




pdfcpu is a PDF processing library written in Go supporting encryption. It provides both an API and a CLI. Supported are all versions up to PDF 1.7 (ISO-32000).
This is an effort to build a comprehensive PDF processing library from the ground up written in Go. Over time pdfcpu aims to support the standard range of PDF processing features and also any interesting use cases that may present themselves along the way.











The main focus lies on strong support for batch processing and scripting via a rich command line. At the same time pdfcpu wants to make it easy to integrate PDF processing into your Go based backend system by providing a robust command set.
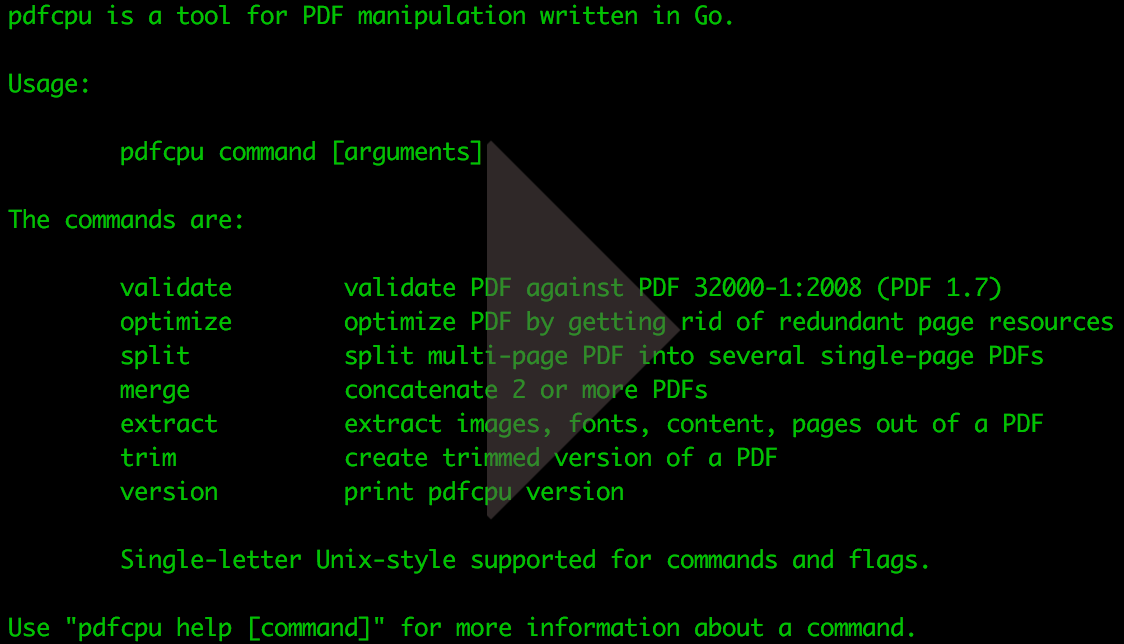
- attachments
- change owner password
- change user password
- collect
- decrypt
- encrypt
- extract
- fonts
- grid
- import
- info
- keywords
- merge
- nup
- optimize
- pages
- permissions
- portfolio
- properties
- rotate
- split
- stamp
- trim
- validate
- watermark
- The main entry point is pdfcpu.io.
- For CLI examples also go to pdfcpu.io. There you will find explanations of all the commands and their parameters.
- For API examples of all pdfcpu operations please refer to GoDoc.
- Always make sure your work is based on the latest commit!
- pdfcpu is still Alpha - bugfixes are committed on the fly and will be mentioned in the next release notes.
- Follow pdfcpu for news and release announcements.
- For quick questions or discussions get in touch on the Gopher Slack in the #pdfcpu channel.
(using older version with a smaller command set)
Get the latest binary here.
Required go version for building: go1.15 and up
go get github.com/pdfcpu/pdfcpu/cmd/...
cd $GOPATH/src/github.com/pdfcpu/pdfcpu/cmd/pdfcpu
go install
pdfcpu version
git clone https://github.com/pdfcpu/pdfcpu
cd pdfcpu/cmd/pdfcpu
go install
pdfcpu version
brew install pdfcpu
pdfcpu version
docker build -t pdfcpu .
# mount current folder into container to process local files
docker run -it --mount type=bind,source="$(pwd)",target=/app pdfcpu ./pdfcpu validate -mode strict /app/pdfs/a.pdf
- Please open an issue if you find a bug or want to propose a change.
- Feature requests - always welcome!
- Bug fixes - always welcome!
- PRs - anytime!
- pdfcpu is stable but still Alpha and occasionally undergoing heavy changes.
- If you want to report a bug please attach the very verbose (
pdfcpu cmd -vv ...) output and ideally a test PDF that you can share. - Always make sure your contribution is based on the latest commit.
- Please sign your commits.
Unfortunately crashes do happen :( For the majority of the cases this is due to a diverse pool of PDF Writers out there and millions of PDF files using different versions waiting to be processed by pdfcpu. Sometimes these PDFs were written more than 20(!) years ago. Often there is an issue with validation - sometimes a bug in the parser. Many times even using relaxed validation with pdfcpu does not work. In these cases we need to extend relaxed validation and for this we are relying on your help. By reporting crashes you are helping to improve the stability of pdfcpu. If you happen to crash on any pdfcpu operation be it on the command line or in your Go backend these are the steps to report this:
Regardless of the pdfcpu operation, please start using the pdfcpu command line to validate your file:
pdfcpu validate -v &> crash.logor to produce very verbose output
pdfcpu validate -vv &> crash.logwill produce what's needed to investigate a crash. Then open an issue and post crash.log or its contents. Ideally post a test PDF you can share to reproduce this. You can also email to hhrutter@gmail.com or if you prefer Slack you can get in touch on the Gopher slack #pdfcpu channel.
If processing your PDF with pdfcpu crashes during validation and can be opened by Adobe Reader and Mac Preview chances are we can extend relaxed validation and provide a fix. If the file in question cannot be opened by both Adobe Reader and Mac Preview we cannot help you!
Thanks goes to these wonderful people:

















Please note that this project is released with a Contributor Code of Conduct. By participating in this project you agree to abide by its terms.
Usage of pdfcpu assumes you know about and respect all copyrights of any PDF content you may be processing. This applies to the PDF files as such, their content and in particular all embedded resources like font files or images. Credit goes to Renee French for creating our beloved Gopher.
Apache-2.0
![]()