- Case 1: Scraping a product department at Walmart Canada's website
- Case 2: Processing CSV files to extract clean information
- Run script database_setup
For this case it is only necessary to run the python file: ingestion.py
For this case it is only necessary to run the following command:
scrapy crawl ca_walmartNOTE
If the following error appears :

It is a Bot Protection Page with captcha v2.
For resolving, follow with the following steps:
-
Enter any link that says Crawled (200) and and in the link is the word blocked, for example:
https://www.walmart.ca/blocked?url=L2VuL2lwL2FwcGxlLW1jaW50b3NoLXlvdXItZnJlc2gtbWFya2V0LzYwMDAxOTczNDM1NDI=&uuid=9be49990-5f04-11eb-aafd-23912374fcaf&vid=&g=a' -
You will get a page similar to this:
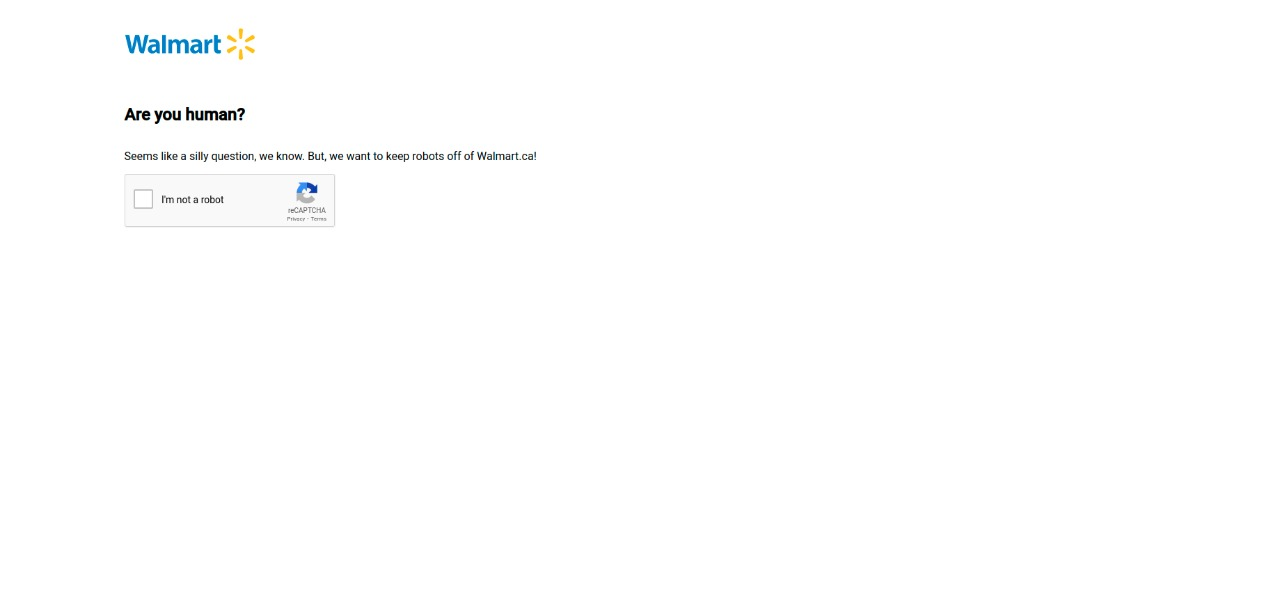 Solve the captcha v2
Solve the captcha v2 -
At this time, walmart has already saved your browser and you will be able to make inquiries to your product pages, in about 5 to 10 minutes you will be able to make inquiries without problems.
Check if the browser is the same as the User-Agent variable in the header that is used for product links::
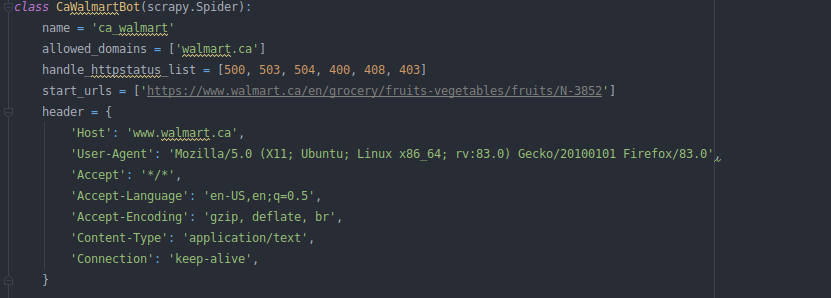
Mozilla has been used by default, so it is recommended that catpcha resolve it in mozilla.


- The issue could be solved with captcha v2 with selenium
- At this time, a SQlite database is used, but it is recommended that in both cases connect to a database in the cloud.