This repo:
(1) covers the implementation of the following ICLR 2020 paper:
"Contrastive Representation Distillation" (CRD). Paper, Project Page.
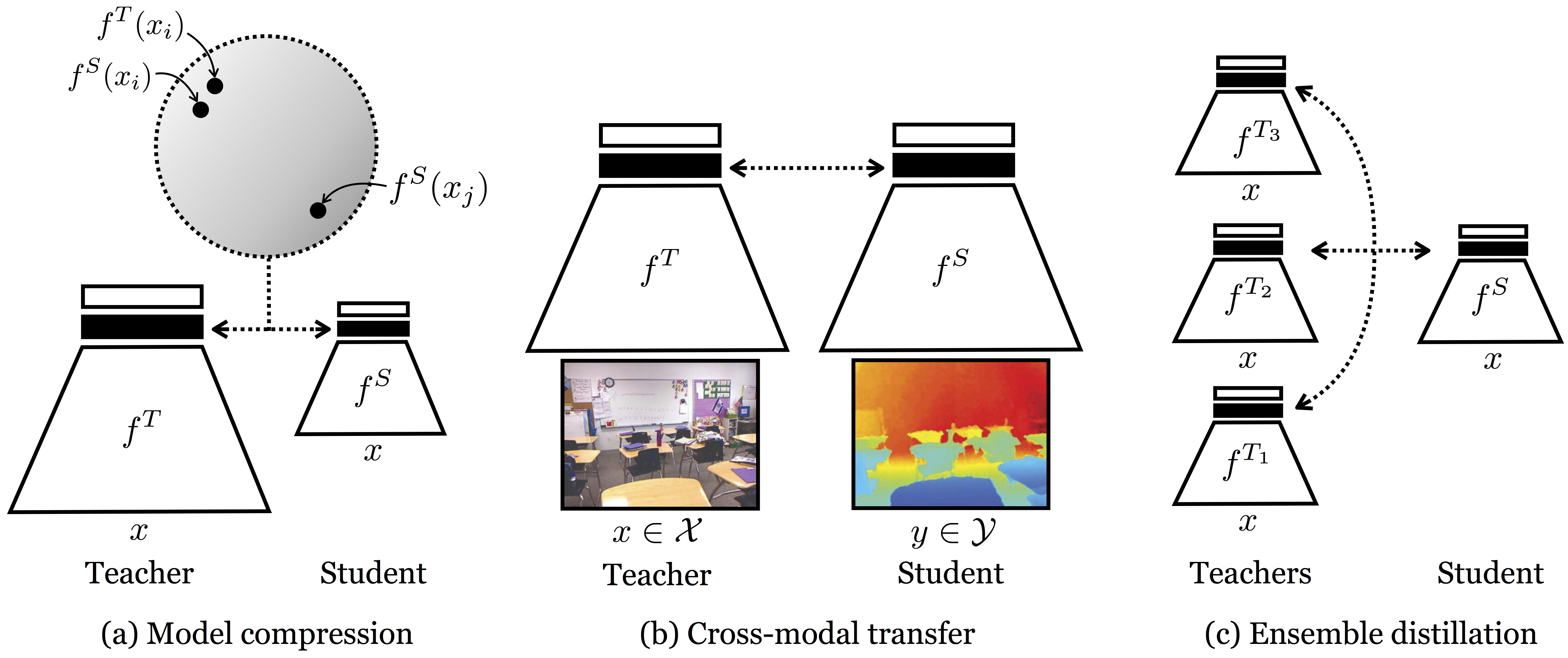
(2) benchmarks 12 state-of-the-art knowledge distillation methods in PyTorch, including:
(KD) - Distilling the Knowledge in a Neural Network
(FitNet) - Fitnets: hints for thin deep nets
(AT) - Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks
via Attention Transfer
(SP) - Similarity-Preserving Knowledge Distillation
(CC) - Correlation Congruence for Knowledge Distillation
(VID) - Variational Information Distillation for Knowledge Transfer
(RKD) - Relational Knowledge Distillation
(PKT) - Probabilistic Knowledge Transfer for deep representation learning
(AB) - Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
(FT) - Paraphrasing Complex Network: Network Compression via Factor Transfer
(FSP) - A Gift from Knowledge Distillation:
Fast Optimization, Network Minimization and Transfer Learning
(NST) - Like what you like: knowledge distill via neuron selectivity transfer
This repo was tested with Ubuntu 16.04.5 LTS, Python 3.5, PyTorch 0.4.0, and CUDA 9.0. But it should be runnable with recent PyTorch versions >=0.4.0
-
Fetch the pretrained teacher models by:
sh scripts/fetch_pretrained_teachers.shwhich will download and save the models to
save/models -
Run distillation by following commands in
scripts/run_cifar_distill.sh. An example of running Geoffrey's original Knowledge Distillation (KD) is given by:python train_student.py --path_t ./save/models/resnet32x4_vanilla/ckpt_epoch_240.pth --distill kd --model_s resnet8x4 -r 0.1 -a 0.9 -b 0 --trial 1where the flags are explained as:
--path_t: specify the path of the teacher model--model_s: specify the student model, see 'models/__init__.py' to check the available model types.--distill: specify the distillation method-r: the weight of the cross-entropy loss between logit and ground truth, default:1-a: the weight of the KD loss, default:None-b: the weight of other distillation losses, default:None--trial: specify the experimental id to differentiate between multiple runs.
Therefore, the command for running CRD is something like:
python train_student.py --path_t ./save/models/resnet32x4_vanilla/ckpt_epoch_240.pth --distill crd --model_s resnet8x4 -a 0 -b 0.8 --trial 1 -
Combining a distillation objective with KD is simply done by setting
-aas a non-zero value, which results in the following example (combining CRD with KD)python train_student.py --path_t ./save/models/resnet32x4_vanilla/ckpt_epoch_240.pth --distill crd --model_s resnet8x4 -a 1 -b 0.8 --trial 1 -
(optional) Train teacher networks from scratch. Example commands are in
scripts/run_cifar_vanilla.sh
Note: the default setting is for a single-GPU training. If you would like to play this repo with multiple GPUs, you might need to tune the learning rate, which empirically needs to be scaled up linearly with the batch size, see this paper
Performance is measured by classification accuracy (%)
- Teacher and student are of the same architectural type.
| Teacher Student |
wrn-40-2 wrn-16-2 |
wrn-40-2 wrn-40-1 |
resnet56 resnet20 |
resnet110 resnet20 |
resnet110 resnet32 |
resnet32x4 resnet8x4 |
vgg13 vgg8 |
|---|---|---|---|---|---|---|---|
| Teacher Student |
75.61 73.26 |
75.61 71.98 |
72.34 69.06 |
74.31 69.06 |
74.31 71.14 |
79.42 72.50 |
74.64 70.36 |
| KD | 74.92 | 73.54 | 70.66 | 70.67 | 73.08 | 73.33 | 72.98 |
| FitNet | 73.58 | 72.24 | 69.21 | 68.99 | 71.06 | 73.50 | 71.02 |
| AT | 74.08 | 72.77 | 70.55 | 70.22 | 72.31 | 73.44 | 71.43 |
| SP | 73.83 | 72.43 | 69.67 | 70.04 | 72.69 | 72.94 | 72.68 |
| CC | 73.56 | 72.21 | 69.63 | 69.48 | 71.48 | 72.97 | 70.71 |
| VID | 74.11 | 73.30 | 70.38 | 70.16 | 72.61 | 73.09 | 71.23 |
| RKD | 73.35 | 72.22 | 69.61 | 69.25 | 71.82 | 71.90 | 71.48 |
| PKT | 74.54 | 73.45 | 70.34 | 70.25 | 72.61 | 73.64 | 72.88 |
| AB | 72.50 | 72.38 | 69.47 | 69.53 | 70.98 | 73.17 | 70.94 |
| FT | 73.25 | 71.59 | 69.84 | 70.22 | 72.37 | 72.86 | 70.58 |
| FSP | 72.91 | N/A | 69.95 | 70.11 | 71.89 | 72.62 | 70.23 |
| NST | 73.68 | 72.24 | 69.60 | 69.53 | 71.96 | 73.30 | 71.53 |
| CRD | 75.48 | 74.14 | 71.16 | 71.46 | 73.48 | 75.51 | 73.94 |
- Teacher and student are of different architectural type.
| Teacher Student |
vgg13 MobileNetV2 |
ResNet50 MobileNetV2 |
ResNet50 vgg8 |
resnet32x4 ShuffleNetV1 |
resnet32x4 ShuffleNetV2 |
wrn-40-2 ShuffleNetV1 |
|---|---|---|---|---|---|---|
| Teacher Student |
74.64 64.60 |
79.34 64.60 |
79.34 70.36 |
79.42 70.50 |
79.42 71.82 |
75.61 70.50 |
| KD | 67.37 | 67.35 | 73.81 | 74.07 | 74.45 | 74.83 |
| FitNet | 64.14 | 63.16 | 70.69 | 73.59 | 73.54 | 73.73 |
| AT | 59.40 | 58.58 | 71.84 | 71.73 | 72.73 | 73.32 |
| SP | 66.30 | 68.08 | 73.34 | 73.48 | 74.56 | 74.52 |
| CC | 64.86 | 65.43 | 70.25 | 71.14 | 71.29 | 71.38 |
| VID | 65.56 | 67.57 | 70.30 | 73.38 | 73.40 | 73.61 |
| RKD | 64.52 | 64.43 | 71.50 | 72.28 | 73.21 | 72.21 |
| PKT | 67.13 | 66.52 | 73.01 | 74.10 | 74.69 | 73.89 |
| AB | 66.06 | 67.20 | 70.65 | 73.55 | 74.31 | 73.34 |
| FT | 61.78 | 60.99 | 70.29 | 71.75 | 72.50 | 72.03 |
| NST | 58.16 | 64.96 | 71.28 | 74.12 | 74.68 | 74.89 |
| CRD | 69.73 | 69.11 | 74.30 | 75.11 | 75.65 | 76.05 |
If you find this repo useful for your research, please consider citing the paper
@inproceedings{tian2019crd,
title={Contrastive Representation Distillation},
author={Yonglong Tian and Dilip Krishnan and Phillip Isola},
booktitle={International Conference on Learning Representations},
year={2020}
}
For any questions, please contact Yonglong Tian (yonglong@mit.edu).
Thanks to Baoyun Peng for providing the code of CC and to Frederick Tung for verifying our reimplementation of SP. Thanks also go to authors of other papers who make their code publicly available.