🤗 Hugging Face | 🤖 ModelScope | Kaggle | 📑 Blog | 📖 Documentation
WeChat (微信) | 🫨 Discord
Visit our Hugging Face or ModelScope organization (click the links above). Search checkpoints with names starting with Qwen2-Math-, and you will find all you need! Enjoy!
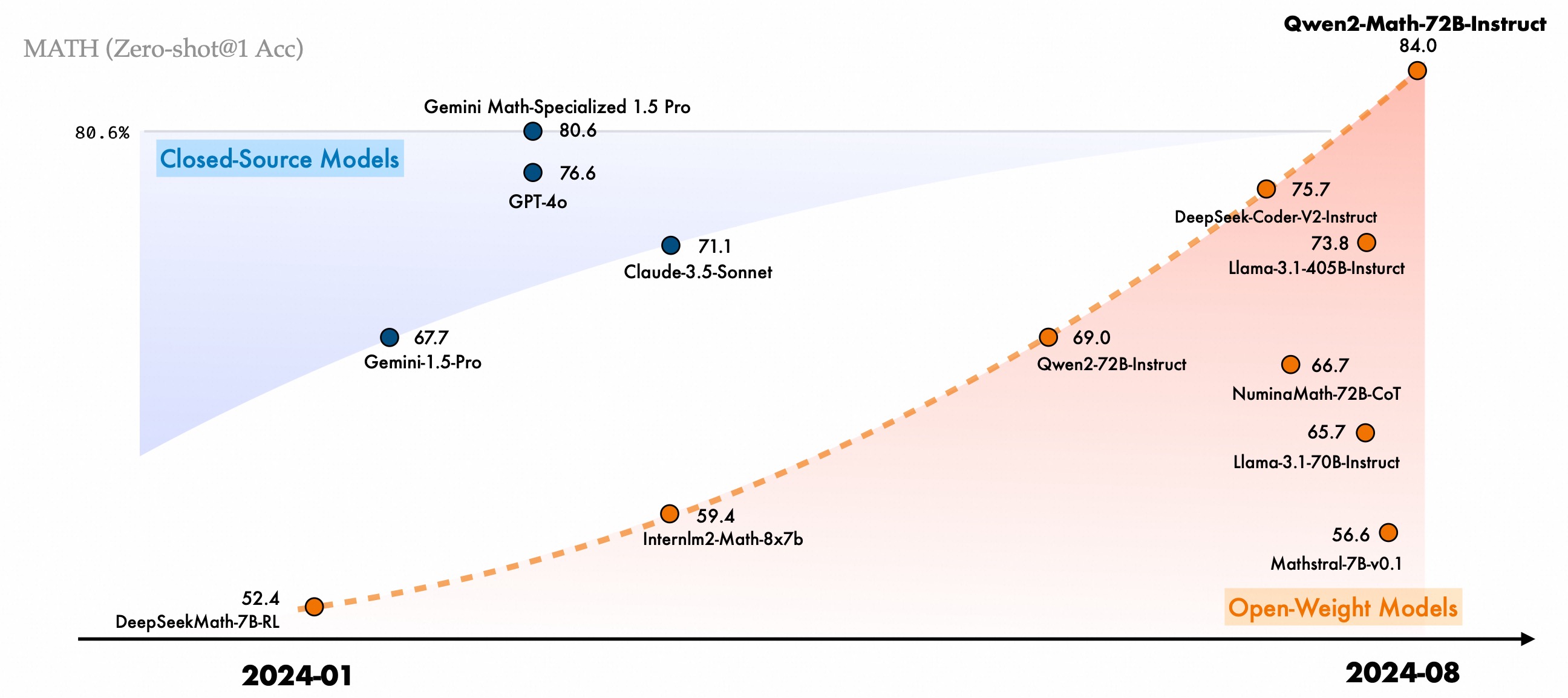
Over the past year, we have dedicated significant effort to researching and enhancing the reasoning capabilities of large language models, with a particular focus on their ability to solve arithmetic and mathematical problems. Today, we are delighted to introduce a series of math-specific large language models of our Qwen2 series, Qwen2-Math, and Qwen2-Math-Instruct-1.5B/7B/72B. Qwen2-Math is a series of specialized math language models built upon the Qwen2 LLMs, which significantly outperforms the mathematical capabilities of open-source models and even closed-source models (e.g., GPT4o). We hope that Qwen2-Math can contribute to the scientific community by solving advanced mathematical problems that require complex, multi-step logical reasoning.
Detailed performance and introduction are shown in this 📑 blog.
🚨 This model mainly supports English. We will release bilingual (English and Chinese) math models soon.
transformers>=4.40.0for Qwen2-Math models. The latest version is recommended.
Warning
For requirements on GPU memory and the respective throughput, see similar results of Qwen2 here.
Important
Qwen2-Math-72B-Instruct is an instruction model for chatting;
Qwen2-Math-72B is a base model typically used for few-shot inference, serving as a better starting point for fine-tuning.
Qwen2-Math can be deployed and inferred in the same way as Qwen2. Here we show a code snippet to show you how to use the chat model with transformers:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2-Math-7B-Instruct"
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Find the value of $x$ that satisfies the equation $4x+5 = 6x+7$."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]We strongly advise users, especially those in mainland China, to use ModelScope. snapshot_download can help you solve issues concerning downloading checkpoints.
We evaluate our Qwen2-Math-Base models on three widely used English math benchmarks GSM8K, Math, and MMLU-STEM. We also evaluate three Chinese math benchmarks: CMATH, GaoKao Math Cloze, and GaoKao Math QA. All evaluations use few-shot chain-of-thought prompting.

We evaluate Qwen2-Math-Instruct on mathematical benchmarks in both English and Chinese. In addition to the widely-used benchmarks, such as GSM8K and Math, we also involve more exams that are much challenging to fully inspect the capabilities of Qwen2-Math-Instruct, such as OlympiadBench, CollegeMath, GaoKao, AIME2024, and AMC2023. For Chinese mathematical benchmarks, we use CMATH, Gaokao (Chinese college entrance examination 2024), and CN Middle School 24 (China High School Entrance Examination 2024).
We report greedy, Maj@8, and RM@8 performance on all benchmarks in the zero-shot setting, except for the multi-choice benchmarks (including MMLU STEM and multiple-choice problems in GaoKao and CN Middle School 24) with a 5-shot setting. Qwen2-Math-Instruct achieves the best performance among models of the same size, with RM@8 outperforming Maj@8, particularly in the 1.5B and 7B models. This demonstrates the effectiveness of our Math Reward Model.

In more complex mathematical competition evaluations such as AIME 2024 and AMC 2023, Qwen2-Math-Instruct also performs well across various settings, including greedy, Maj@64, RM@64, and RM@256.

Our evaluation is adapted from math-evaluation-harness. Feel free to reproduce the results of all instruction models in the Qwen2-Math series with scripts in evaluation.
Before the evaluation, please install the required packages with the following command:
cd latex2sympy
pip install -e .
cd ..
pip install -r requirements.txt
pip install vllm==0.5.1 --no-build-isolation
pip install transformers=4.42.3Strictly following the versions of requirements is essential to reproduce the reported scores.
Evaluate Qwen2-Math-Instruct series model with the following command:
PROMPT_TYPE="qwen-boxed"
OUTPUT_DIR="outputs"
mkdir -p $OUTPUT_DIR
# Qwen2-Math-1.5B-Instruct
export CUDA_VISIBLE_DEVICES="0"
MODEL_NAME_OR_PATH="Qwen/Qwen2-Math-1.5B-Instruct"
bash sh/eval.sh $PROMPT_TYPE $MODEL_NAME_OR_PATH $OUTPUT_DIR
# Qwen2-Math-7B-Instruct
export CUDA_VISIBLE_DEVICES="0"
MODEL_NAME_OR_PATH="Qwen/Qwen2-Math-7B-Instruct"
bash sh/eval.sh $PROMPT_TYPE $MODEL_NAME_OR_PATH $OUTPUT_DIR
# Qwen2-Math-72B-Instruct
export CUDA_VISIBLE_DEVICES="0,1,2,3"
MODEL_NAME_OR_PATH="Qwen/Qwen2-Math-72B-Instruct"
bash sh/eval.sh $PROMPT_TYPE $MODEL_NAME_OR_PATH $OUTPUT_DIRIf you find our work helpful, feel free to give us a citation.
@article{yang2024qwen2,
title={Qwen2 technical report},
author={Yang, An and Yang, Baosong and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Zhou, Chang and Li, Chengpeng and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and others},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}If you are interested in leaving a message to either our research team or product team, join our Discord or WeChat groups!