Final Dataset is stored as DATASET.csv in the root folder. Feel free to use in your projects.
Example:
| State | District | Area (sq km) | Households | Total Population | Total Males | Total Females | Literate Population | Literate Males | Literate Females | Illiterate Population | Males Illiterates | Female Illiterates | Total Working Population | Total Working Males | Total Working Females | Unemployed Population | Unemployed Males | Unemployed Females | ST | SC | Hindus | Muslims | Sikhs | Buddhists | Jains | Others_Religions | Religion_Not_Stated | Households.1 | Rural_Households | Urban_Households | Households_with_Internet | MPI HCR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ANDHRA PRADESH | Adilabad | 16105.0 | 649849 | 2741239 | 1369597 | 1371642 | 1483347 | 856350 | 156831 | 1257892 | 513247 | 744645 | 1323667 | 748939 | 574728 | 1417572 | 620658 | 796914 | 495794 | 488596 | 2399901 | 275970 | 1377 | 25510 | 617 | 322 | 22120 | 817714 | 597466 | 220248 | 5512 | 27.12% |
| UTTAR PRADESH | Agra | 4041.0 | 710566 | 4418797 | 2364953 | 2053844 | 2680510 | 1614594 | 127908 | 1738287 | 750359 | 987928 | 1389844 | 1119701 | 270143 | 3028953 | 1245252 | 1783701 | 7255 | 991325 | 3922718 | 411313 | 12057 | 4049 | 21508 | 384 | 36692 | 903823 | 496971 | 406852 | 27183 | 32.83% |
This project attempts to analyse and estimate poverty indicators at the Indian district level. We consider various parameters from the 2011 census data that may be relevant to the estimation of poverty in a district, and join them with their relevant poverty indicators.
To estimate and mesaure poverty we use the multi-dimensional poverty index (MPI) based on the 2023 NITI Aayog report which has the headcount of persons under the MPI line for the years 2014 and 2019. We will be using the head-count of the 2014 MPI for each district. This data will be scraped out of the report PDF file (resources/NITI_2023.pdf), and be stored as DATASET.csv and datasets/final_dataset.csv
This project is made in dash-plotly to create a responsive dashboard fully in a python environment.
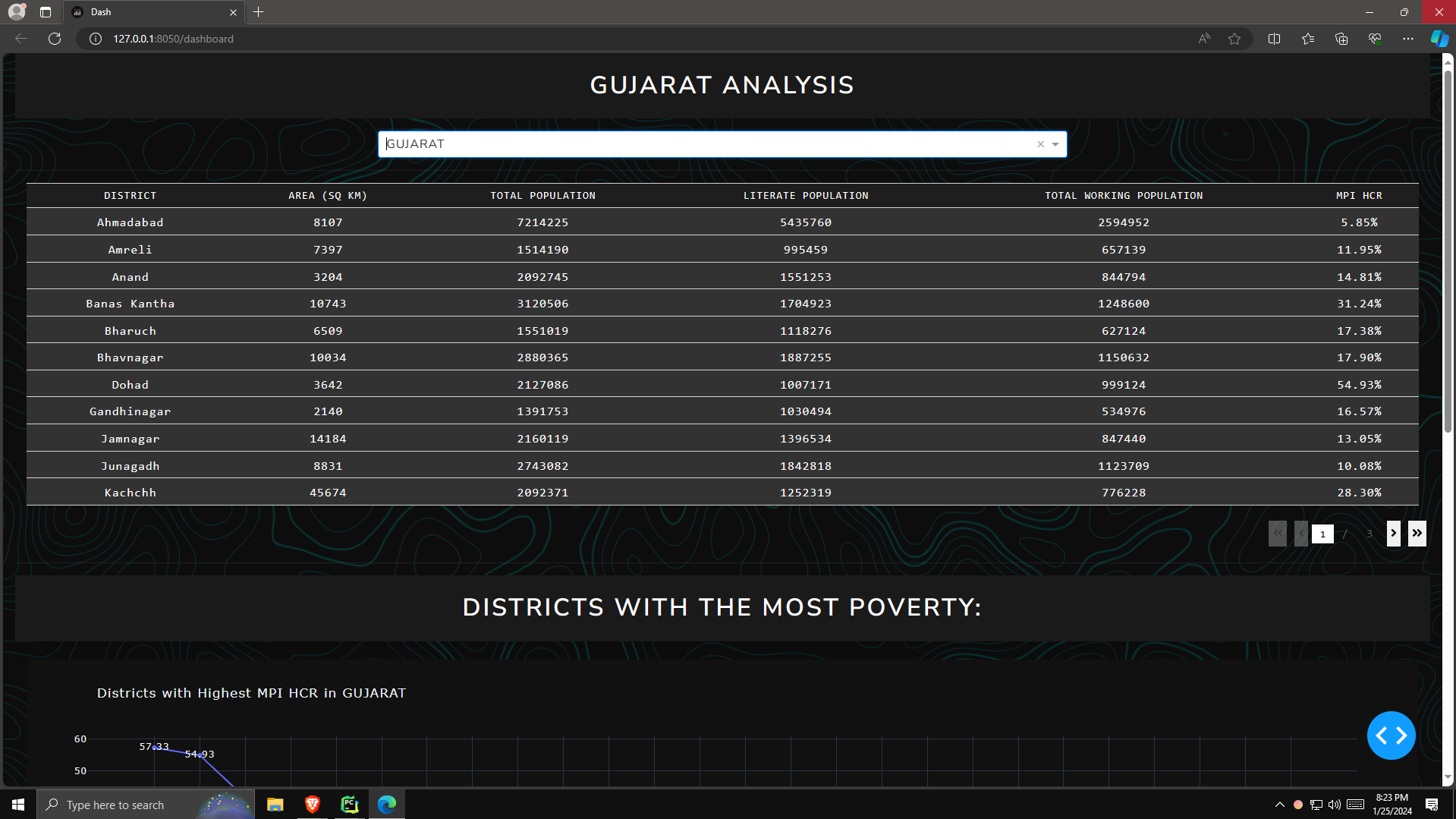
The plotly-based dashboard created looks like that. It provides 3 crucial graphs that give us crucial insights on to how the demographics of that state look, both aggregated and over the different districts.
-
A scatterplot indicating if there is a correlation b/w literate population of a district and the poverty level of the same.
-
A grouped bar graph, that compares the population, literate population, and workign population for the state segregated by sex.
-
A line plot that shows the MPI HCR level for all the districts in the state in decreasing order.

You can choose any of the administrative states or union territories as of census data of 2011. At the time of the 2011 census, there were a recorded 640 districts. The HCR values will be considered for only these districts. There is no available data for a poverty indicator at the district level in the year 2011.