The goal of the project is to train a program to guess the price of a car given its kilometrage. It's a simple linear regression problem.
Be sure to have a Python > 3.5 installed, with numpy, pandas and matplotlib.
To visualize the dataset:
# If the model has already been trained, the line will be plotted
python3 plot_data.pyTo train the dataset:
python3 train.pyTo predict a price:
python3 predict.py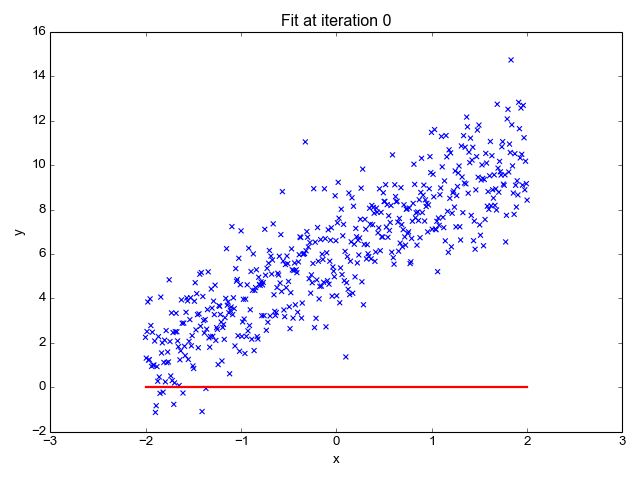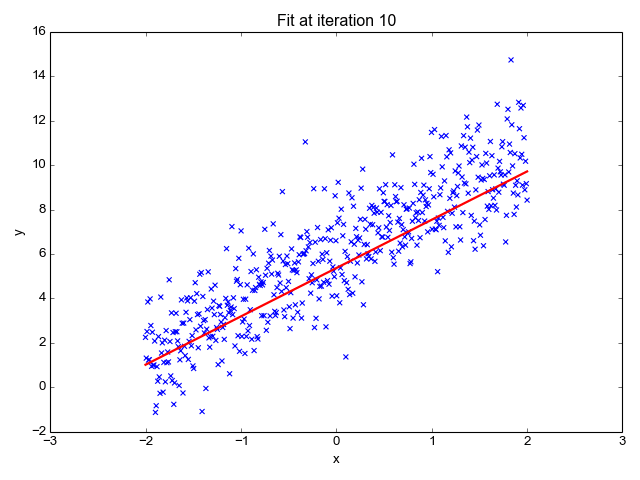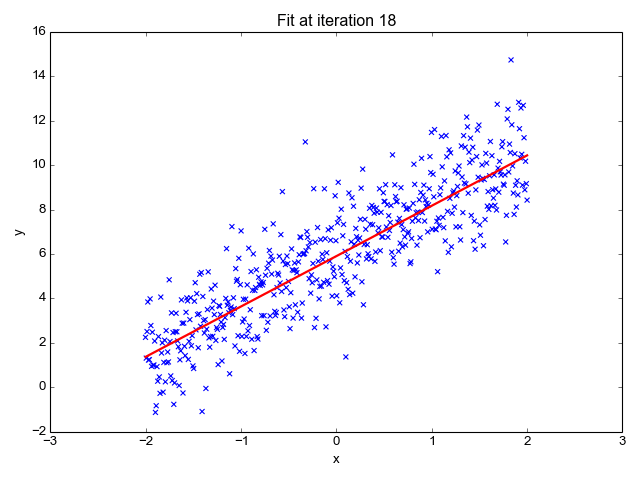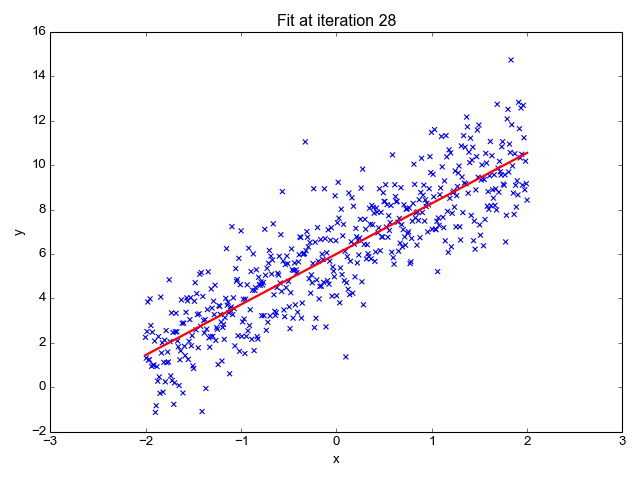
Linear regression is the process of finding a line that best fits a given dataset.
It can be done with the gradient descent algorithm. You can define "finding the line that best fits M examples" by "find the line that reduces the average distance between the examples and itself". Gradient descent is an algorithm that look at every examples, and adjust the line a little bit to fit better.
To speed up the process of learning, you can group your training examples in batch.
Features are the input, here the kilometrage, targets are the output, here the price.
Bias is a trainable parameter that doesn't depend on the inputs. Here it's theta0.
Basically, the algorithm is:
for every epochs:
for every batch:
predictions = our prediction for given features
error = difference between our prediction and targets
for every weight:
delta[weight] = learning_rate * error * features[i]
delta_bias = learning_rate * error
weights = weights - delta
bias = bias - delta_bias
You can use pyplot to visualize data in Python. Here we have a 2D dataset, so we use the scatter function. Here is what we get:
We can see that the axis have a really different scale. In general, machine learning algortihms work best with unskewed data, so what we can do is normalizing our data, to constrain every example between 0 and 1 on both axis. So now we have:
We can expect that our theta0 should be around 8000, and our theta1 should be a small negative value. It will help us know if what we'll get is good or not.
Our line is defined by two parameters, theta0 and theta1:
price = theta0 + theta1 * kilometrage
Now we use the gradient descent algorithm to find the best parameters.
Here what's the training looks like on my side, with 1000 epochs, a learning rate of 0.01 and a batch size of 4:
At the end of the training, I have:
theta0 = 8199.8729
theta1 = -0.0185
If you scaled your dataset, don't forget to scale back your parameters !
We now have our line that minimizes the average distance with examples. We can plot it on our dataset to see if our values seem correct: 
The line seems good, and now we can do predictions by reading on the line, or by using the formula given previously.