Autoencoders (AE) are neural networks that aim to copy their inputs to their outputs. They work by compressing the input into a latent-space representation and then reconstructing the output from this representation.

An autoencoder consists of two primary components:
Encoder: Learns to compress (reduce) the input data into an encoded representation.
Decoder: Learns to reconstruct the original data from the encoded representation to be as close to the original input as possible.
Bottleneck/Latent space: The layer that contains the compressed representation of the input data.
Reconstruction loss: The method measures how well the decoder is performing, i.e. measures the difference between the encoded and decoded vectors. Lesser the better.
Variational autoencoder(VAE) is a slightly more modern and interesting take on autoencoding.
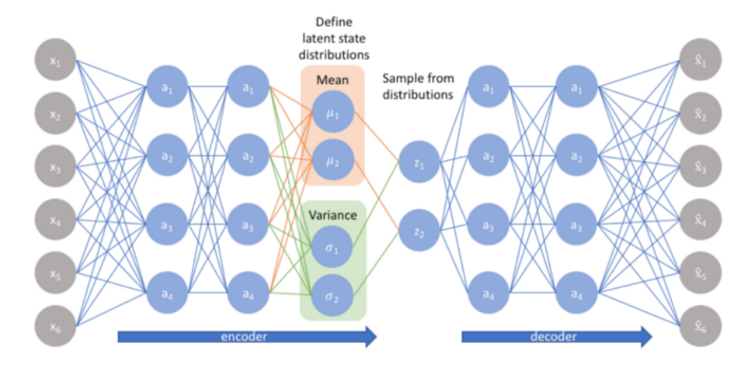
A Variational autoencoder(VAE) assumes that the source data has some sort of underlying probability distribution (such as Gaussian) and then attempts to find the parameters of the distribution. Implementing a variational autoencoder is much more challenging than implementing an autoencoder. The one main use of a variational autoencoder is to generate new data that’s related to the original source data. Now exactly what the additional data is good for is hard to say. A variational autoencoder is a generative system and serves a similar purpose as a generative adversarial network (although GANs work quite differently).
To understand the intuition and mathematics behind these Autoencoders, please check theaidream.com