- Vision Language Models
- Vision-Language Pretraining
- ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks [NeurIPS 2019]
- LXMERT: Learning Cross-Modality Encoder Representations from Transformers [EMNLP 2019]
- VisualBERT: A Simple and Performant Baseline for Vision and Language [arXiv 2019/08, ACL 2020]
- VL-BERT: Pre-training of Generic Visual-Linguistic Representations [ICLR 2020]
- Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training [AAAI 2020]
- Unified Vision-Language Pre-Training for Image Captioning and VQA [AAAI 2020]
- UNITER: Learning Universal Image-text Representations [ECCV 2020]
- Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks [arXiv 2020/04, ECCV 2020]
- Learning Transferable Visual Models From Natural Language Supervision [OpenAI papers 2021/01]
- Video-Language Pretraining
- VideoBERT: A Joint Model for Video and Language Representation Learning [ICCV 2019]
- Multi-modal Transformer for Video Retrieval [ECCV 2020]
- HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training [EMNLP 2020]
- UniVL: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
- Image-Text Retrieval & Matching
- Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers [CVPR 2021]
- Analysis
- 12-in-1: Multi-Task Vision and Language Representation Learning [CVPR 2020]
- Are we pretraining it right? Digging deeper into visio-linguistic pretraining
- Behind the Scene: Revealing the Secrets of Pre-trained Vision-and-Language Models
- Adaptive Transformers for Learning Multimodal Representations [ACL 2020]
- Data, Architecture, or Losses: What Contributes Most to Multimodal Transformer Success? [TACL 2021]
- Survey
- Pre-trained Models for Natural Language Processing: A Survey [arXiv 2020/03]
- A Survey on Contextual Embeddings [arXiv 2020/03]
- Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods [arXiv 2019]
- Deep Multimodal Representation Learning: A Survey [arXiv 2019]
- Pre-trained models for natural language processing: A survey [arXiv 2020]
- A Survey on Visual Transformer [arXiv 2020/12]
- Platforms
- Vision-Language Pretraining
- Transformer
- Efficient Transformers
- Performer: Rethinking Attention with Performers [arXiv 2020/09, Under review of ICLR 2021]
- Linformer: Self-Attention with Linear Complexity [arXiv 2020/06]
- Linear Transformer: Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention [ICML 2020]
- Synthesizer: Neural Speech Synthesis with Transformer Network [AAAI 2019]
- Sinkhorn Transformer: Sparse Sinkhorn Attention [ICML 2020]
- Reformer: The Efficient Transformer [ICLR 2020]
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context [arXiv 2019/06]
- Compressive Transformers for Long-Range Sequence Modelling [ICLR 2020]
- Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks [ICML 2019]
- Longformer: The Long-Document Transformer [arXiv 2020/04]
- Routing Transformer: Efficient Content-Based Sparse Attention with Routing Transformers [arXiv 2020/10]
- Big Bird: Transformers for Longer Sequences [NIPS 2020]
- Etc: Encoding long and structured data in transformers [EMNLP 2020]
- Memory Compressed: Generating Wikipedia by Summarizing Long Sequences [ICLR 2018]
- Blockwise Transformer: Blockwise Self-Attention for Long Document Understanding [arXiv 2020/10]
- Image Transformer [ICML 2018]
- Sparse Transformer: Generating Long Sequences with Sparse Transformers [arXiv 2019/04]
- Axial Transformer: Axial Attention in Multidimensional Transformers [arXiv 2019/12]
- Fastformer: Additive Attention Can Be All You Need [arXiv 2021/08]
- Image Transformers
- Transformer GAN
- Transformer Visualizations
- Transformer Internal Essence
- Survey
- Efficient Transformers
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks [NeurIPS 2019]
[paper] [code] Facebook AI Research
-
Architecture: Two stream 🔃 co-attentional transformer layers
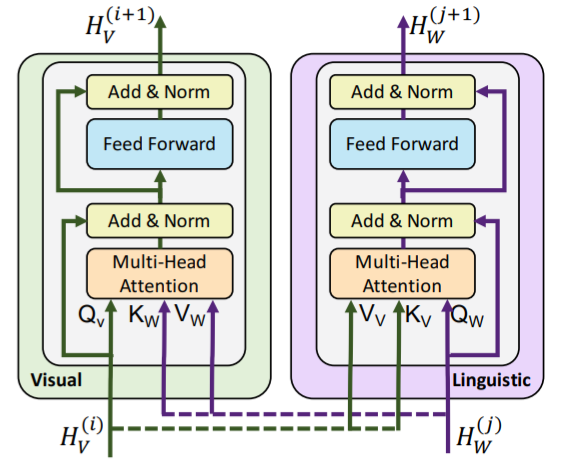
-
Pretrain dataset: Conceptual Captions (~3.3M)
-
Pretrain Tasks

- predicting the semantics of masked words and image regions given the unmasked inputs (Masked Multi-modal Modelling)
image: Predict the semantic classes distribution using image input/output with detection model, then minimize KL divergence between these two distributions.
text: Same as BERT.
- predicting whether an image and text segment correspond (Multi-modal Alignment) with [IMG] and [CLS] output
-
Image feature (Fast R-CNN)
- <image coordinates (4), area fraction, visual feature> from pretrained object detection network
- projected to match the visual feature
-
Text feature Google's WordPiece tokenizer


[paper] [code] The University of North Carolina
-
Architecture: Two stream --- Object relationship encoder (Image), language encoder (Text), cross-modality encoder.
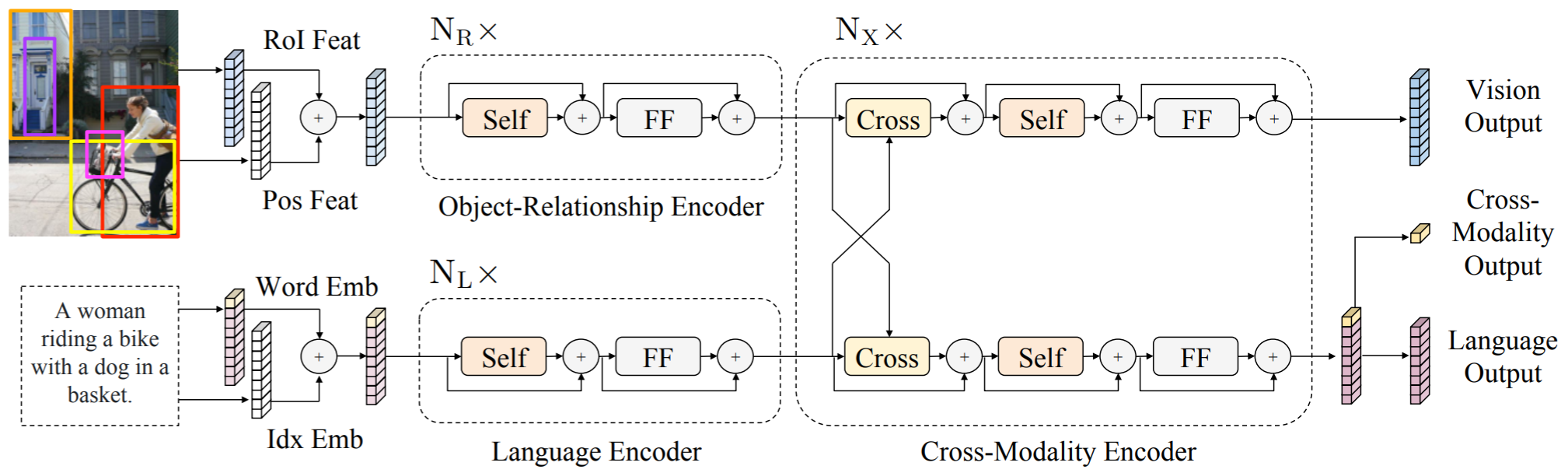
-
Pretrain dataset: COCO + Visual Genome (9.18 M)
-
Pretrain Tasks
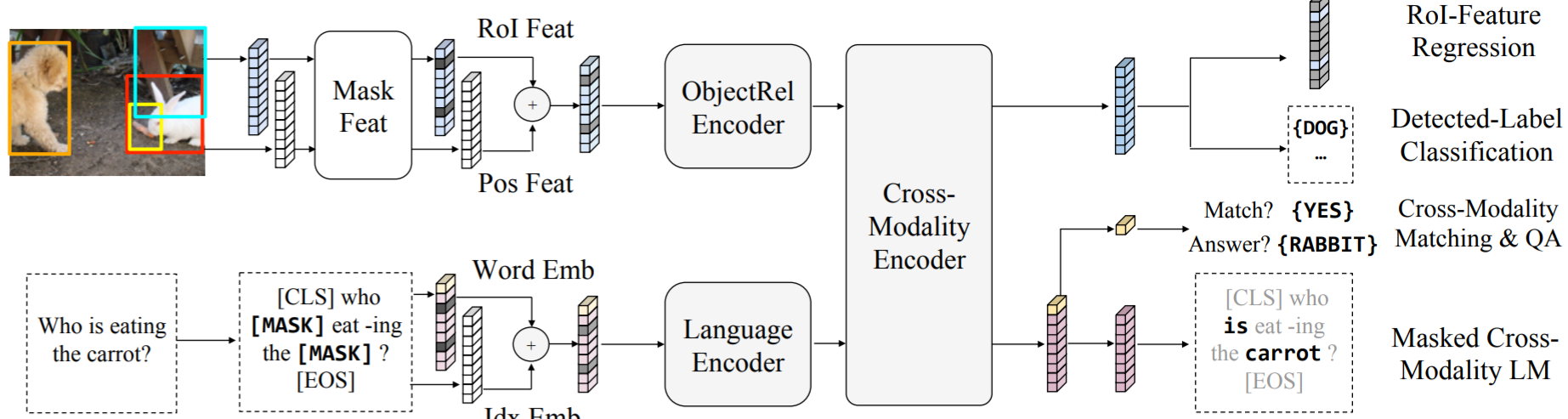
- MLM, Masked Object Prediction (MOP) [feature regression and label classification], Cross-modality Matching with only [CLS] output, Image Question Answering
-
Image feature (Fast R-CNN)
- <bounding box coordinates, 2048-d region-of-interest>
- projection
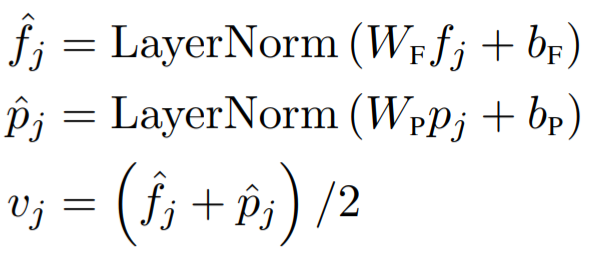
-
Text feature





- Architecture: Single stream BERT
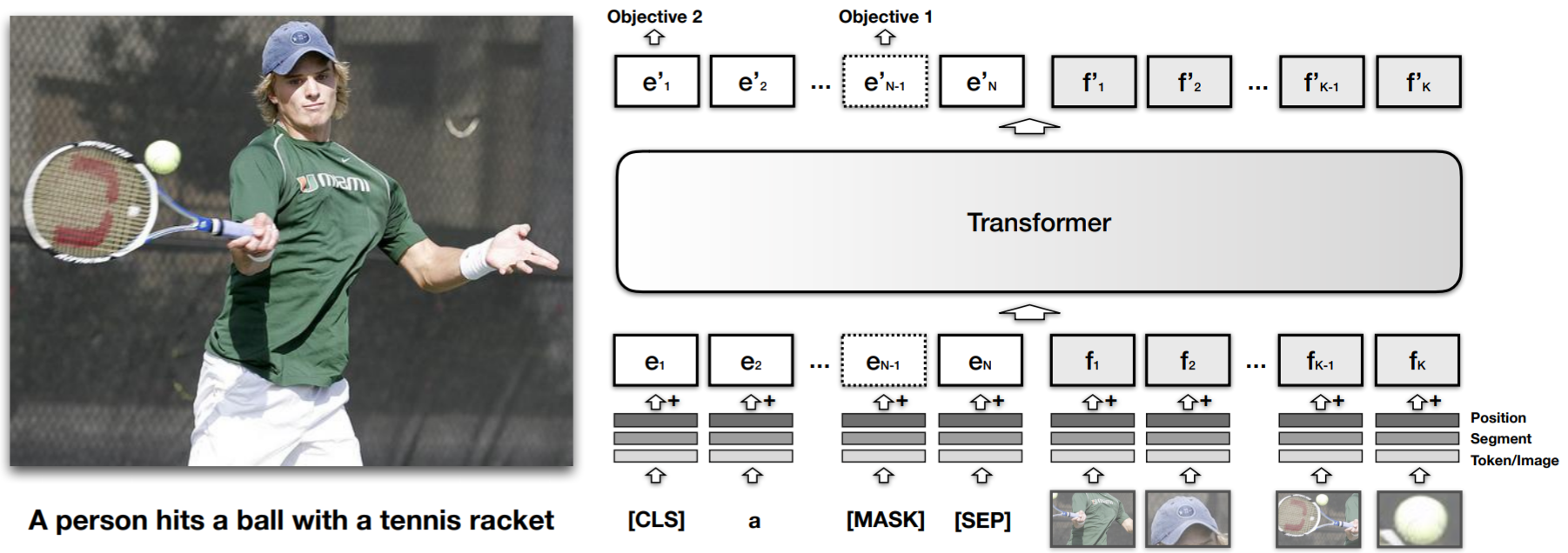
- Pretrain dataset: COCO (100k)
- Pretrain tasks:
- Task-Agnostic Pretraining
- MLM with only text masked
- Sentence-image matching (Cross-modality Matching) with only [CLS] output
- Task-Specific Pretraining using MLM with task-specific dataset, which help adapting to the new target domain.
- Features
- Image feature (Fast R-CNN) visual feature representation: bounding region feature + segment embedding + position embedding
- Text feature: same as BERT

-
Architecture: Single stream BERT
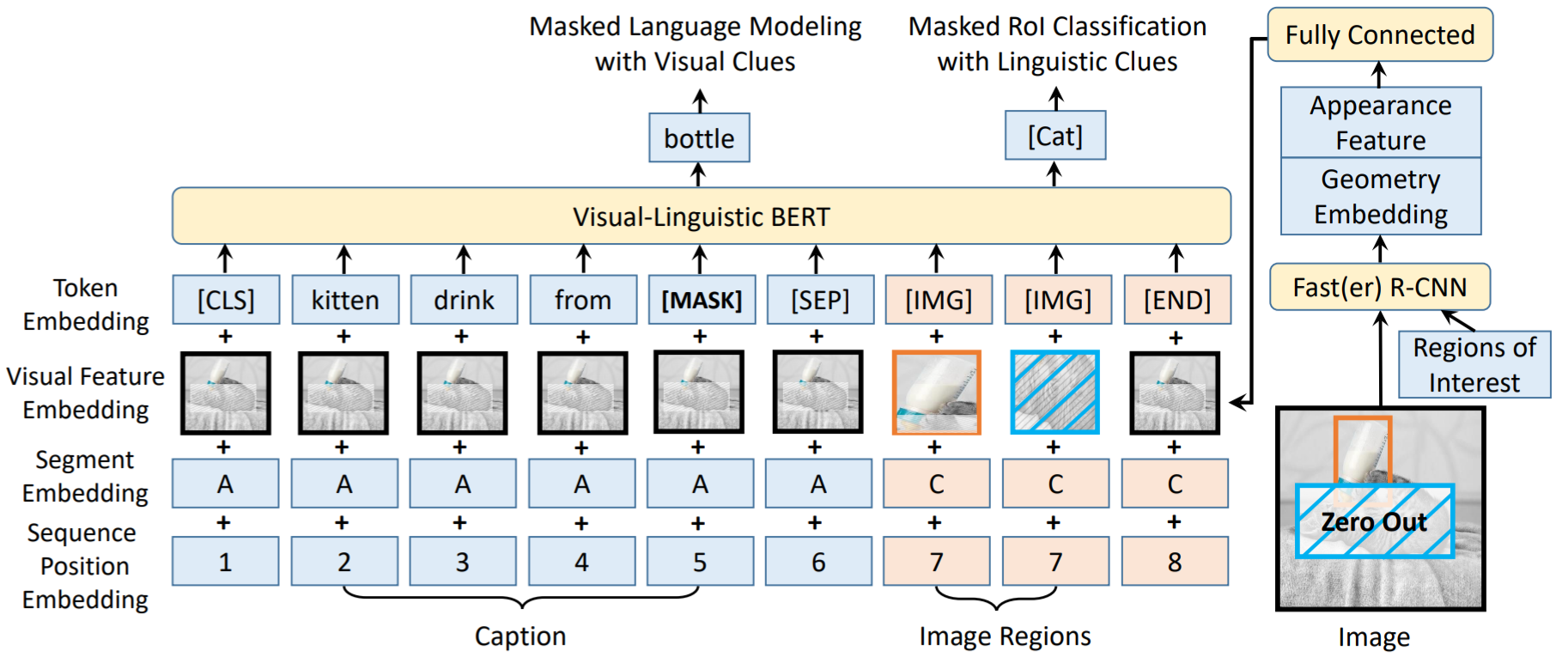
-
Pretrain dataset: Conceptual Captions (3.3M) for visual-linguistic & BooksCorpus, English Wikipedia for pure text corpus
-
Pretrain Tasks
- MLM, Masked RoI Classification with Linguistic Clues
- They claim that Cross-modality Matching is of no use.
-
Features
-
Visual Feature Embedding (Fast R-CNN)
-
visual appearance embedding: 2048-d feature For Non-visual elements, they're obtained by RoI covering the whole input image.
-
visual geometry embedding:
to 2048-d representation by computing sine and cosine of different wavelengths according to "Relation networks for object detection"
-
Token Embedding
-
WordPiece Embedding For Visual elements, a special [IMG] is assigned.
-
Segment Embedding: Learnable
-
Sequence Position Embedding: Learnable
-

-
Architecture: Single stream BERT
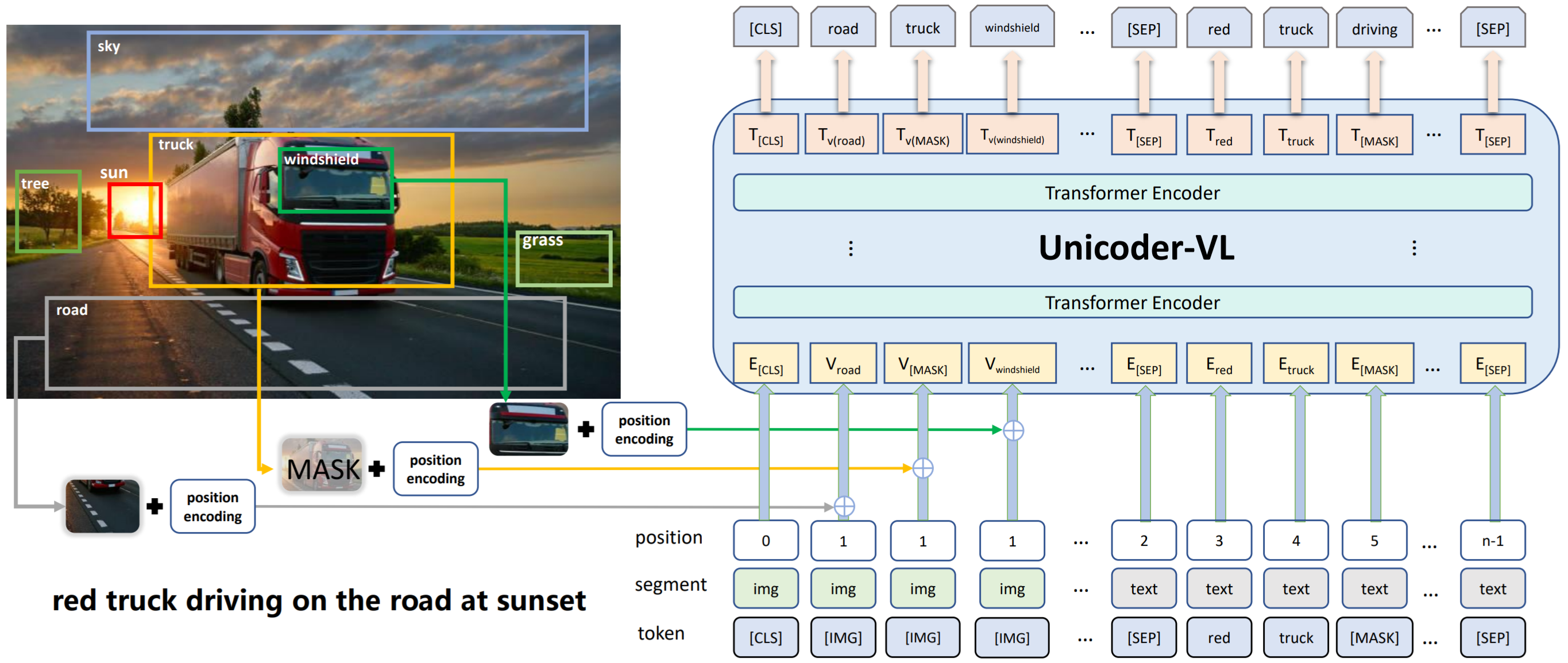
-
Pretrain dataset: Conceptual Captions (3M) + SUB Captions (0.8M)
-
Pretrain tasks
MLM + Masked Object Classification+ Visual-linguistic Matching (Cross-modality Matching) with only [CLS] output
-
Features
- Image feature (Fast R-CNN)
- [IMG] token + segment embedding + position embedding + next term
-
, visual feature --separately--> embedding space using FC, then added up
- Text feature: same as BERT

[code], (VLP)
arXiv 2020/01 [paper]
ICLR 2021 submission. [paper]
[paper] [code] Multi-task Learning
arXiv 2020/04 [paper] In-depth Analysis
arXiv 2020/05, ECCV 2020 Spotlight [paper] In-depth Analysis
[paper] Adaptive Transformer Analysis
Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods [arXiv 2019]
https://github.com/facebookresearch/mmf
-
Fixed Patterns
- Blockwise Patterns
- Strided Patterns
- Compressed Patterns
-
Combination of Patterns
Combining two or more distinct access patterns.
-
Learnable Patterns
Reformer: The Efficient Transformer [ICLR 2020]
Opposite to the Fixed Patterns, learnable patterns aim to learn the access pattern in a data-driven fashion.
-
Memory
Longformer: The Long-Document Transformer [arXiv 2020/04]
Leverage a side memory module to access multiple tokens at once.
-
Low-Rank Methods
Linformer: Self-Attention with Linear Complexity [arXiv 2020/06]
Leverage low-rank approximations of the self-attention matrix.
-
Kernels
View the attention mechanism through kernelization, which enable clever mathematical re-writing of self-attention mechanism to avoid explicitly computing the N*N matrix. Can be view as low-rank method.
-
Recurrence
A natural extension to the blockwise method is to connect these blocks via recurrence.
[paper] [code] Google & University of Cambridge & DeepMind & Alan Turing Institute

- Tasks: Natural language understanding and downstream tasks.
- Contribution: Projecting (N, d) Key and Value to (k, d).
- Complexity: O(n)
- Restrictions:
- Cause mixing of sequence information, which would make it non-trivial to maintain causal masking or prevent past-future information mixing.
Linear Transformer: Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention [ICML 2020]
[paper] [code] Idiap Research Institute
[paper] [code] UCB & Google Research

-
Tasks: Machine translation
-
Contribution:
-
Locality Sensitive Hashing Attention (LSHA)
- Weight approximation
For each query
, the attention is computed as:
.
As softmax:
, the several largest term can roughly approximate the value.
[10, 7, 1, 0 ,2] ---softmax---> [95%, 4.7%, 0.012%, 0.0043%, 0.032%]
- Shared-QK Transformer
For each k, q, let
Does not affect transformer performance.
- LSH bucket
Split queries and keys into different buckets. Each query only attend to keys in the same bucket.
-
-
Complexity: ref to the Table 3 of paper.
[paper] [code] CMU, Google Brain
[paper] University of Oxford
[paper] [code] Allen Institute for Artificial Intelligence

- Tasks: Language Model, such as summarization, question answering...
- Contribution:
-
Sliding windows attention
Applying different w for different layer. They increase the receptive field as the model goes deeper.
-
Dilated sliding window
In multi-head attention, they use mixed sliding windows. The dilated sliding is used to focus on the longer context, while un-dilated sliding is used to focus on local context.
-
Global+sliding window
They add global attention in some specific points for different tasks. [CLS] for classification task, "Whole Question Sentence" for QA task.
-
- Complexity: O(kn) for Local Attention, where k is the window size.
Routing Transformer: Efficient Content-Based Sparse Attention with Routing Transformers [arXiv 2020/10]
[paper] [code] Google Research
[paper] Google Research
[paper] [code] Google Research
[paper] [code] ** Google Brain

- Tasks: Text generation with WIKI as input.
- Contribution:
- Local Attention
- Memory-compressed Attention
- Complexity: O(bn) for Local Attention, where b is the block number. O(n*n/k) for Memory-compressed Attention, where k is the
nn.Conv1dkernel size and strides.
[paper] [code] Tsinghua University, FAIR
[paper] [code1] [code2] Google Brain, UCB, Google AI
![]()
- Tasks: Image Generation and Super Resolution
- Contribution:
- Query Block split & 2 Local Attention
- Complexity: O(nm), where n is the length of flatted image, m is the memory length.
- Restrictions
- Only focus on local neighborhood, which can be a issue where global information is required to solve a task.
- The constant term:
,
is introduced to be a extra hyper-parameter.
[paper] [code] UCB, Google Brain
[paper] [code] Tsinghua University, MSRA
ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [Under review of ICLR 2021]
[paper] [code1] [code2] Google
-
Architecture: Transformer-only
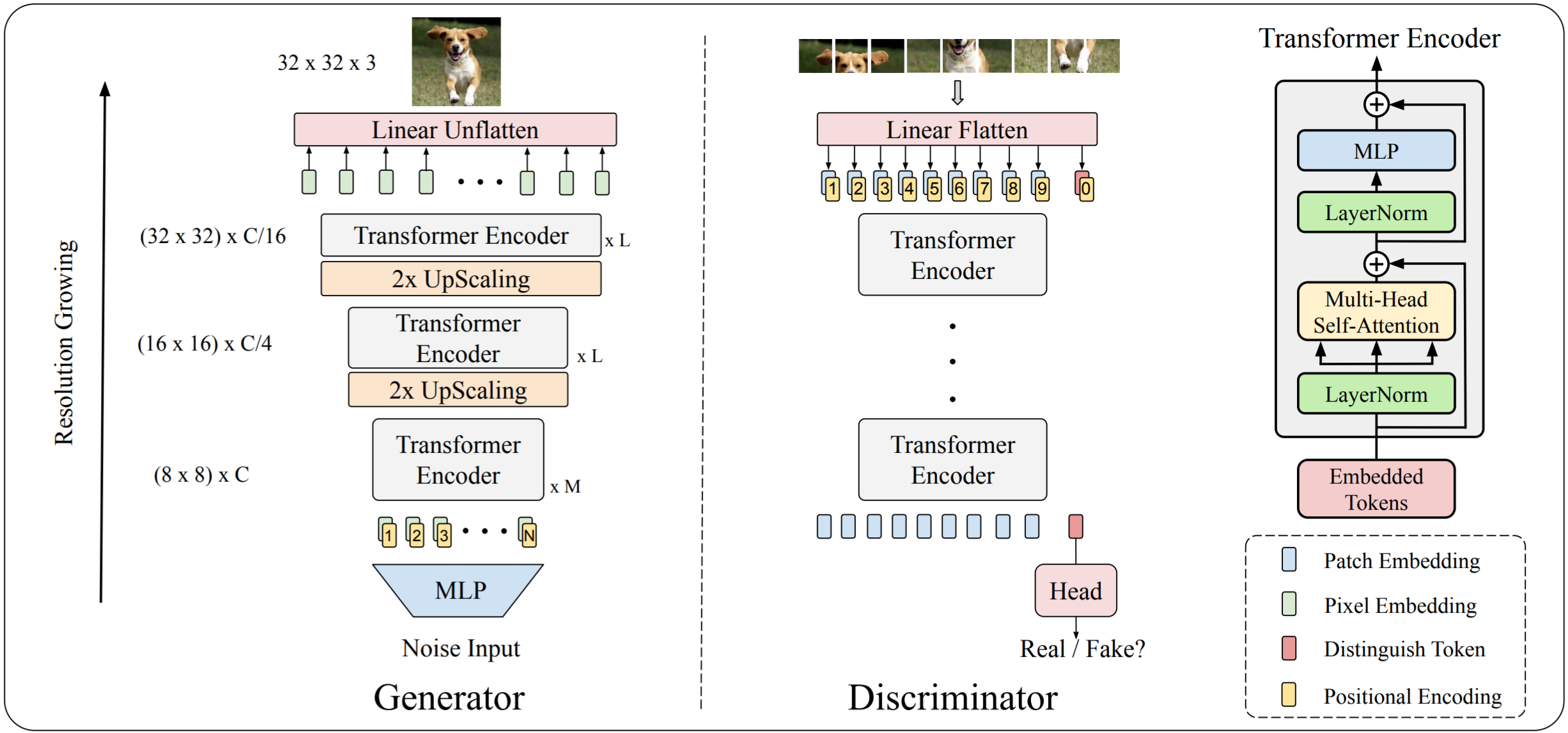
- Up-sampling in Generator: pixelshuffle module from "Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network (CVPR 2016)"
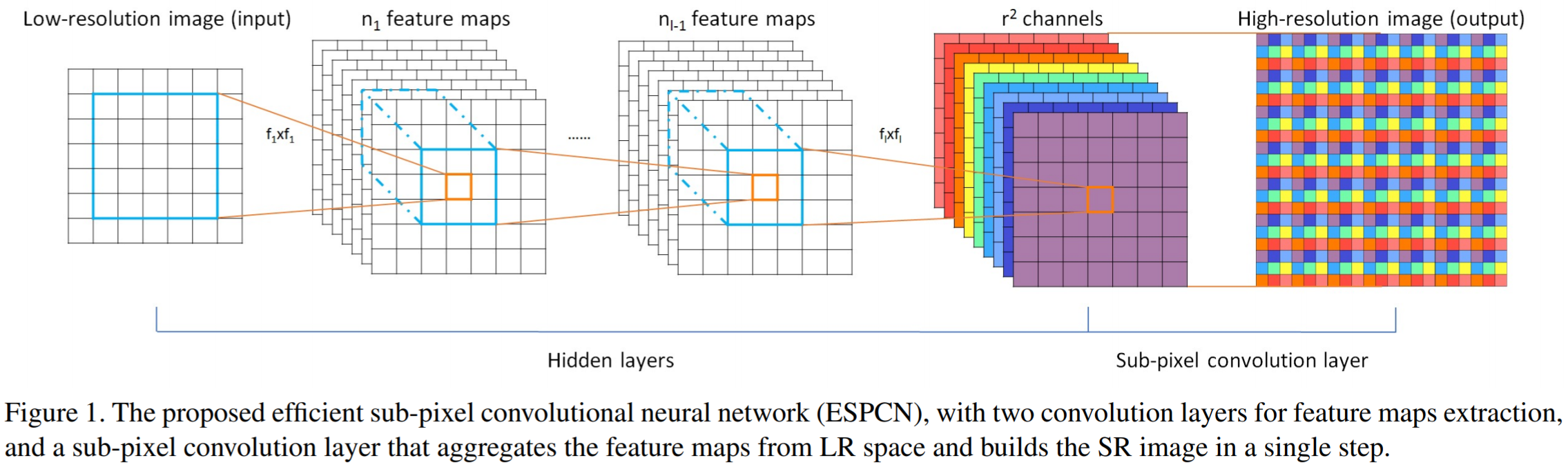
-
Tricks
-
Data augmentation
-
Super-resolution co-training
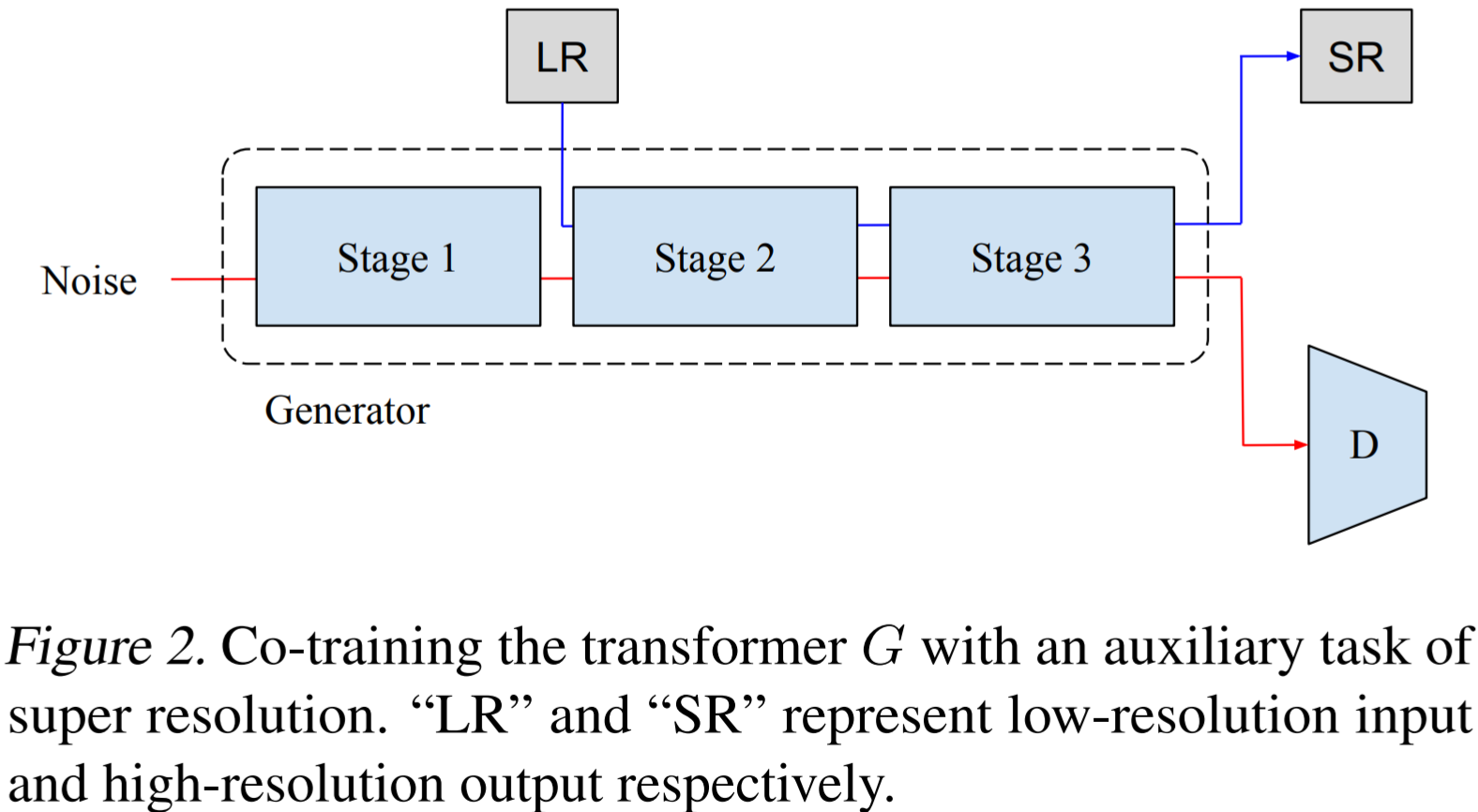
-
Locality-Aware Initialization for Self-Attention
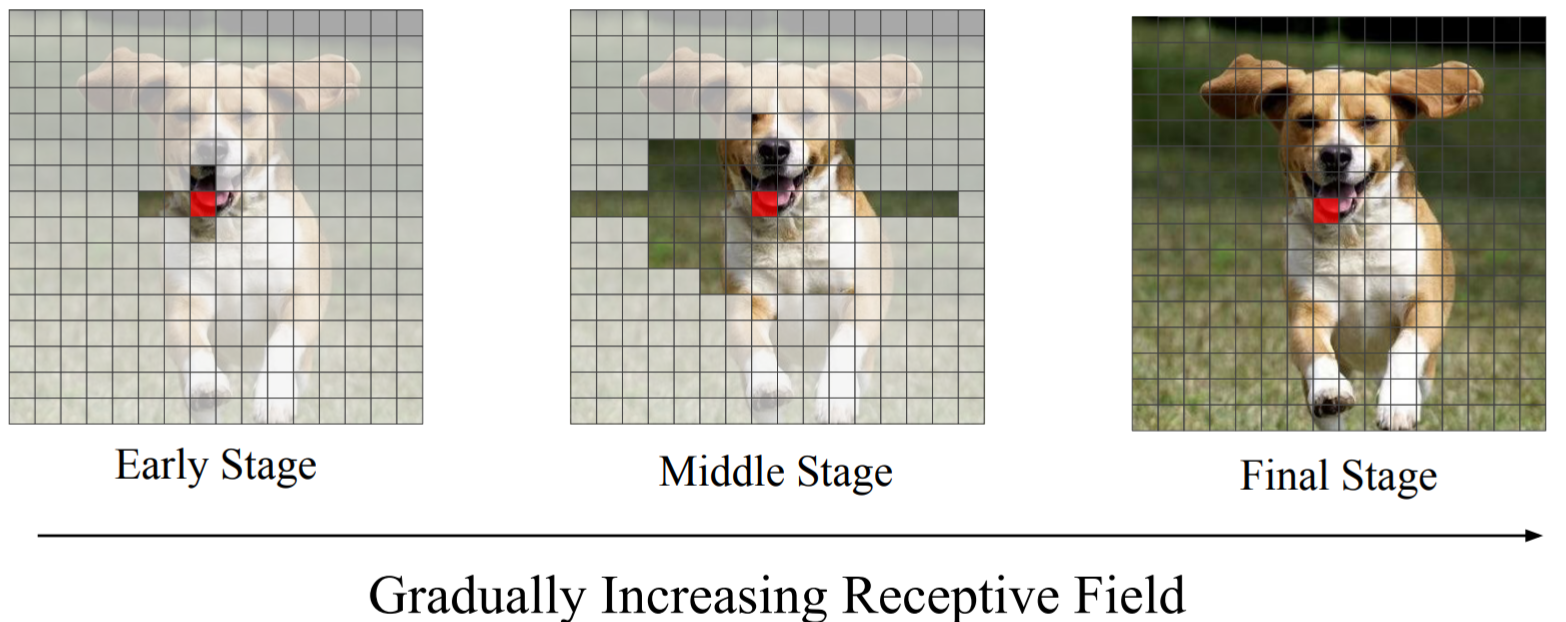
-
Ablations
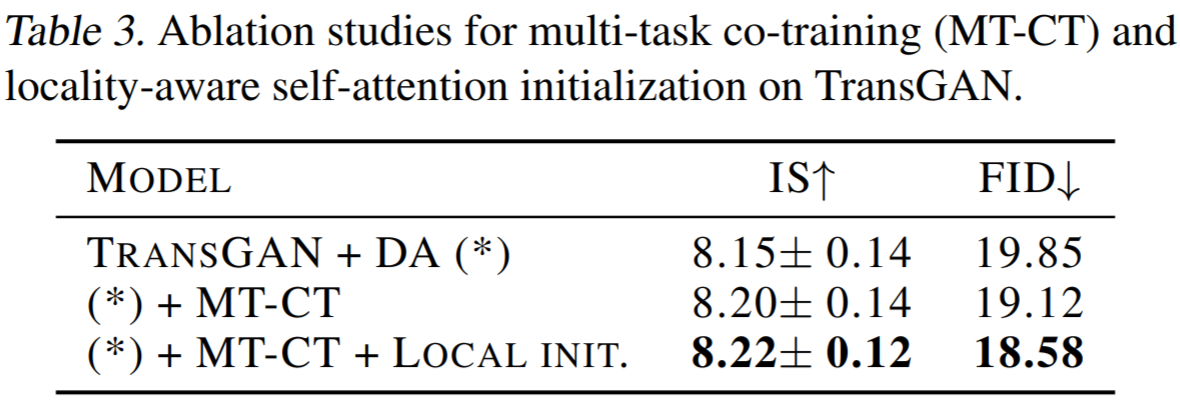
-
-
Results
-
Scaling up model
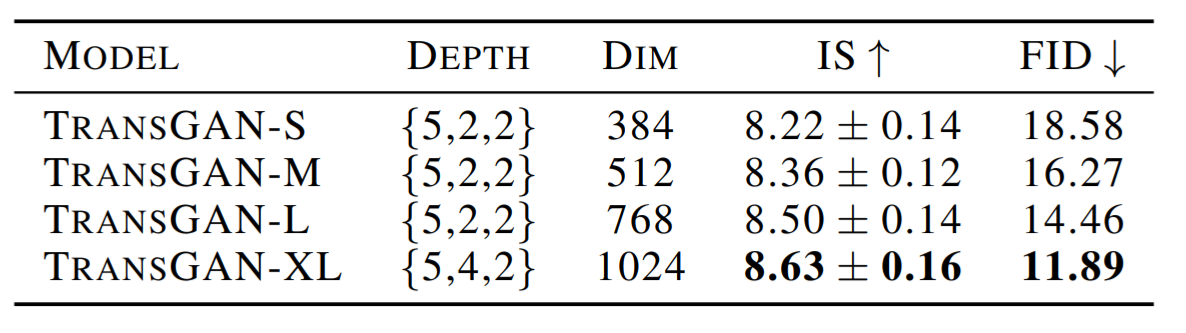
-
Comparison with other model
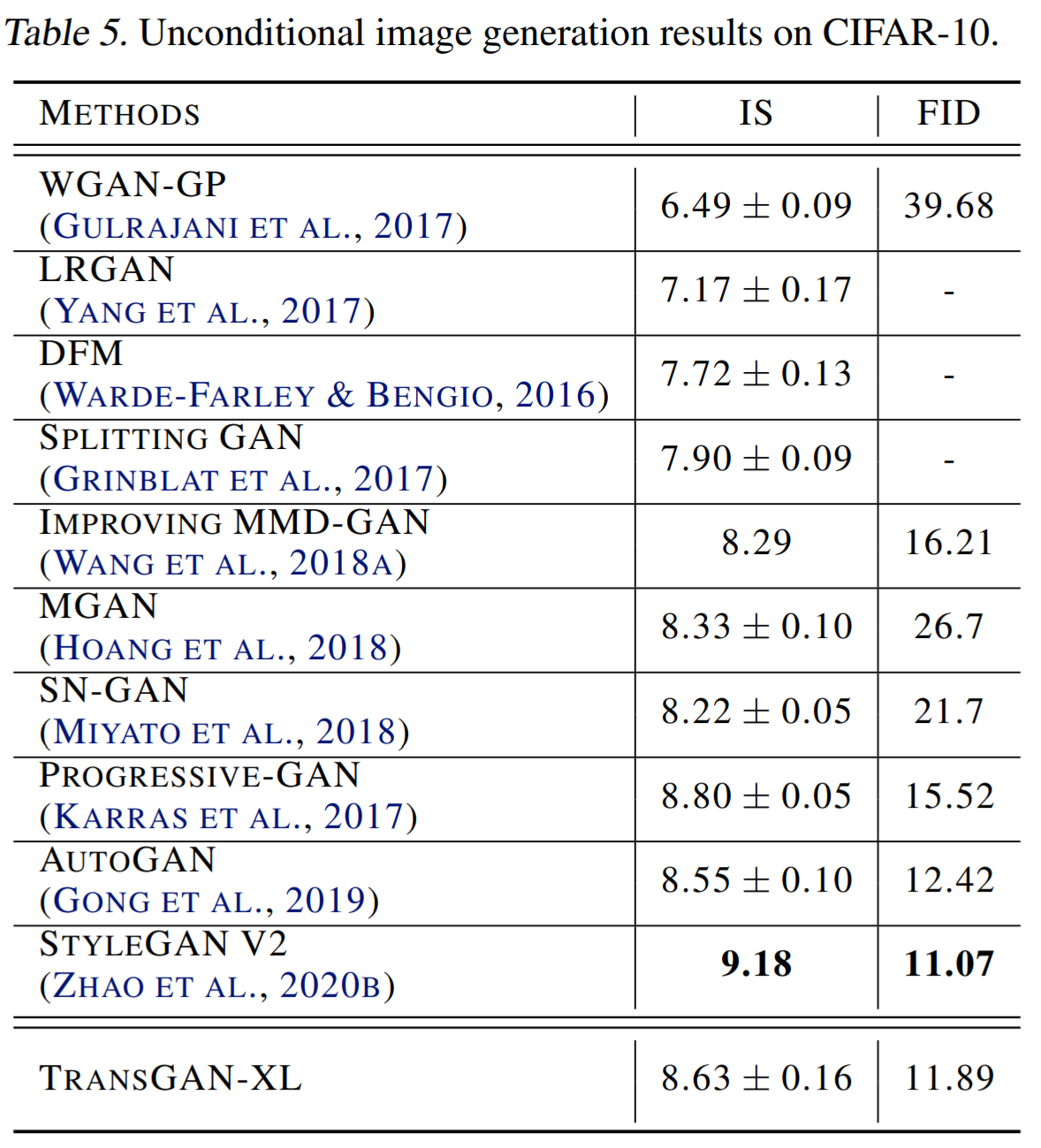
-
[paper] [code] Stanford & Facebook
[paper] [code] Code will be released in July MIT
arXiv 2020/03 [paper]
arXiv 2020/03 [paper]
arXiv 2019 [paper]
arXiv 2019 [paper]
TPAMI 2018 [paper]