An LSTM Autoencoder is an implementation of an autoencoder for sequence data using an Encoder-Decoder LSTM architecture.
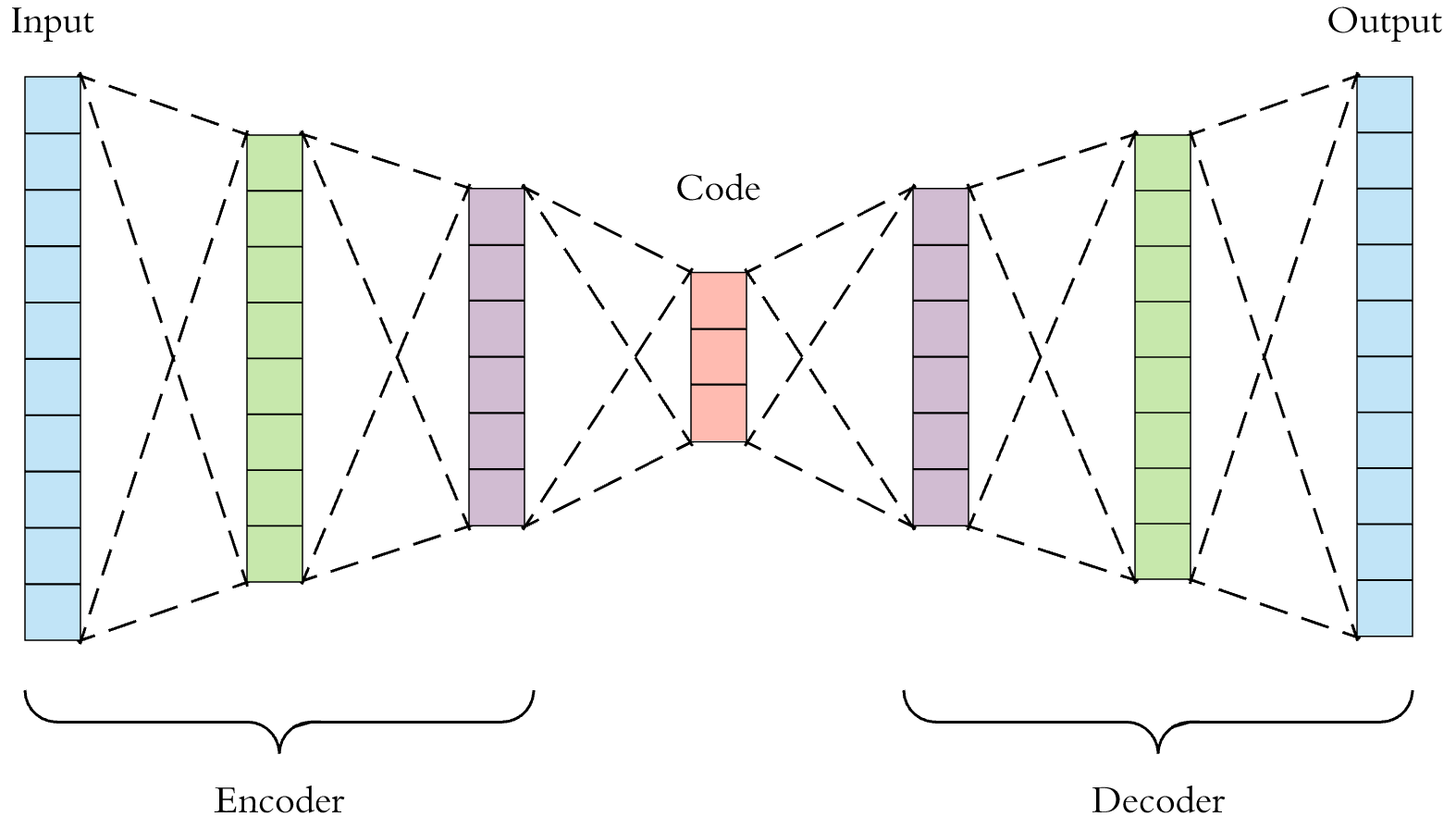
Both LSTM autoencoders and regular autoencoders, encode the input to a compact value, which can then be decoded to reconstruct the original input. While LSTM autoencoders are capable of dealing with sequence as input, regular autoencoders won’t. For example, regular autoencoders will fail to generate a sample sequence for a given input distribution in generative mode whereas LSTM counterpart can. In addition, LSTM can obviously take variable length inputs while regular ones take only fixed size inputs.
example of variable length:
raw_inputs = [
[711, 632, 71],
[73, 8, 3215, 55, 927],
[83, 91, 1, 645, 1253, 927],
]padded_inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
print(padded_inputs)[[ 711 632 71 0 0 0]
[ 73 8 3215 55 927 0]
[ 83 91 1 645 1253 927]]for more details you can check this Masking and padding with Keras link
is a one general LSTM Autoencoder model
is a 3 models creations
-
Encoder
-
Decoder
-
Autoencoder