
I am Sri Sudheera Chitipolu, currently pursuing Masters in Applied Computer Science, NWMSU, USA. Also working as Graduate Assistant for Computer Science Department. Consistently top performer, result oriented with a positive attitude.
I am certified in


![]()

PySpark Text processing is the project on word count from a website content and visualizing the word count in bar chart and word cloud.
https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/6374047784683966/198390003695466/3813842128498967/latest.html (valid for 6 months)
- Databricks Cloud Environment
- Spark Processing Engine
- PySpark API
- Python Programming Language
- Word cloud
The Project Gutenberg EBook of Little Women, by Louisa May Alcott
We'll use the library urllib.request to pull the data into the notebook in the notebook. Then, once the book has been brought in, we'll save it to /tmp/ and name it littlewomen.txt.
import urllib.request
urllib.request.urlretrieve("https://www.gutenberg.org/cache/epub/514/pg514.txt" , "/tmp/littlewomen.txt")Now it's time to put the book away. There are two arguments to the dbutils.fs.mv method. The first point of contention is where the book is now, and the second is where you want it to go. The first argument must begin with file:, followed by the position. The second argument should begin with dbfs: and then the path to the file you want to save. Our file will be saved in the data folder.
dbutils.fs.mv("file:/tmp/littlewomen.txt","dbfs:/data/littlewomen.txt")Transferring the file into Spark is the final move. RDDs, or Resilient Distributed Datasets, are where Spark stores information. As a result, we'll be converting our data into an RDD. Spark is abbreviated to sc in Databrick. When entering the folder, make sure to use the new file location.
LittleWomenRawRDD= sc.textFile("dbfs:/data/littlewomen.txt")Capitalization, punctuation, phrases, and stopwords are all present in the current version of the text. Stopwords are simply words that improve the flow of a sentence without adding something to it. Consider the word "the." The first step in determining the word count is to flatmap and remove capitalization and spaces. The term "flatmapping" refers to the process of breaking down sentences into terms.
LittleWomenMessyTokensRDD = LittleWomenRawRDD.flatMap(lambda line: line.lower().strip().split(" "))The next step is to eliminate all punctuation. This would be accomplished by the use of a standard expression that searches for something that isn't a message. We'll need the re library to use a regular expression.
import re
LittleWomenCleanTokensRDD = LittleWomenMessyTokensRDD.map(lambda letter: re.sub(r'[^A-Za-z]', '', letter))We must delete the stopwords now that the words are actually words. Since PySpark already knows which words are stopwords, we just need to import the StopWordsRemover library from pyspark. Then, from the library, filter out the terms.
from pyspark.ml.feature import StopWordsRemover
remover = StopWordsRemover()
stopwords = remover.getStopWords()
LittleWomenWordsRDD = LittleWomenCleanTokensRDD.filter(lambda PointLessW: PointLessW not in stopwords)To remove any empty elements, we simply just filter out anything that resembles an empty element.
LittleWomenEmptyRemoveRDD = LittleWomenWordsRDD.filter(lambda x: x != "")To process data, simply change the words to the form (word,1), count how many times the word appears, and change the second parameter to that count. The first move is to: Words are converted into key-value pairs.
LittleWomenPairsRDD = LittleWomenEmptyRemoveRDD.map(lambda word: (word,1))Reduce by key in the second stage. The word is the answer in our situation. The first time the word appears in the RDD will be held. If it happens again, the word will be removed and the first words counted.
LittleWomenWordCountRDD = LittleWomenPairsRDD.reduceByKey(lambda acc, value: acc + value)Finally, we'll use sortByKey to sort our list of words in descending order. We'll use take to take the top ten items on our list once they've been ordered. Finally, we'll print our results to see the top 10 most frequently used words in Frankenstein in order of frequency.
LittleWomenResults = LittleWomenWordCountRDD.map(lambda x: (x[1], x[0])).sortByKey(False).take(10)
print(LittleWomenResults)Pandas, MatPlotLib, and Seaborn will be used to visualize our performance.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
source = 'The Project Gutenberg EBook of Little Women, by Louisa May Alcott'
title = 'Top Words in ' + source
xlabel = 'Count'
ylabel = 'Words'
df = pd.DataFrame.from_records(LittleWomenResults, columns =[xlabel, ylabel])
plt.figure(figsize=(10,3))
sns.barplot(xlabel, ylabel, data=df, palette="viridis").set_title(title)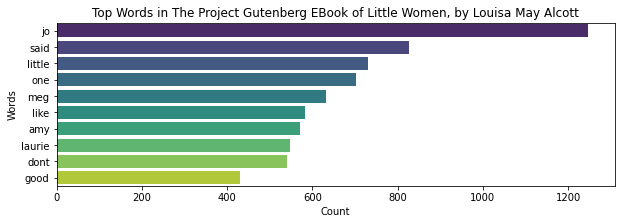
We even can create the word cloud from the word count. We require nltk, wordcloud libraries.
import nltk
import wordcloud
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from wordcloud import WordCloud
class WordCloudGeneration:
def preprocessing(self, data):
# convert all words to lowercase
data = [item.lower() for item in data]
# load the stop_words of english
stop_words = set(stopwords.words('english'))
# concatenate all the data with spaces.
paragraph = ' '.join(data)
# tokenize the paragraph using the inbuilt tokenizer
word_tokens = word_tokenize(paragraph)
# filter words present in stopwords list
preprocessed_data = ' '.join([word for word in word_tokens if not word in stop_words])
print("\n Preprocessed Data: " ,preprocessed_data)
return preprocessed_data
def create_word_cloud(self, final_data):
# initiate WordCloud object with parameters width, height, maximum font size and background color
# call the generate method of WordCloud class to generate an image
wordcloud = WordCloud(width=1600, height=800, max_words=10, max_font_size=200, background_color="black").generate(final_data)
# plt the image generated by WordCloud class
plt.figure(figsize=(12,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud_generator = WordCloudGeneration()
# you may uncomment the following line to use custom input
# input_text = input("Enter the text here: ")
import urllib.request
url = "https://www.gutenberg.org/cache/epub/514/pg514.txt"
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
input_text = response.read().decode('utf-8')
input_text = input_text.split('.')
clean_data = wordcloud_generator.preprocessing(input_text)
wordcloud_generator.create_word_cloud(clean_data)
If we face any error by above code of word cloud then we need to install and download wordcloud ntlk and popular to over come error for stopwords.
pip install wordcloud
pip install nltk
nltk.download('popular')If we want to run the files in other notebooks, use below line of code for saving the charts as png.
plt.savefig('LittleWomen_Results.png')
From the word count charts we can conclude that important characters of story are Jo, meg, amy, Laurie. Good word also repeated alot by that we can say the story mainly depends on good and happiness.