The Universe of Data.
All about Data, Data Science, and Data Engineering.
Upstage Solar is powered by Dataverse! Try at Upstage Console!
Docs • Examples • API Reference • FAQ • Contribution Guide • Contact • Discord • Paper
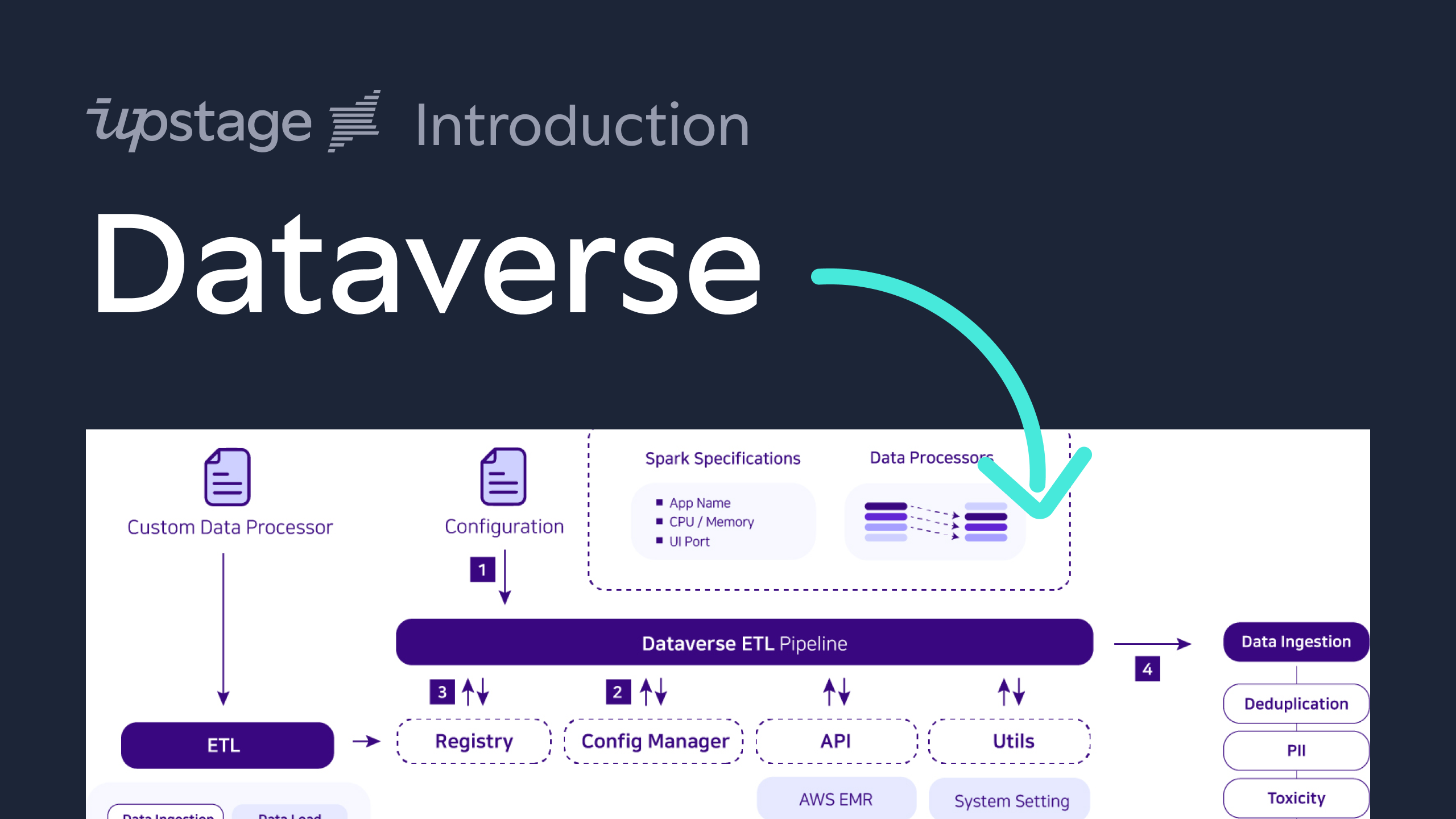
Dataverse is a freely-accessible open-source project that supports your ETL(Extract, Transform and Load) pipeline with Python. We offer a simple, standardized and user-friendly solution for data processing and management, catering to the needs of data scientists, analysts, and developers in LLM era. Even though you don't know much about Spark, you can use it easily via dataverse.
- utilize a range of preprocessing functions without the need to install multiple libraries.
- create high-quality data for analysis and training of Large Language Models (LLM).
- leverage Spark with ease, regardless of your expertise level.
- facilitate smoother collaboration among users with varying degress of Spark proficiency.
- enjoy freedom from the limitations of local environments by harnessing the capabilities of AWS EMR.

- Block-Based: In Dataverse, a
blockmeans aregistered ETL functionwhich is running on Spark. You can build Spark code like putting together puzzle pieces. You can easily add, take away, or re-arrange pieces to get the results you want via configure. - Configure-Based: All the setups for Spark and steps of block can be defined with configure. You don't need to know all the code. Just set up the options, and you're good to go.
- Extensible: It's designed to meet your specific demands, allowing for custom features that fit perfectly with your project.
If you want to know more about Dataverse, please checkout our docs.
By clicking below image, it'll take you to a short intro video!
To use this library, the following conditions are needed:
- Python (version between 3.10 and 3.11)
- JDK (version 11)
- PySpark
Detail installation guide for prerequisites can be found on here.
pip install dataverseVarious and more detailed tutorials are here.
- add_new_etl_process.ipynb : If you want to use your custom function, you have to register the function on Dataverse. This will guide you from register to apply it on pipeline.
- test_etl_process.ipynb : When you want to get test(sample) data to quickly test your ETL process, or need data from a certain point to test your ETL process.
- scaleout_with_EMR.ipynb : For people who want to run their pipeline on EMR cluster.
Detail to the example etl configure.
- data_ingestion___huggingface___hf2raw Load dataset from Hugging Face, which contains a total of 2.59k rows.
- utils___sampling___random To decrease the dataset size, randomly subsample 50% of data to reduce the size of dataset, with a default seed value of 42.
This will reduce the dataset to 1.29k rows.
- deduplication___minhash___lsh_jaccard Deduplicate by
question column, 5-gram minhash jaccard similarity threshold of 0.1.
- data_save___parquet___ufl2parquet Save the processed dataset as a Parquet file to
./guideline/etl/sample/quickstart.parquet.The final dataset comprises around 1.14k rows.
# 1. Set your ETL process as config.
from omegaconf import OmegaConf
ETL_config = OmegaConf.create({
# Set up Spark
'spark': {
'appname': 'ETL',
'driver': {'memory': '4g'},
},
'etl': [
{
# Extract; You can use HuggingFace datset from hub directly!
'name': 'data_ingestion___huggingface___hf2raw',
'args': {'name_or_path': ['ai2_arc', 'ARC-Challenge']}
},
{
# Reduce dataset scale
'name': 'utils___sampling___random',
'args': {'sample_n_or_frac': 0.5}
},
{
# Transform; deduplicate data via minhash
'name': 'deduplication___minhash___lsh_jaccard',
'args': {'threshold': 0.1,
'ngram_size': 5,
'subset': 'question'}
},
{
# Load; Save the data
'name': 'data_save___parquet___ufl2parquet',
'args': {'save_path': './guideline/etl/sample/quickstart.parquet'}
}
]
})Above code block is an example of an ETL process in Dataverse. In Dataverse, the available registered ETL functions are referred to as blocks, and this example is comprised of four blocks. You can freely combine these blocks using config to create the ETL processes for your needs. The list of available functions and args of them can be found in the API Reference. Each functions 'args' should be added in dictionary format.
# 2. Run ETLpipeline.
from dataverse.etl import ETLPipeline
etl_pipeline = ETLPipeline()
spark, dataset = etl_pipeline.run(config=ETL_config, verbose=True)ETLPipeline is an object designed to manage the ETL processes. By inserting ETL_config which is defined in the previous step into ETLpipeline object and calling the run method, stacked ETL blocks will execute in the order they were stacked.
# 3. Result file is saved on the save_pathAs the example gave save_path argument to the last block of ETL_config, data passed through the process will be saved on the given path.
Currently, about 50 functions are registered as the ETL process, which means they are eagerly awaiting your use!
| Type | Package | description |
|---|---|---|
| Extract | data_ingestion | Loading data from any source to the preferred format |
| Transform | bias | (WIP) Reduce skewed or prejudiced data, particularly data that reinforce stereotypes. |
| cleaning | Remove irrelevant, redundant, or noisy information, such as stop words or special characters. | |
| decontamination | (WIP) Remove contaminated data including benchmark. | |
| deduplication | Remove duplicated data, targeting not only identical matches but also similar data. | |
| pii | PII stands for Personally Identifiable Information. Removing sensitive information from data. | |
| quality | Improving the data quality, in the perspective of accuracy, consistency, and reliability of data. | |
| toxicity | (WIP) Removing harmful, offensive, or inappropriate content within the data. | |
| Load | data_save | Saving the processed data to a preferred source like data lake, database, etc. |
| Utils | utils | Essential tools for data processing, including sampling, logging, statistics, etc. |
Dataverse works with AWS S3 and EMR, enabling you to load and save data on S3 and execute ETL pipelines through EMR. Step by step guide to setting up is here.
If you have any use-cases of your own, please feel free to let us know.
We would love to hear about them and possibly feature your case.
✨ Upstage is using Dataverse for preprocessing the data for the training of Solar Mini.
✨ Upstage is using Dataverse for preprocessing the data for the Up 1T Token Club.
Dataverse is an open-source project orchestrated by the Data-Centric LLM Team at Upstage, designed as an data ecosystem for LLM(Large Language Model). Launched in March 2024, this initiative stands at the forefront of advancing data handling in the realm of LLM.
Dataverse is completely freely-accessible open-source and licensed under the Apache-2.0 license.
If you want to cite our 🌌 Dataverse project, feel free to use the following bibtex. You can check our paper via link.
@misc{park2024dataverse,
title={Dataverse: Open-Source ETL (Extract, Transform, Load) Pipeline for Large Language Models},
author={Hyunbyung Park and Sukyung Lee and Gyoungjin Gim and Yungi Kim and Dahyun Kim and Chanjun Park},
year={2024},
eprint={2403.19340},
archivePrefix={arXiv},
primaryClass={cs.CL}
}