This Project is for course: INF 1340 - Programming for Data Science at University of Toronto (Faculty of Information), supervised by Dr. Maher Elshakankiri
This project involves creating a text analyzer using python programming to analyze text files and gain insights to the file. The program consists of 13 functions plus the main, two of them are to read and write the input and output files, while the remaining 11 functions perform different types of analysis on the input text file.
This program will prompt the user to enter the name of the input file which they wish to analyze (ensure that the input file is in the same directory as the Midterm.py file). The user will then be asked to write the name of the output file to which the results will be displayed. The results of this program will be displayed on the screen, as well as be saved in an output file. Additionally, the output of the count_char functions will be saved in a csv file as well as in the output file and displayed on the screen.
Some of the features of this program are:
- Count the number of words in the file
- Count the number of sentences in the file (delimiters set as period and question mark)
- The number of times each word occurs (frequency) in a document
- The frequency of a specific word, which the user will input
- Top 10 most common words in the file
- TF = Term frequency of each word in the document. Term frequency is the ratio of the number of times the word appears in a document compared to the total number of words in that document. It is an indicator of the term's importance in a given text.
- The average number of sentences in a file
- The longest word in the input file
- The length of the longest word in the input file
- The shortest word in the input file
- The frequency of each character in the input file
pip3 install collections
pip3 install scikit-learn
pip3 install pandas
pip3 install nltk
nltk.download('punkt')
nltk.download('stopwords')
Any additional library that is used in this program and needs to be installed on a local machine, can be installed using the format:
pip3 install <libraryName>
Note: This program will run best on python3. If this program is being run on python2, you might run into syntax errors, and might get some potential fomatting issues.
-
Ensure you have python3 installed on your local machine
-
Open any IDE of your choice
-
Ensure all necessary libraries are installed (refer to the Installation section above)
-
Place your input text file in the same directory as the program
-
To run the program, enter the following command:
python3 Midterm.py
- After running the program, do the following when prompted:
- Enter the input text file name
- Enter the output file name
- Enter the word whose frequency you want to know (number of times the specified word occurs in the document)
Note: In case of any unexpected errors/or having trouble running the program, please feel free to reach out to me at: s.umar@mail.utoronto.ca
The output on the screen:



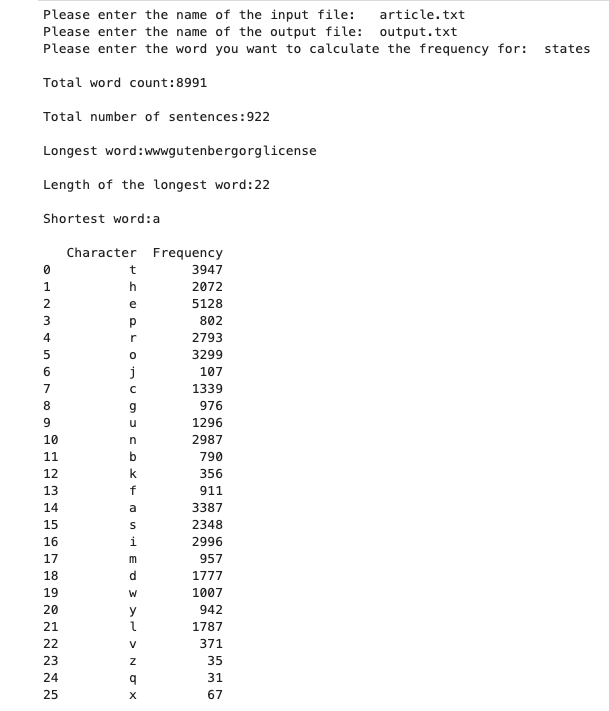


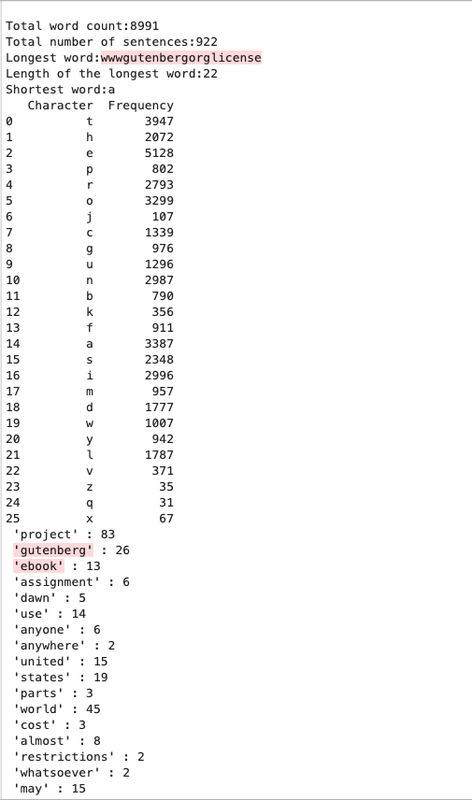
Output.txt - The output file (this screenshot does not contain the entire content of the file)
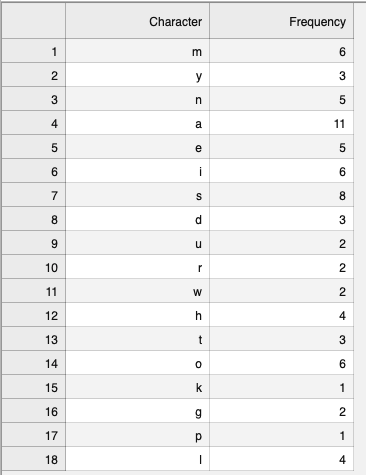
Output of alphabet_frequency.csv
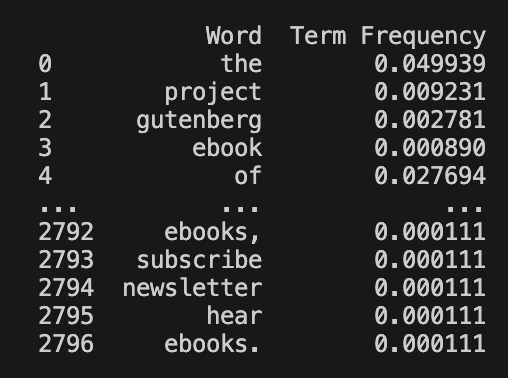
-
https://stackoverflow.com/questions/265960/best-way-to-strip-punctuation-from-a-string
-
https://www.geeksforgeeks.org/understanding-tf-idf-term-frequency-inverse-document-frequency/
-
https://stackoverflow.com/questions/49277926/python-tf-idf-algorithm
-
https://www.geeksforgeeks.org/python-program-for-most-frequent-word-in-strings-list/
-
https://stackoverflow.com/questions/14622835/split-string-on-or-keeping-the-punctuation-mark