llm + bot
🚀AGI时代通用机器人🚀
环境:python>=3.8
- 方式一
pip install langup==0.0.10
- 方式二(建议使用python 虚拟环境)
git clone https://github.com/jiran214/langup-ai.git cd langup-ai/ python -m pip install –upgrade pip python -m pip install -r requirements.txt
- 安装完成后,新建.py文件参考以下代码(注意:采用方式二安装时,可以在src/下新建)
- 所有代码示例 src/examples可见
Bilibili 直播数字人
from langup import config, VtuBer
# config.proxy = 'http://127.0.0.1:7890'
up = VtuBer(
system="""角色:你现在是一位在哔哩哔哩网站的主播,你很熟悉哔哩哔哩上的网友发言习惯和平台调性,擅长与年轻人打交道。
背景:通过直播中和用户弹幕的互动,产出有趣的对话,以此吸引更多人来观看直播并关注你。
任务:你在直播过程中会对每一位直播间用户发的弹幕进行回答,但是要以“杠精”的思维去回答,你会怒怼这些弹幕,不放过每一条弹幕,每次回答字数不能超过100字。""", # 人设
room_id=00000, # Bilibili房间号
openai_api_key="""xxx""", # 同上
is_filter=True, # 是否开启过滤
extra_ban_words=[], # 额外的违禁词
concurrent_num=2 # 控制回复弹幕速度
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 从浏览器资源读取
# browser='edge'
)
up.loop()"""
bilibili直播数字人参数:
:param room_id: bilibili直播房间号
:param credential: bilibili 账号认证
:param is_filter: 是否开启过滤
:param user_input: 是否开启终端输入
:param extra_ban_words: 额外的违禁词
...见更多配置
"""
视频@回复机器人
from langup import config, VideoCommentUP
# config.proxy = 'http://127.0.0.1:7890'
up = VideoCommentUP(
up_sleep=10, # 生成回复间隔事件
listener_sleep=60 * 2, # 2分钟获取一次@消息
system="你是一个会评论视频B站用户,请根据视频内容做出总结、评论",
signals=['总结一下'],
openai_api_key='xxx',
model_name='gpt-3.5-turbo',
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 自动从浏览器资源读取
# browser='edge'
)
up.loop()"""
视频下at信息回复机器人
:param credential: bilibili认证
:param model_name: openai MODEL
:param signals: at暗号列表 (注意:B站会过滤一些词)
:param limit_video_seconds: 过滤视频长度
:param limit_token: 请求GPT token限制(默认为model name)
:param limit_length: 请求GPT 字符串长度限制
:param compress_mode: 请求GPT 压缩过长的视频文字的方式
- random:随机跳跃筛选
- left:从左到右
:param up_sleep: 每次回复的间隔运行时间(秒)
:param listener_sleep: listener 每次读取@消息的间隔运行时间(秒)
...见更多配置
"""
B站私信Bot
from langup import ChatUP, Event
# bilibili cookie 通过浏览器edge提取,apikey从.env读取
ChatUP(
system='你是一位聊天AI助手',
# event_name_list 订阅消息列表
event_name_list=[Event.TEXT],
# credential 参数说明
# 方式一: credential为空,从工作目录/.env文件读取credential
# 方式二: 直接传入 https://nemo2011.github.io/bilibili-api/#/get-credential
# credential={"sessdata": 'xxx', "buvid3": 'xxx', "bili_jct": 'xxx'}
# 方式三: 自动从浏览器资源读取
# browser='load'
).loop()实时语音交互助手
from langup import UserInputReplyUP, config
config.proxy = 'http://127.0.0.1:7890'
# config.openai_api_key = 'xxx' or 创建.env文件 OPENAI_API_KEY=xxx
# 语音实时识别回复
# 修改语音识别模块配置 config.convert['speech_rec']
UserInputReplyUP(system='你是一位AI助手', listen='speech').loop() 终端交互助手
from langup import UserInputReplyUP, config
# config.proxy = 'http://127.0.0.1:7890'
# config.openai_api_key = 'xxx' or 创建.env文件 OPENAI_API_KEY=xxx
# 终端回复
UserInputReplyUP(system='你是一位AI助手', listen='console').loop()更多配置(可忽略)
"""
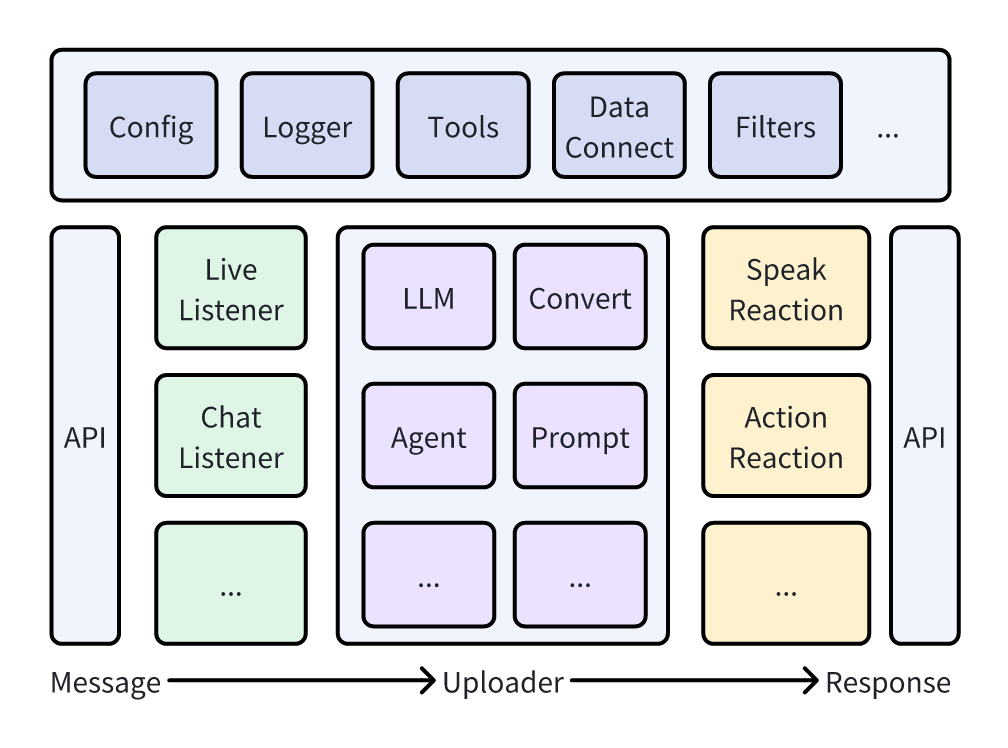
Uploader 所有公共参数:
:param listeners: 感知
:param concurrent_num: 并发数
:param up_sleep: uploader 间隔运行时间
:param listener_sleep: listener 间隔运行时间
:param system: 人设
:param openai_api_key: openai秘钥
:param openai_proxy: http代理
:param openai_api_base: openai endpoint
:param temperature: gpt温度
:param max_tokens: gpt输出长度
:param chat_model_kwargs: langchain chatModel额外配置参数
:param llm_chain_kwargs: langchain chatChain额外配置参数
:param brain: 含有run方法的类
:param mq: 通信队列
"""
全局配置文件:
"""
langup/config.py
修改方式:
form langup import config
config.xxx = xxx
"""
import os
from typing import Union
credential: Union['Credential', None] = None
work_dir = './'
tts = {
"voice": "zh-CN-XiaoyiNeural",
"rate": "+0%",
"volume": "+0%",
"voice_path": 'voice/'
}
log = {
"handlers": ["console"], # console打印, file文件存储
"file_path": "logs/"
}
convert = {
"audio_path": "audio/"
}
root = os.path.dirname(__file__)
openai_api_key = None # sk-...
openai_api_base = None # https://{your_domain}/v1
proxy = None # 代理
debug = True- api_key可自动从环境变量获取
- 国内环境需要设置代理或者openai_api_base 推荐config.proxy='xxx'全局设置,避免设置局部代理导致其它服务不可用
- Bilibili UP都需要 认证信息,获取使用方式如下
- 登录Bilibili 从浏览器获取cookie:https://nemo2011.github.io/bilibili-api/#/get-credential
- 作为字典参数"credential"传入,或者api_key和Bilibili cookie等信息可以写到.env文件中,程序会隐式读取,参考src/.env.temple
- 10.26更新,不需要手动获取,只要你浏览器最近登录过,程序会自动读取浏览器数据 (可以优先尝试,注意windows用户需要完全关闭浏览器进程,否则会出现资源占用情况)
部分模块待实现
- Uploader
- Vtuber
- 基本功能
- 违禁词
- 并发
- VideoCommentUP
- 基本功能
- UserInputUP
- 基本功能
- 语音识别
- Vtuber
- Listener
- 语音识别
- 微信
- Bilibili 私信
- Reaction
- 其它
- 日志记录
- pydantic重构部分类
- 认证信息自动获取
- 感谢项目依赖的开源
- langchain https://github.com/langchain-ai/langchain
- Bilibili API https://github.com/nemo2011/bilibili-api
- 必剪API https://github.com/SocialSisterYi/bcut-asr
- 禁止滥用本库,使用本库请遵守各平台安全规范,可通过提示词、过滤输入等方式
- 示例代码仅供参考,尤其是提示词编写没有必要一样
- 代码可能异常,对于改进和报错问题可以在写在issues