Anthelion is a Nutch plugin for focused crawling of semantic data. The project is an open-source project released under the Apache License 2.0.
Note: This project contains the complete Nutch 1.6 distribution. The plugin itself can be found in /src/plugin/parse-anth
- [Nutch-Anthelion Plugin](#nutch-anthelion plugin)
- [Plugin Overview] (#plugin-overview)
- [Usage and Development] (#usage-and-development)
- [Some Results] (#some-results)
- [3rd Party Libraries] (#3rd-party-libraries)
- Anthelion
- References
The plugin uses an online learning approach to predict data-rich web pages based on the context of the page as well as using feedback from the extraction of metadata from previously seen pages [1].
To perform the focused crawling the plugin implements three extensions:
-
AnthelionScoringFilter (implements the ScoringFilter interface): wraps around the Anthelion online classifier to classify newly discovered outlinks, as relevant or not. This extension gives score to each outlink, which is then used in the Generate stage, i.e., the URLs for the next fetch cycle are selected based on the score. This extension also pushes feedback to the classifier for the already parsed web pages. The online classifier can be configured and tuned (see [Usage and Development](#usage and development)).
-
WdcParser (implements the Parser interface): This extension parses the web page content and tries to extract semantic data. The parser is adaptation of an already existing Nutch parser plugin implemented in [2]. The parser is based on the any23 library and is able to extract Microdata, Microformats and RDFa annotation from HTML. The extracted triples are stored in the Content field.
-
TripleExtractor (implements the IndexingFilter interface): This extension stores new fields to the index that can be later used for querying.
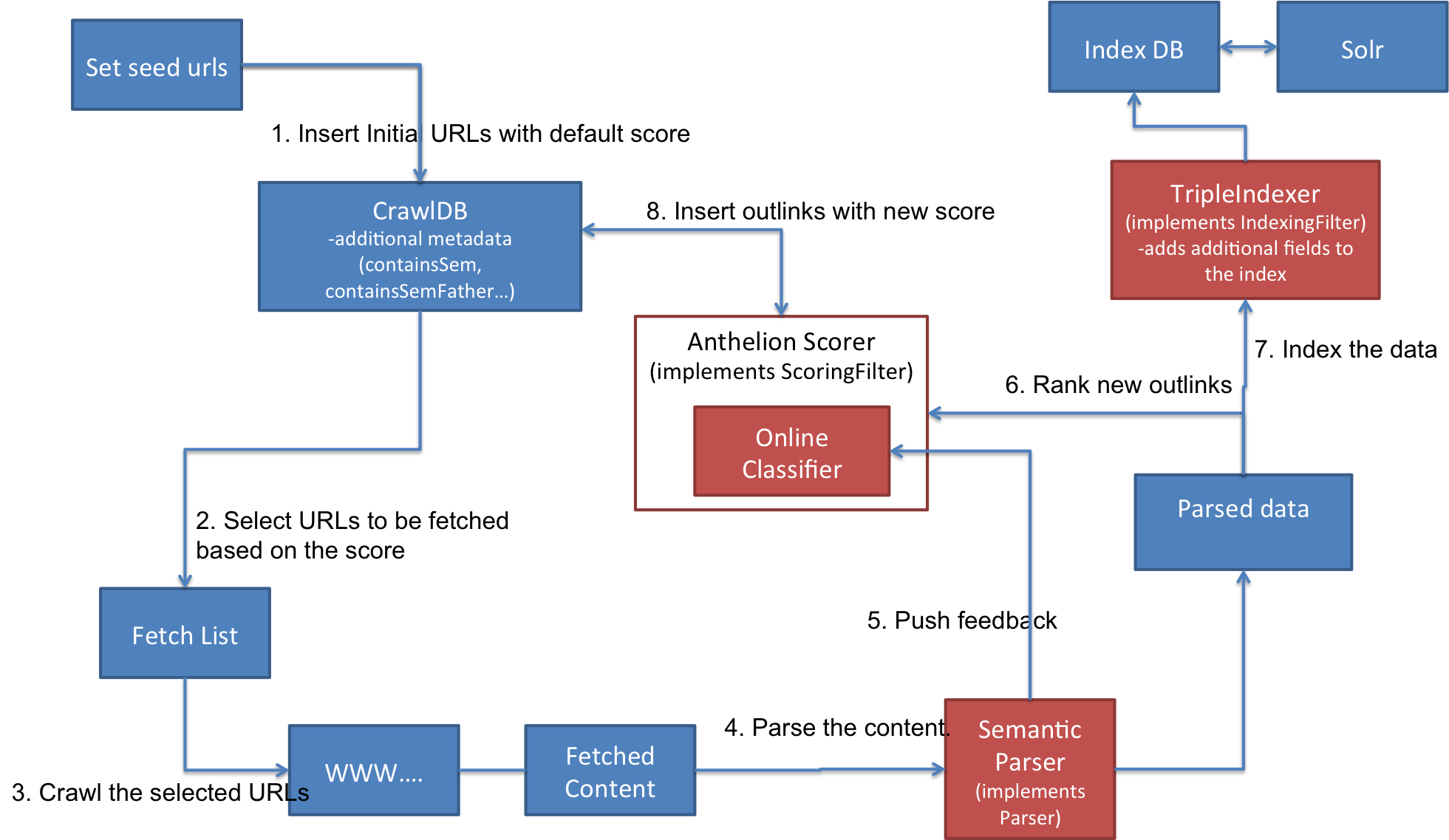
An overview of the complete crawling process using the Anthelion plugin is given in the following figure.
As mentioned in the beginning of the document this project contains the complete Nutch 1.6 code, including the plugin. If you download the complete project, there is no need for any changes and settings. If you want to download only the plugin, please download only the nutch-anth.zip from the root of the folder and go to step 2 of the configuration. If you want to contribute to the plugin and/or want to use the sources with another version of Nutch, please follow the following instructions:
-
Download and copy the /src/plugin/parse-anth folder into your Nutch's plugins directory.
-
Enable the plugin in conf/nutch-site.xml by adding parse-anth in the plugin.includes property.
-
Copy the properties from nutch-anth.xml to conf/nutch-site.xml.
3.1. Download the baseline.properties file and set the property anth.scoring.classifier.PropsFilePath conf/nutch-site.xml to point to the file. This file contains all configurations for the online classifier.
-
In order for ant to compile and deploy the plugin you need to edit the src/plugin/build.xml, by adding the following line in the deploy target:
<ant dir="parse-anth" target="deploy"/>
-
Add the following lines in conf/parse-plugins.xml:
<mimeType name="text/html"> <plugin id="parse-anth" /> </mimeType> <mimeType name="application/xhtml+xml"> <plugin id="parse-anth" /> </mimeType>
-
Add the following line in the alias property in conf/parse-plugins.xml:
<alias name="parse-anth" extension-id="com.yahoo.research.parsing.WdcParser" />
-
Copy the lib folder into the root of the Nutch distribution.
-
Run
mvn packageinside the anthelion folder. This will create the jar "Anthelion-1.0.0-jar-with-dependencies.jar". Copy the jar to src/plugin/parse-anth/lib. -
Add the following field in conf/schema.xml (also add it to the Solr schema.xml, if you are using Solr):
<field name="containsSem" type="text_general" stored="true" indexed="true"/>
-
Run ant in the root of your folder.
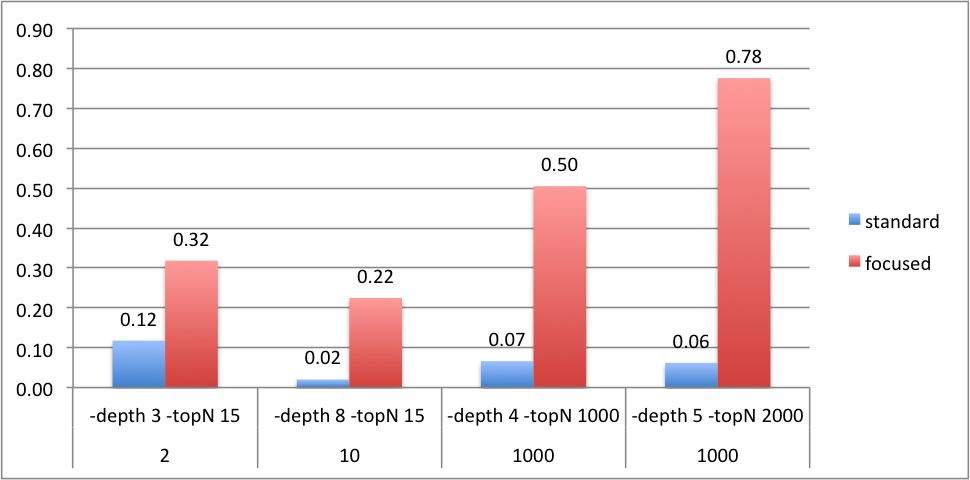
In order to evaluate the focused crawler we measure the precision of the crawled pages, i.e., the ratio of the number of crawled web pages that contain semantic data and the total number of crawled web pages. So far, we have evaluated using three different seeds sample, and several different configurations. An overview is given in the following table.
| #seeds | nutch options | standard scoring | anthelion scoring | ||||
| #total pages | #sem pages | precision | #total pages | #sem pages | precision | ||
| 2 | -depth 3 -topN 15 | 17 | 2 | 0.12 | 22 | 7 | 0.32 |
| 10 | -depth 8 -topN 15 | 99 | 2 | 0.02 | 49 | 11 | 0.22 |
| 1000 | -depth 4 -topN 1000 | 3200 | 212 | 0.07 | 2910 | 1469 | 0.50 |
| 1000 | -depth 5 -topN 2000 | 8240 | 511 | 0.06 | 9781 | 7587 | 0.78 |
The pairwise comparison is given in the following chart:
The Anthelion plugin uses several 3rd party open source libraries and tools. Here we summarize the tools used, their purpose, and the licenses under which they're released.
-
This project includes the sources of Apache Nutch 1.6 (Apache License 2.0 - http://www.apache.org/licenses/LICENSE-2.0)
-
Apache Any23 1.2 (Apache License 2.0 - http://www.apache.org/licenses/LICENSE-2.0)
- Used for extraction of semantic annotation from HTML.
- https://any23.apache.org/
- More information about the 3rd party dependencies used in the any23 library can be found here
-
The classes com.yahoo.research.parsing.WdcParser and com.yahoo.research.parsing.FilterableTripleHandler are modified versions of existing Nutch plugins (Apache License 2.0 - http://www.apache.org/licenses/LICENSE-2.0)
- Used for parsing the crawled web pages
- Hellman et al. [2]; https://www.assembla.com/spaces/commondata/subversion/source/HEAD/extractorNutch
-
For the libraries and tools used in Anthelion, please check the Anthelion [README file] (https://github.com/yahoo/anthelion/blob/master/anthelion/README.md).
For more details about the Anthelion project please check the Anthelion [README file] (https://github.com/yahoo/anthelion/blob/master/anthelion/README.md).
[1]. Meusel, Robert, Peter Mika, and Roi Blanco. "Focused Crawling for Structured Data." Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. ACM, 2014.
[2]. Hellmann, Sebastian, et al. "Knowledge Base Creation, Enrichment and Repair." Linked Open Data--Creating Knowledge Out of Interlinked Data. Springer International Publishing, 2014. 45-69.
###Troubleshooting (TODO)