动态IP解决新浪的反爬虫机制,快速抓取微博内容。
抓取1000个公司(在companyList.py文件中)五年内相关的微博,进而统计评论数、转发数、点赞数等等。
- Python2.7
- winxp服务器(通过某宝购买,关键是ADSL拨号功能,不然无法实现动态IP,也就解决不了新浪的反爬虫机制)
-
每个公司五年内的微博(通过sqlite3存储)
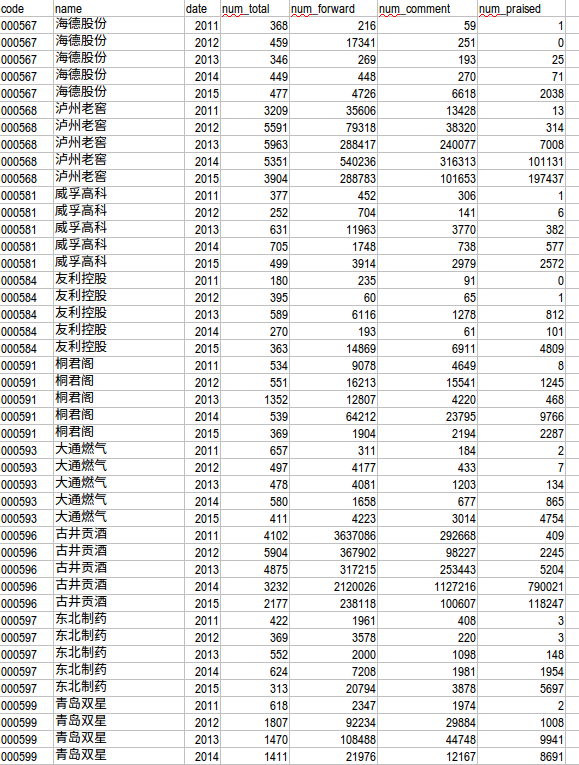
下面截图为company0000.db的微博。

-
所有公司微博评论数、转发数、点赞数的统计(excel形式呈现)


刚刚(Sun Sep 10 07:51:46 CST 2017)在整理浏览器的书签,因为自己习惯性会把觉得有用的网页存储为书签,所以日积月累,书签的数量已经十分庞大,决定清理一下。清理之前把那些与此项目的网页书签贴在这里吧
- 模拟登录新浪微博(Python)
- Python验证码识别处理实例 - Python - 伯乐在线
- Python验证码识别处理实例 - 林炳文Evankaka的专栏 - CSDN博客
- 爬虫怎么解决封IP? - 知乎
- 爬虫ip代理服务器的简要思路 - 京东放养的爬虫 - CSDN博客
- 关于使用动态轮训切换ip防止爬虫被封杀
- python爬虫-爬取代理IP并通过多线程快速验证
- OpenCV-Python教程(5、初级滤波内容)
- 字符型图片验证码识别完整过程及Python实现
- Linux IP代理筛选系统(shell+proxy)
- SQLite 连接两个字符串
- 取得sqlite数据库里所有的表名 &复制表
- python - Beautifulsoup and AJAX-table problem - Stack Overflow
- python - How to enable digits only in pytesser? - Stack Overflow
- Python 文件读写操作实例详解