Platform from Lyft {slides} (Data Council SF, April 2019)
- Disrupting Data Discovery {slides} (Strata London, May 2019)
- ING Data Analytics Platform (Amundsen is mentioned) {slides, recording } (Kubecon Barcelona, May 2019)
- Disrupting Data Discovery {slides, recording} (Making Big Data Easy SF, May 2019)
- Disrupting Data Discovery {slides, recording} (Neo4j Graph Tour Santa Monica, September 2019)
- Disrupting Data Discovery {slides} (IDEAS SoCal AI & Data Science Conference, Oct 2019)
- Data Discovery with Amundsen by Gerard Toonstra from Coolblue {slides} and {talk} (BigData Vilnius 2019)
- Towards Enterprise Grade Data Discovery and Data Lineage with Apache Atlas and Amundsen by Verdan Mahmood and Marek Wiewiorka from ING {slides, talk} (Big Data Technology Warsaw Summit 2020)
- Airflow @ Lyft (which covers how we integrate Airflow and Amundsen) by Tao Feng {slides and website} (Airflow Summit 2020)
- Data DAGs with lineage for fun and for profit by Bolke de Bruin {website} (Airflow Summit 2020)
- How LinkedIn, Uber, Lyft, Airbnb and Netflix are Solving Data Management and Discovery for Machine Learning Solutions
- Data Discovery in 2020
- 4 Data Trends to Watch in 2020
- Work-Bench Snapshot: The Evolution of Data Discovery & Catalog
- Future of Data Engineering
- Governance and Discovery
- A Data Engineer’s Perspective On Data Democratization
- Graph Technology Landscape 2020
- In-house Data Discovery platforms
- Linux Foundation AI Foundation Landscape
- Lyft’s Amundsen: Data-Discovery with Built-In Trust
- How to find and organize your data from the command-line
- Data Discovery Platform at Bagelcode
- Cataloging Tools for Data Teams
- An Overview of Data Discovery Platforms and Open Source Solutions
- Hacking Data Discovery in AWS with Amundsen at SEEK
- A step-by-step guide deploying Amundsen on Google Cloud Platform
Community meetings are held on the first Thursday of every month at 9 AM Pacific, Noon Eastern, 6 PM Central European Time. Link to join
You can the exact date for the next meeting and the agenda a few weeks before the meeting in this doc.
Notes from all past meetings are available here.
Here is the list of organizations that are using Amundsen today. If your organization uses Amundsen, please file a PR and update this list.
Currently officially using Amundsen: