Available as website at: tadeohepperle.github.io/2021-09-02-sprache-automatisch-erkennen/
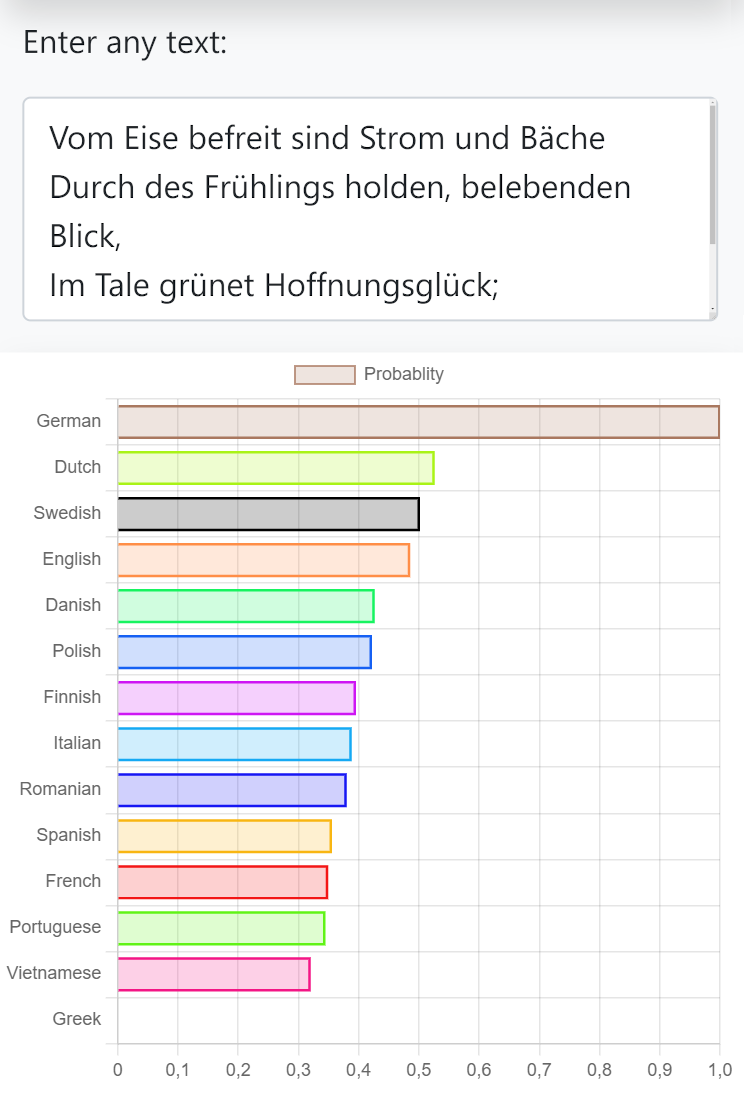
Letting the computer recognize languages is easier than you think, does not require neural networks and can be achieved with only about 5000 characters of training text for each language. The algorithm is purely based on letter frequencies and word length distribution. The foreword of "Deutschland. Ein Wintermärchen" (Heinrich Heine, 1844) and translations of it by DeepL were used as training text.
-
Calculate fingerprint for training text in each language. It consists of about 40 attributes and will be used will look like this:
{ 'wordLength_2': 0.06025641025641026,
'wordLength_3': 0.29102564102564105,
'wordLength_4': 0.11794871794871795,
...
'd': 0.05472752678155566,
'e': 0.17210060549604098,
'ä': 0.006287843502561714 }Attributes of the fingerprint are letter frequencies and word length frequencies calculated from the training text.
Calculate fingerprint for input text.
-
Calculate attribute distances for each attribute between input and each language. The attribute distance is just the ratio (always > 1) between input attribute and language attribute. The attribute similarity is 1 divided by this attribute distance.
Example:
attr1_input = 0.15
attr1_lang1 = 0.45
attr1_distance = 0.45 / 0.15 = 3
attr1_similarity = 1 / 3 = 0.3333 -
For each attribute norm the sum of attribute similarities between input and all languages to 1. This way we ensure each attribute has the same influence on the prediction.
Example:
attr1_similarity_lang1 = 0.3333
attr1_similarity_lang2 = 0.8
attr1_similarity_lang3 = 0.3667
sum = 0.3333 + 0.8 + 0.3667 = 1.5
attr1_similarity_lang1 = 0.3333 / 1.5 = 0.2222
attr1_similarity_lang2 = 0.8 / 1.5 = 0.5333
attr1_similarity_lang3 = 0.3667 / 1.5 = 0.2445
--> attr1_similarity_lang1 + attr1_similarity_lang2 + attr1_similarity_lang3 = 1 -
For each language add up attribute similarities to get the score for this language. The language with the highest score is predicted to be the language of the input.
-
(optional) Norm language scores to a value range between 0 and 1.
Unsing this simple algorithm we can also calculate similarities
between languages. This table was calculated by just inputting
the original training data for each language into the algorithm:
