本项目基于官方给定的baseline(DuReader-Checklist-BASELINE)进行二次改造,对整个代码框架做了简单的重构,对核心网络结构添加了注释,解耦了数据读取的模块,并添加了阈值确认的功能,一些小的细节也做了改进。
本次任务为2021语言与智能技术竞赛:机器阅读理解任务,机器阅读理解 (Machine Reading Comprehension) 是指让机器阅读文本,然后回答和阅读内容相关的问题。
具体的,给定一个问题q,一段篇章p及其标题t,参赛系统需要根据篇章内容,判断该篇章p中是否包含给定问题的答案,如果是,则给出该问题的答案a;否则输出“无答案”。数据集中的每个样本,是一个四元组(q、p、t和a),例如:
问题 ( q ): 番石榴汁热量
篇章 ( p ): 番石榴性温,味甜、酸、涩…,最重要的是番石榴所含的脂肪热量较低,一个番石榴所含的脂肪约0.9克重或84卡路里。比起苹果,番石榴所含有的脂肪少38%,卡路里少42%。
标题 ( t ): 番石榴汁的热量 - 妈妈网百科
参考答案 ( a ): [‘一个番石榴所含的脂肪约0.9克重或84卡路里’]
问题 ( q ): 云南文山市多少人口?
篇章 ( p ): 云南省下辖8个市、8个少数民族自治州,面积39万平方千米,总人口4596万人,云南汉族人口为3062.9万人,占云南省总人口的66.63%…
标题 ( t ): 云南总人口数多少人,2019年云南人口数量统计(最新)
参考答案 ( a ): [‘无答案’]
本次竞赛数据集共包含约8.6K问题,其中包括3K训练集,1.1K开发集和4.5K测试集。其中开发集包含1K领域内样本以及少量checklist样本。
在json中的存储逻辑如下,一个数据集文件,比如说train.json或者dev.json是一个大的json串,其中包含一个key,data,对应的value是一个list;list中的每个value均为一个dict(往往仅有一个value),dict中包含两个key,分别为paragraphs和title(这里的title往往为空字符串);在paragraphs中,是一个list,这里存放真正的数据样本,相当于路这个list的长度对应于数据量的多少;在list中的每个value均为一个dict,会包含如下三部分的key,
-
context
对应的内容,往往是一个较长的字符串
-
title
标题,即context的标题,往往是一个较短的字符串
-
qas
对应的问&答内容,这部分是一个list,其中每个值代表一个问题的实体结构,用dict存储。
-
id
问题的唯一id
-
question
问题,字符串
-
type
识别是否是in-domain或者为checklist的数据类型(名词、短语、推理等等),是一个可以枚举的字符串
-
answers
答案,是一个list,其中每个值均代表一个答案的实体,用dict存储,包含两个key,
-
text
回答内容,字符串
-
answer_start
答案的起始位置(从零开始),如果为-1,则表示没有答案,即此时text的value必然为空字符串。
-
-
is_impossible
True或者False,如果为True,表示存在答案(answers中至少有一个不为空的答案),如果为False,则answers中无答案。
该字段的解释目前是自己理解得到的,官网未给出明确的解释。
-
目前为止,已经梳理清楚整体的数据存储结构,为了加深理解这里将上面的字段含义做了一个类比,如下,
其中起始的key,data将他理解为一本书,显然一本书中会包含多篇课文,每篇课文均为独立的实体,所以其value应该是一个list;
接下来是为课文实体,往往一篇课文是有两部分组成,即一个标题title和多个段落paragraphs;
显然一篇课文中会包含多个段落,每个段落均为独立的实体,所以其value应该是一个list;
接下来是段落实体(对应于一个数据样本),在一个段落中,至少会包含它的内容context,它的标题title以及对应的问答qas。
显然在一个段落中会包含多个问答,每个问答均为独立的实体,所以其value应该是一个list;
接下来是问答实体,每个问答实体中,均为包含问题question,它的类型type,它的唯一表示id和它的答案(可能会有多个)。
以一个具体的数据json存储格式(两个样本)展示如下:
{
"data": [
{
"paragraphs": [
{
"context": "高铁和动车上是可以充电的,充电插头就在座位下边或者是前边。高铁动车上的充电插座排布与车型新旧有关。有些车座位是每排座位两个电源插座,有些新型车比如说“复兴号”是每两个座位有一个电源。祝旅途愉快!",
"qas": [
{
"question": "高铁站可以充电吗",
"type": "vocab_noun",
"id": "ebbe3fc466f0f04177b8a64d2ee0de69",
"answers": [
{
"text": "",
"answer_start": -1
}
],
"is_impossible": true
}
],
"title": "高铁和动车上能充电吗? - 知乎"
},
{
"context": "【皋】字读音既可读gāo,又可读háo。读作gāo时,字义有三种意思,水边的高地或岸;沼泽,湖泊;姓氏。读作háo时,有号呼;呼告的意思。皋读作háo时... 全文",
"qas": [
{
"question": "皋怎么读",
"type": "in-domain",
"id": "e3ffa587bba2478191e357cd9a56d10b",
"answers": [
{
"text": "既可读gāo,又可读háo",
"answer_start": 6
}
],
"is_impossible": false
}
],
"title": "皋怎么读 - 懂得"
},
}
]
}训练数据量共3000,类型均为in-domain,
context长度的分布占比,
count 1404.000000
mean 211.985755
std 158.369534
min 50.000000
25% 112.000000
50% 152.000000
75% 251.250000
max 988.000000
有答案的占比为46.8%,有答案的的答案长度分布,
count 1404.000000
mean 44.738604
std 66.828911
min 1.000000
25% 5.000000
50% 15.000000
75% 62.250000
max 522.000000
本部分主要介绍如何将上面的九个不同的数据格式转化为模型可接受的数据格式。
-
样本的归一化
原始的数据整体为一个大的json结构体,不利于传统意义的上的训练样本的区分,该部分主要将整个json结构进行解析为单个的训练样本。定义一个训练样本为如下的结构,
-
id一个训练样本的id
-
title字符串类型,多部分为空
-
context字符串类型,context文本
-
question字符串类型,代表一个问题文本
-
answers数组类型,每个元素为一个json结构体,包括
text和answer_start,基本均为一个答案 -
is_impossible布尔类型,代表是否有答案存在
-
-
转换为ID
将上面的输入样本转化为ID,整体的结构为[CLS]+question+[SEP]+context+[SEP]。
这里需要注意的是context的文本有可能过长,答案可能再context的后面,所以如果context过长,需要做切割,如下图所示,
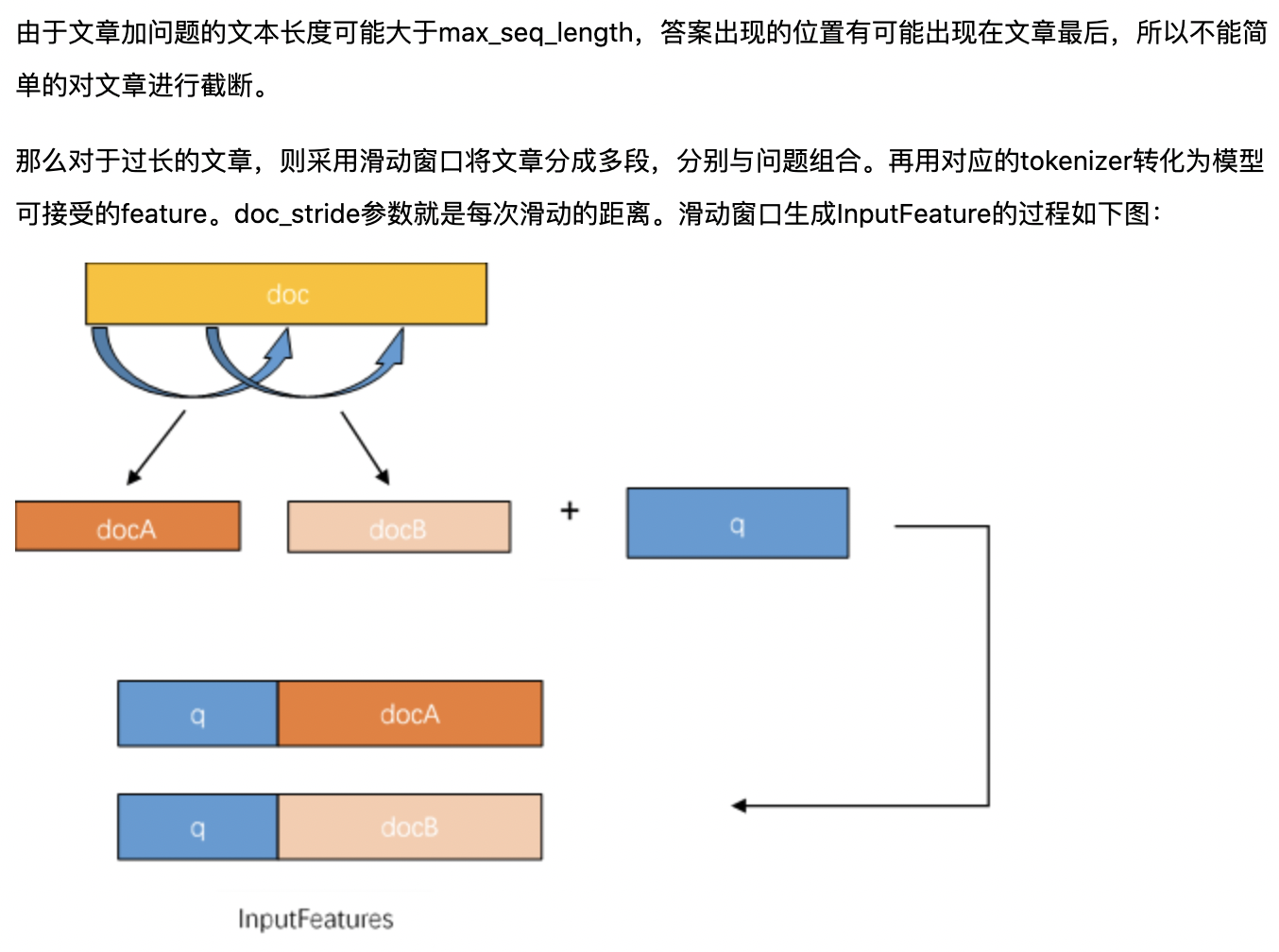

本代码运行基于python3.7,核心的package版本如下,
paddlepaddle 2.0.0
paddlenlp 2.0.0rc16
numpy 1.19.2
scipy 1.6.2
Note:建议通过
conda命令创建一个py37的虚拟环境,然后通过conda或者pip安装包
代码结构上,相较于官方的baseline有较大的变化,整体如下所示,
.
├── [ 12K] README.md
├── [ 224] bin
│ ├── [1.4K] check_eval.sh
│ ├── [ 535] download.sh
│ ├── [1.2K] run_eval.sh
│ ├── [1.8K] run_predict.sh
│ └── [2.0K] run_train.sh
├── [1.9K] confirm_cls_threshold.py
├── [ 320] dataset
│ ├── [44M] test.json
│ ├── [1.5M] dev.json
│ └── [4.0M] train.json
├── [ 192] ernie10
│ ├── [ 368] model_config.json
│ ├── [381M] model_state.pdparams
│ ├── [ 91] tokenizer_config.json
│ └── [ 89K] vocab.txt
├── [8.1K] evaluate.py
├── [ 192] finetuned_model
│ ├── [ 368] model_config.json
│ ├── [571M] model_state.pdparams
│ ├── [ 99] tokenizer_config.json
│ └── [ 89K] vocab.txt
├── [ 192] models
│ ├── [ 0] __init__.py
│ ├── [1.5K] loss_layer.py
│ └── [4.5K] model_layer.py
├── [ 192] roberta_wwm_ext
│ ├── [ 400] model_config.json
│ ├── [390M] roberta_chn_base.pdparams
│ ├── [ 101] tokenizer_config.json
│ └── [107K] vocab.txt
├── [ 192] roberta_wwm_ext_large
│ ├── [ 401] model_config.json
│ ├── [1.2G] model_state.pdparams
│ ├── [ 107] tokenizer_config.json
│ └── [107K] vocab.txt
├── [ 11K] run_mrc.py
└── [ 224] utils
├── [ 0] __init__.py
├── [9.3K] data_helper.py
├── [9.6K] infer.py
└── [3.8K] input_args.py
其中文件夹roberta_wwm_ext_large、roberta_wwm_ext、ernie10是百度官方的预训练模型,文件夹finetuned_model是官方基于ernie10微调的模型,可以直接用来预测,当前也可以基于它继续训练。
由于文件较大,预训练的模型没有上传,可以自行至官网下载即可
# 假设当前目录在project dir下面
# 使用ernie10
bash ./bin/run_train.sh ernie ./ernie10
# 使用roberta
# bash ./bin/run_train.sh roberta ./roberta_wwm_ext
# 使用roberta large
# bash ./bin/run_train.sh roberta ./roberta_wwm_ext_large目前训练脚本中,包含两部分,分别是训练和验证。在验证部分,进行三个处理逻辑,分别如下,
-
模型预测
模型对验证集进行预测,并保存预测结果
-
模型验证
根据预测结果和真实结果,算模型的各部分的得分
-
阈值(有无答案)确认
会遍历所有的阈值(0-1, 均匀100份),打印f1值最高所对应的阈值。
如果想修改训练相关的参数或者数据的路径,可以自行在脚本
run_trian.sh修改即可。
在模型训练完成后,如果想单独对某个验证集进行验证,可以参考本部分,本部分有两中验证方式,
-
假设预测文件已经生成
此时预测文件已经生成,仅需要验证预测文件和真实文件的效果,可以参考脚本
run_eval.sh的方式,# 假设当前目录在project dir下面 sh ./bin/run_eval.sh <raw file path> <pred file path>
-
假设预测文件未生成
此时未生成预测文件,需要模型预测并验证。
# 假设当前目录在project dir下面 bash ./bin/check_eval.sh ernie <trained model path>
-
假设模型预测文件已生成
此步骤将训练文件的内容和预测的内容进行展平,方便进行badcase的探查。参考脚本
show_context_answer.py,已经将该部分集成到bin/run_eval.sh文件中,最终生成的文件中,会有一个dev_answers.txt文件,格式如下,qid context real_answer pred_answer
Note:详细的参数可以参考两个shell脚本的内部代码即可,两个脚本都非常简单。
这部分是最简单一部分,即根据训练的模型来预测数据,用法参考下面,
# 假设当前目录在project dir下面
bash ./bin/run_predict.sh ernie <trained model path>Note:同样,详细的参数可以参考shell脚本的内部代码即可
该部分可忽略,是提交的一些记录,没有整理。
官方的fine-tuned model
验证集的效果:
{"F1": "64.080", "EM": "55.221", "TOTAL": 1130, "SKIP": 0}
{"F1": "65.809", "EM": "57.000", "TOTAL": 1000, "SKIP": 0, "TAG": "in-domain"}
{"F1": "44.113", "EM": "42.857", "TOTAL": 35, "SKIP": 0, "TAG": "vocab"}
{"F1": "63.345", "EM": "62.857", "TOTAL": 35, "SKIP": 0, "TAG": "phrase"}
{"F1": "41.827", "EM": "25.000", "TOTAL": 20, "SKIP": 0, "TAG": "semantic-role"}
{"F1": "46.741", "EM": "25.000", "TOTAL": 20, "SKIP": 0, "TAG": "fault-tolerant"}
{"F1": "53.429", "EM": "35.000", "TOTAL": 20, "SKIP": 0, "TAG": "reasoning"}
基于Roberta model + fine tune,
epoch=2,batch_size=8,
验证集效果:
{"F1": "58.048", "EM": "50.354", "TOTAL": 1130, "SKIP": 0}
{"F1": "59.883", "EM": "52.100", "TOTAL": 1000, "SKIP": 0, "TAG": "in-domain"}
{"F1": "29.836", "EM": "28.571", "TOTAL": 35, "SKIP": 0, "TAG": "vocab"}
{"F1": "60.172", "EM": "57.143", "TOTAL": 35, "SKIP": 0, "TAG": "phrase"}
{"F1": "34.668", "EM": "30.000", "TOTAL": 20, "SKIP": 0, "TAG": "semantic-role"}
{"F1": "59.063", "EM": "30.000", "TOTAL": 20, "SKIP": 0, "TAG": "fault-tolerant"}
{"F1": "34.352", "EM": "30.000", "TOTAL": 20, "SKIP": 0, "TAG": "reasoning"}
基于fine-tuned模型继续微调:
train_epochs=3 batch_size=8 max_seq_length=512 max_answer_length=512 doc_stride=512 learning_rate=3e-5 weight_decay=0.01 adam_epsilon=1e-8 warmup_proportion=0.1
验证集效果:
{"F1": "61.587", "EM": "51.416", "TOTAL": 1130, "SKIP": 0}
效果变差
增加robust训练数据(14520),共17520条,训练中训练效果
训练集、验证集的有无答案的分布:
训练集:3000个,1596个(53.2%)有答案
验证集:1131个,591个(52.3%)有答案,539个无答案
初始参数配置:
model_type=ernie
model_name="finetuned_model"
train_epochs=2
batch_size=8
max_seq_length=512
max_answer_length=512
doc_stride=128
# optimizer(adamX)
learning_rate=3e-5
weight_decay=0.01
adam_epsilon=1e-8
warmup_proportion=0.1
# steps
logging_steps=500
save_steps=1000000
-
尝试一
原始的fine-tuned模型,未训练,仅仅确认最优的阈值:
the best metrics&threshold is (0.7577577577577578, 64.39603499405726, 56.10619469026549)
线上:55.879 46.823
虽然离线的验证集效果略优于之前的0.7,但是线上略低(过分拟合于验证集)。
-
尝试二(ernie10预训练模型)
使用ernie10(model_name="ernie10"),进行fine-tune,验证集最优阈值以及metric是为
the best metrics&threshold is (0.8181818181818182, 62.471453176619455, 53.36283185840708)
未进行线上测试
-
尝试三(doc_stride)
doc_stride,默认128,调整为256,model_name=ernie10,
(0.8383838383838385, 62.59267429232258, 54.7787610619469)
未进行线上测试
调整为512,验证集效果
the best metrics&threshold is (0.8383838383838385, 62.20291835506908, 53.982300884955755)
调整为64,验证集效果
the best metrics&threshold is (0.7373737373737375, 61.0995518287522, 50.61946902654867)
这个暂时还是默认为128
-
尝试四
batch_size的影响,
batch=4,反而效果变好,
(0.7777777777777778, 64.88384460961369, 56.017699115044245)
0412_0135,提交线上尝试, 效果为55.958 45.573,不如baseline(离线比baseline好)
batch=2,
the best metrics&threshold is (0.8686868686868687, 63.5623036563346, 56.8141592920354)
-
尝试五
learning_rate&batch_size,考虑到学习率添加了scheduler,
lr=5e-5 epoch=4,
线上效果为56.535 44.722
the best metrics&threshold is (0.98989898989899, 62.43218731029048, 55.663716814159294)
-
尝试1
用robeta_wwm_ext_large
train_epochs=2 batch_size=2 max_seq_length=512 max_answer_length=512 doc_stride=128 # optimizer(adamX) learning_rate=3e-5 weight_decay=0.01 adam_epsilon=1e-8 warmup_proportion=0.1 # steps logging_steps=500 save_steps=1000000(0.5454545454545455, 63.67338044026271, 54.07079646017699)
-
尝试1
使用ernie10训练,查看badcase
bash bin/run_train.sh ernie dataset/train.json dataset/dev.json ./ernie10 gpu ../../miniconda3/envs/py37_paddle2_gpu/bin/pythonepoch=1, batch_size=2, max_answer_length=512, max_seq_length=512, doc_stride=128
验证集基本效果如下,
{"F1": "58.168", "EM": "46.991", "TOTAL": 1130, "SKIP": 0} now 20/100, F1 is 58.16754595165881, EM is 46.991150442477874 now 40/100, F1 is 58.16754595165881, EM is 46.991150442477874 now 60/100, F1 is 60.63445720614134, EM is 50.530973451327434 now 80/100, F1 is 58.47230349825175, EM is 54.60176991150443 now 100/100, F1 is 52.30088495575221, EM is 52.30088495575221 the best metrics&threshold is (0.6666666666666667, 61.86823082318437, 52.83185840707964)预测(后台运行):
nohup bash bin/run_predict.sh ernie output/train/0501_2351/model_1669 gpu ./dataset/test1.json 0.6667 ../../miniconda3/envs/py37_paddle2_gpu/bin/python &验证集case具体查看:
bash bin/check_eval.sh ernie output/train/0501_2351/model_1669 gpu dataset/dev.json 0.6667 ../../miniconda3/envs/py37_paddle2_gpu/bin/python线上:(F1:54.919,EM:45.123)
-
尝试2
同上,修改epoch=2,batch_size=8
验证集基本效果如下,
{"F1": "58.394", "EM": "46.460", "TOTAL": 1130, "SKIP": 0} now 20/100, F1 is 58.394101311785384, EM is 46.46017699115044 now 40/100, F1 is 58.394101311785384, EM is 46.46017699115044 now 60/100, F1 is 59.441977256652514, EM is 48.230088495575224 now 80/100, F1 is 62.12230125889039, EM is 52.47787610619469 now 100/100, F1 is 52.30088495575221, EM is 52.30088495575221 the best metrics&threshold is (0.8282828282828284, 62.49692869199145, 53.45132743362832)预测(后台运行):
nohup bash bin/run_predict.sh ernie output/train/0501_2351/model_1669 gpu ./dataset/test1.json 0.6667 ../../miniconda3/envs/py37_paddle2_gpu/bin/python &线上:(F1:55.112,EM:46.123)
-
尝试3
shuff输入的数据集,和尝试2的配置保持一致,
验证集效果
time per 1000: 8.84696912765503 {"F1": "60.219", "EM": "48.673", "TOTAL": 1130, "SKIP": 0} now 20/100, F1 is 60.218557189247356, EM is 48.67256637168141 now 40/100, F1 is 60.218557189247356, EM is 48.67256637168141 now 60/100, F1 is 60.62232600647405, EM is 49.91150442477876 now 80/100, F1 is 62.03163250070885, EM is 53.27433628318584 now 100/100, F1 is 52.30088495575221, EM is 52.30088495575221 the best metrics&threshold is (0.8080808080808082, 62.144698100500115, 53.45132743362832)线上:(F1:55.726,EM:46.373)
bash bin/check_eval.sh ernie output/train/ gpu dataset/dev.json 0.8081 ../../miniconda3/envs/py37_paddle2_gpu/bin/pythonbadcase查看思路总结:
- 是否有answer这部分学习比较差,相当于基本的判断没有清晰;
- 另外在已经回答的文本中,如果预测的文本过长往往差的离谱;
- 在阈值确认的函数中,发现存在取不同的阈值F1值相同的情况,最终的阈值选择其中最大的一个,显然不是很合理,这也对应到模型对于是否存在answer这部分存在很大的不确定性。
待分析点:分析训练数据集的答案长度分布,问题的分布,有无答案的比例(写于2.2 数据分布中)
-
尝试4
基于上面的参数修改max_answer_length为50,
验证集效果
{"F1": "58.432", "EM": "47.965", "TOTAL": 1130, "SKIP": 0} now 20/100, F1 is 58.43230560978199, EM is 47.9646017699115 now 40/100, F1 is 58.43230560978199, EM is 47.9646017699115 now 60/100, F1 is 58.51392246379433, EM is 48.76106194690266 now 80/100, F1 is 60.76025599543442, EM is 52.65486725663717 now 100/100, F1 is 52.30088495575221, EM is 52.30088495575221 the best metrics&threshold is (0.8484848484848485, 61.11615942817769, 53.716814159292035)线上:(F1:53.89,EM:44.722)
效果差异较大
-
尝试5
loss比重调整,batch_size: 4,0.4 * mrc_loss + 0.6 * cls_loss
验证集效果
{"F1": "61.843", "EM": "50.796", "ans_score": "76.549", "TOTAL": 1130, "SKIP": 0} now 20/100, F1 is 61.84339107174933, EM is 50.796460176991154 now 40/100, F1 is 61.84339107174933, EM is 50.796460176991154 now 60/100, F1 is 63.31044746381003, EM is 52.389380530973455 now 80/100, F1 is 63.1046394499256, EM is 53.80530973451327 now 100/100, F1 is 52.30088495575221, EM is 52.30088495575221 the best metrics&threshold is (0.8181818181818182, 64.04877537228401, 54.7787610619469)
线上:(F1:56.203,EM:46.973)
- 尝试6
数据集增加
loss优化(可学习的参数)
早停机制
对抗训练
超参数
不同的预训练模型
更大的网络容量
badcase 优化
根据每一个维度特点,增强数据