![]()
Image by @darthdeus, using Stable Diffusion


llm is a Rust ecosystem of libraries for running inference on large language models, inspired by llama.cpp.
The primary crate is the llm crate, which wraps llm-base and supported model crates. This is used by llm-cli to provide inference for all supported models.
It is powered by the ggml tensor library, and aims to bring
the robustness and ease of use of Rust to the world of large language models.
Make sure you have a Rust 1.65.0 or above and C toolchain1 set up.
llm is a Rust library that re-exports llm-base and the model crates (e.g. bloom, gpt2 llama).
llm-cli (binary name llm) is a basic application that provides a CLI interface to the library.
NOTE: For best results, make sure to build and run in release mode. Debug builds are going to be very slow.
Run
cargo install --git https://github.com/rustformers/llm llm-clito install llm to your Cargo bin directory, which rustup is likely to
have added to your PATH.
The CLI application can then be run through llm.

Clone the repository and then build it with
git clone --recurse-submodules git@github.com:rustformers/llm.git
cargo build --releaseThe resulting binary will be at target/release/llm[.exe].
It can also be run directly through Cargo, using
cargo run --release --bin llm -- <ARGS>This is useful for development.
In order to run inference, a model's weights are required. Currently, the following models are supported:
Compatible weights can be found on Hugging Face by searching for GGML models.
Currently, the only legal source to get the original weights is this repository.
After acquiring the weights, it is necessary to convert them into a format that is compatible with ggml. To achieve this, follow the steps outlined below:
Warning
To run the Python scripts, a Python version of 3.9 or 3.10 is required. 3.11 is unsupported at the time of writing.
# Convert the model to f16 ggml format
python3 scripts/convert-pth-to-ggml.py /path/to/your/models/7B/ 1
# Quantize the model to 4-bit ggml format
cargo run --bin llm llama quantize /path/to/your/models/7B/ggml-model-f16.bin /path/to/your/models/7B/ggml-model-q4_0.bin q4_0Note
The llama.cpp repository has additional information on how to obtain and run specific models.
For example, try the following prompt:
llm llama infer -m <path>/ggml-model-q4_0.bin -p "Tell me how cool the Rust programming language is:"Some additional things to try:
-
Use
--helpto see a list of available options. -
If you have the alpaca-lora weights, try
replmode!llm llama repl -m <path>/ggml-alpaca-7b-q4.bin -f examples/alpaca_prompt.txt
-
Sessions can be loaded (
--load-session) or saved (--save-session) to file. To automatically load and save the same session, use--persist-session. This can be used to cache prompts to reduce load time, too: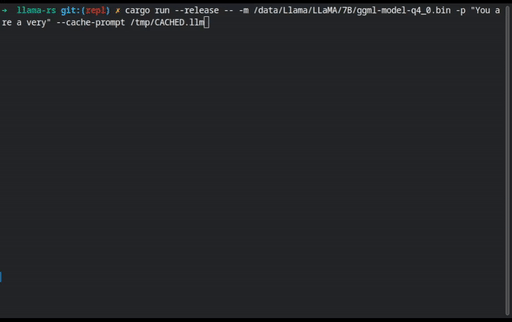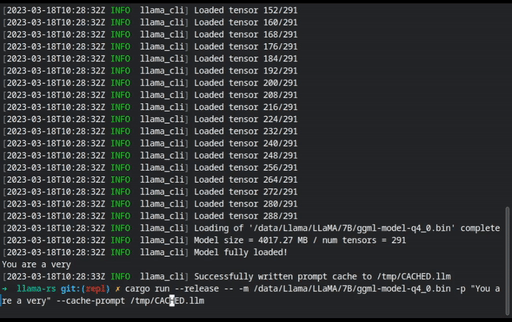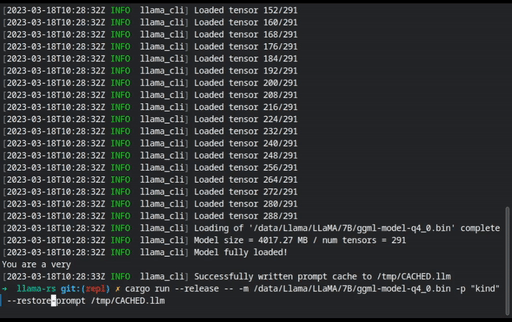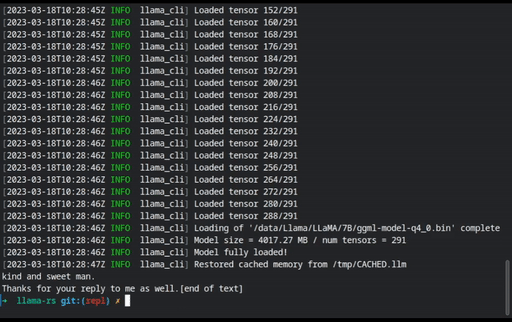
(This GIF shows an older version of the flags, but the mechanics are still the same.)


# To build (This will take some time, go grab some coffee):
docker build -t llm .
# To run with prompt:
docker run --rm --name llm -it -v ${PWD}/data:/data -v ${PWD}/examples:/examples llm llama infer -m data/gpt4all-lora-quantized-ggml.bin -p "Tell me how cool the Rust programming language is:"
# To run with prompt file and repl (will wait for user input):
docker run --rm --name llm -it -v ${PWD}/data:/data -v ${PWD}/examples:/examples llm llama repl -m data/gpt4all-lora-quantized-ggml.bin -f examples/alpaca_prompt.txtIt was not my choice. Ferris appeared to me in my dreams and asked me to rewrite this in the name of the Holy crab.
Come on! I don't want to get into a flame war. You know how it goes, something something memory something something cargo is nice, don't make me say it, everybody knows this already.
Sheesh! Okaaay. After seeing the huge potential for llama.cpp,
the first thing I did was to see how hard would it be to turn it into a
library to embed in my projects. I started digging into the code, and realized
the heavy lifting is done by ggml (a C library, easy to bind to Rust) and
the whole project was just around ~2k lines of C++ code (not so easy to bind).
After a couple of (failed) attempts to build an HTTP server into the tool, I
realized I'd be much more productive if I just ported the code to Rust, where
I'm more comfortable.
Haha. Of course not. I just like collecting imaginary internet points, in the form of little stars, that people seem to give to me whenever I embark on pointless quests for rewriting X thing, but in Rust.
This is a reimplementation of llama.cpp that does not share any code with it
outside of ggml. This was done for a variety of reasons:
llama.cpprequires a C++ compiler, which can cause problems for cross-compilation to more esoteric platforms. An example of such a platform is WebAssembly, which can require a non-standard compiler SDK.- Rust is easier to work with from a development and open-source perspective; it offers better tooling for writing "code in the large" with many other authors. Additionally, we can benefit from the larger Rust ecosystem with ease.
- We would like to make
ggmlan optional backend (see this issue).
In general, we hope to build a solution for model inferencing that is as easy to use and deploy as any other Rust crate.
Footnotes
-
A modern-ish C toolchain is required to compile
ggml. A C++ toolchain should not be necessary. ↩