![]()
DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
Xinqi Lin1,*, Jingwen He2,*, Ziyan Chen2, Zhaoyang Lyu2, Ben Fei2, Bo Dai2, Wanli Ouyang2, Yu Qiao2, Chao Dong1,2
1Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences
2Shanghai AI Laboratory

⭐If DiffBIR is helpful for you, please help star this repo. Thanks!🤗
📖Table Of Contents
- Visual Results On Real-world Images
- Installation
- Pretrained Models
- Quick Start (gradio demo)
- Inference
- Train
- Update
- TODO
👀Visual Results On Real-world Images
General Image Restoration
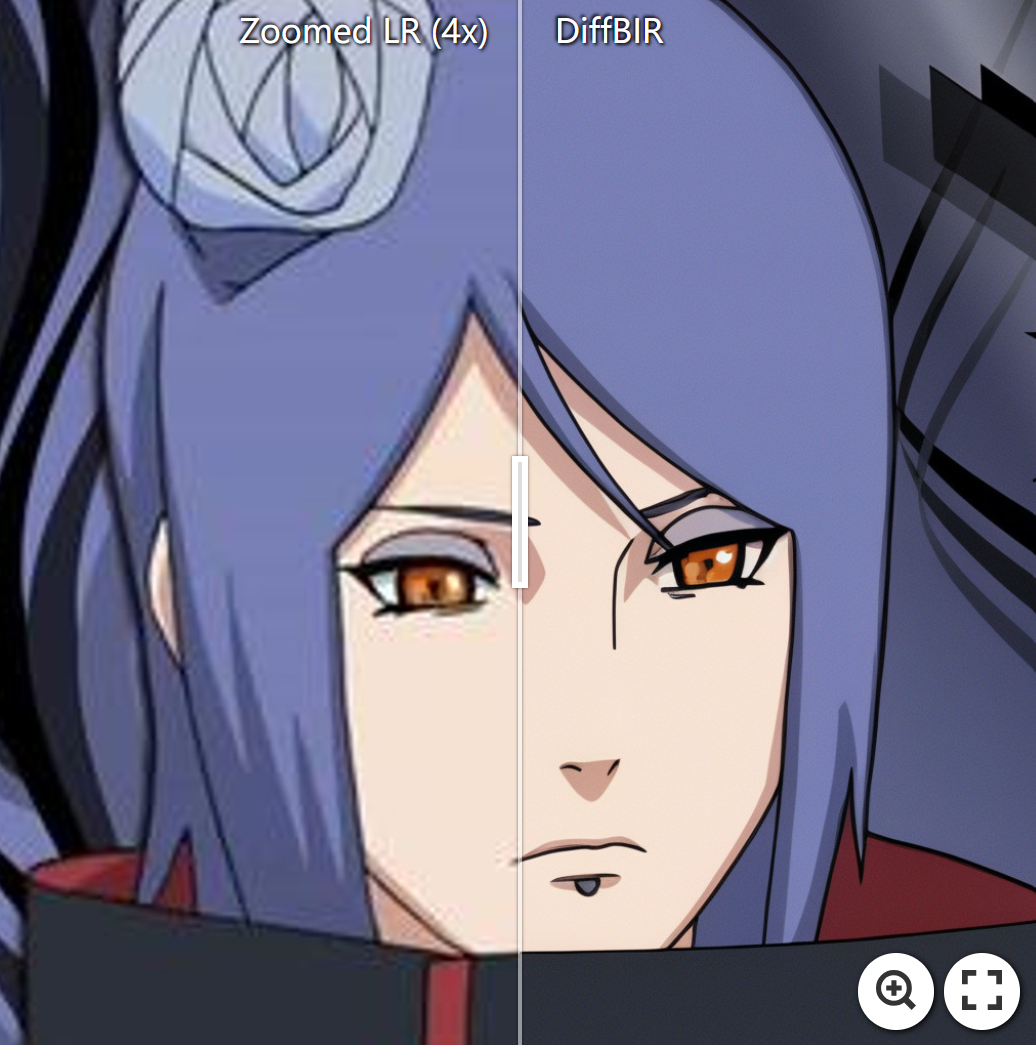






Face Image Restoration







⚙️Installation
- Python >= 3.9
- CUDA >= 11.3
- PyTorch >= 1.12.1
- xformers == 0.0.16
# clone this repo
git clone https://github.com/XPixelGroup/DiffBIR.git
cd DiffBIR
# create a conda environment with python >= 3.9
conda create -n diffbir python=3.9
conda activate diffbir
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch
conda install xformers==0.0.16 -c xformers
# other dependencies
pip install -r requirements.txt🧬Pretrained Models
| Model Name | Description | HuggingFace | BaiduNetdisk |
|---|---|---|---|
| general_swinir_v1.ckpt | Stage1 model (SwinIR) for general image restoration. | download | download (pwd: v3v6) |
| general_full_v1.ckpt | Full model for general image restoration. "Full" means it contains both the stage1 and stage2 model. | download | download (pwd: 86zi) |
| face_swinir_v1.ckpt | Stage1 model (SwinIR) for face restoration. | download | download (pwd: xk5u) |
| face_full_v1.ckpt | Full model for face restoration. | download | download (pwd: ov8i) |
🛫Quick Start
Download general_full_v1.ckpt and general_swinir_v1.ckpt to weights/, then run the following command to interact with the gradio website.
python gradio_diffbir.py \
--ckpt weights/general_full_v1.ckpt \
--config configs/model/cldm.yaml \
--reload_swinir \
--swinir_ckpt weights/general_swinir_v1.ckpt

⚔️Inference
Full Pipeline (Remove Degradations & Refine Details)
General Image
Download general_full_v1.ckpt and general_swinir_v1.ckpt to weights/ and run the following command.
python inference.py \
--input inputs/general \
--config configs/model/cldm.yaml \
--ckpt weights/general_full_v1.ckpt \
--reload_swinir --swinir_ckpt weights/general_swinir_v1.ckpt \
--steps 50 \
--sr_scale 4 \
--image_size 512 \
--color_fix_type wavelet --resize_back \
--output results/generalIf you are confused about where the reload_swinir option came from, please refer to the degradation details.
Face Image
Download face_full_v1.ckpt to weights/ and run the following command.
# for aligned face inputs
python inference_face.py \
--config configs/model/cldm.yaml \
--ckpt weights/face_full_v1.ckpt \
--input inputs/face/aligned \
--steps 50 \
--sr_scale 1 \
--image_size 512 \
--color_fix_type wavelet \
--output results/face/aligned --resize_back \
--has_aligned
# for unaligned face inputs
python inference_face.py \
--config configs/model/cldm.yaml \
--ckpt weights/face_full_v1.ckpt \
--input inputs/face/whole_img \
--steps 50 \
--sr_scale 1 \
--image_size 512 \
--color_fix_type wavelet \
--output results/face/whole_img --resize_backOnly Stage1 Model (Remove Degradations)
Download general_swinir_v1.ckpt, face_swinir_v1.ckpt for general, face image respectively, and run the following command.
python scripts/inference_stage1.py \
--config configs/model/swinir.yaml \
--ckpt [swinir_ckpt_path] \
--input [lq_dir] \
--sr_scale 1 --image_size 512 \
--output [output_dir_path]Only Stage2 Model (Refine Details)
Since the proposed two-stage pipeline is very flexible, you can utilize other awesome models to remove degradations instead of SwinIR and then leverage the Stable Diffusion to refine details.
# step1: Use other models to remove degradations and save results in [img_dir_path].
# step2: Refine details of step1 outputs.
python inference.py \
--config configs/model/cldm.yaml \
--ckpt [full_ckpt_path] \
--steps 50 --sr_scale 1 --image_size 512 \
--input [img_dir_path] \
--color_fix_type wavelet --resize_back \
--output [output_dir_path] \
--disable_preprocess_model🌠Train
Degradation Details
For general image restoration, we first train both the stage1 and stage2 model under codeformer degradation to enhance the generative capacity of the stage2 model. In order to improve the ability for degradation removal, we train another stage1 model under Real-ESRGAN degradation and utilize it during inference.
For face image restoration, we adopt the degradation model used in DifFace for training and directly utilize the SwinIR model released by them as our stage1 model.
Data Preparation
-
Generate file list of training set and validation set.
python scripts/make_file_list.py \ --img_folder [hq_dir_path] \ --val_size [validation_set_size] \ --save_folder [save_dir_path] \ --follow_links
This script will collect all image files in
img_folderand split them into training set and validation set automatically. You will get two file lists insave_folder, each line in a file list contains an absolute path of an image file:save_folder ├── train.list # training file list └── val.list # validation file list -
Configure training set and validation set.
For general image restoration, fill in the following configuration files with appropriate values.
- training set and validation set for CodeFormer degradation.
- training set and validation set for Real-ESRGAN degradation.
For face image restoration, fill in the face training set and validation set configuration files with appropriate values.
Train Stage1 Model
-
Configure training-related information.
Fill in the configuration file of training with appropriate values.
-
Start training.
python train.py --config [training_config_path]
💡:Checkpoints of SwinIR will be used in training stage2 model.
Train Stage2 Model
-
Download pretrained Stable Diffusion v2.1 to provide generative capabilities.
wget https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt --no-check-certificate
-
Create the initial model weights.
python scripts/make_stage2_init_weight.py \ --cldm_config configs/model/cldm.yaml \ --sd_weight [sd_v2.1_ckpt_path] \ --swinir_weight [swinir_ckpt_path] \ --output [init_weight_output_path]
You will see some outputs which show the weight initialization.
-
Configure training-related information.
Fill in the configuration file of training with appropriate values.
-
Start training.
python train.py --config [training_config_path]
🆕Update
- 2023.08.30: Repo is released.
- 2023.09.06: Update colab demo. Thanks to camenduru!🤗
- 2023.09.08: Add support for restoring unaligned faces.
🧗TODO
- Release code and pretrained models💻.
- Update links to paper and project page🔗.
- Release real47 testset💽.
- Reduce the memory usage of DiffBIR😺.
- Provide HuggingFace demo📓.
- Upload inference code of latent image guidance📄.
- Improve the performance🦸.
- Add a patch-based sampling schedule🔍.
Citation
Please cite us if our work is useful for your research.
@article{2023diffbir,
author = {Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Ben Fei, Bo Dai, Wanli Ouyang, Yu Qiao, Chao Dong},
title = {DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior},
journal = {arxiv},
year = {2023},
}
License
This project is released under the Apache 2.0 license.
Acknowledgement
This project is based on ControlNet and BasicSR. Thanks for their awesome work.
Contact
If you have any questions, please feel free to contact with me at linxinqi@tju.edu.cn.