- C# .NET Standard v2.1
This library can be used to scrape various IMDb title information via the static Scraper class:
via AJAX
- all user reviews
via HTML
- alternate versions page
- awards page
- crazy credits page
- critics reviews page
- FAQ page
- full credits page
- locations page
- main page
- parental guide page
- ratings page
- reference page
- soundtrack page
- taglines page
- technical page
via JSON
- all alternate titles ("Also known as" = AKAs)
- all awards
- all awards for a particular awards event (via enum)
- all awards for a particular awards event (via string)
- all awards events
- all companies
- all companies of a particular category (via enum)
- all connections
- all connections of a particular category (via enum)
- all external reviews
- all external sites
- all external sites of a particular category (via enum)
- all filming dates
- all filming locations
- all goofs
- all goofs of a particular category (via enum)
- all keywords
- all news
- all plot summaries
- all quotes
- all release dates
- all seasons
- all topics
- all trivia entries
- episodes card (2 top ranked and 2 most recent episodes, if available)
- main news (without details)
- next episode (if available)
- storyline
- suggestions (search on IMDb)
You can also use the IMDbTitle class in which the title scraping is encapsuled.
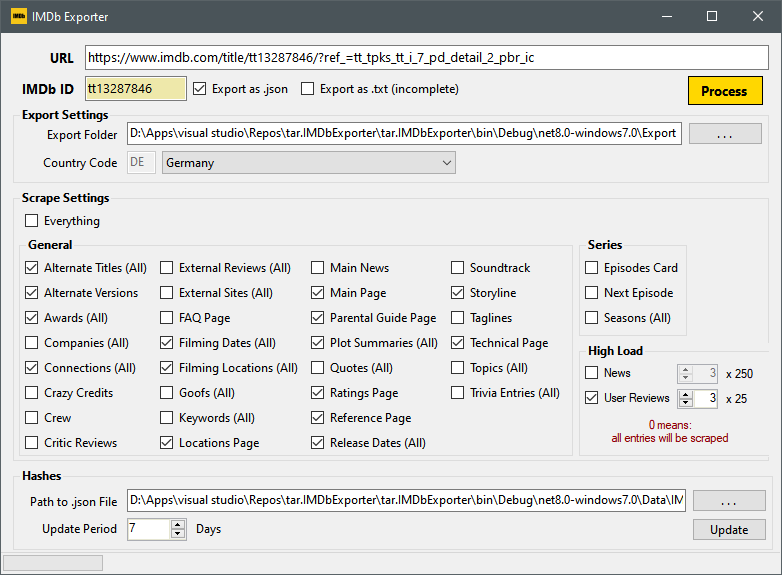
For results, see images.
Some of the methods provide incomplete data
- As long as there is no "Show more"/"All" button on any of the loaded HTML pages, the info scraped should be complete. Otherwise the corresponding JSON method needs to be used. If there is no JSON method implemented yet, the author of this library needs to be informed about the affected title.
- The full credits page could be incomplete depending on the production status.
- The critic reviews page only consists of 10 entries from metacritic.com.
- The locations page has only 5 filming dates and locations (JSON methods are implemented), but it also has production dates (no JSON method is implemented, yet).
- The main page has many infos no other method can provide, yet, but also some of those is incomplete (e.g. the technical info, therefore you need to scrape the Technical Page).
- The ratings page has a heatmap for all episode ratings which is not yet implemented.
- The reference page has (as the Main Page) some info which is incomplete.
- The storyline does provide some general plot entries but not all.
It is recommended to not scrape all information at once and it also does not make any sense to store everything in your own database which could not only be a legal issue but is also immediately outdated as the IMDb data is updated regularly. Therefore, you should only scrape and store general information (e.g. title(s), year(s), genre(s), plot(s)) and scrape the other info when you really need (to display) it. This is also due to the duration a particular scrape needs (e.g. it takes already around 42 seconds to scrape all 37 seasons of "The Simpsons" without detailed information of each episode).
IMDb regularly changes the hashes which are used for most of the requests. Use Scraper.ScrapeAllOperationHashesAsync() once in a while which automatically updates the hashes via a simulated browser window and stores those in a local .json file. You can adjust the default path [PathToYourApp]\Data\IMDbHashes.json and the DateTime to compare the last update with.
Furthermore, you can also adjust the .json file manually as follows:
- Open the corresponding site listed below with Firefox, click F12 to show the Web Dev Tools window
- Go to Network Analysis and sort by Host
- On the site, click on "More..." below the corresponding items
- In Web Dev Tools window: check new entry for File starting with "/?operationName=" to find the corresponding operation
- Copy the value from `Header Lines` -> `GET` -> `extensions` -> `sha256Hash` to the .json file
| Operation | GET-Operation-Name | Page | How to retrieve |
|---|---|---|---|
| AllAwardsEvents | AllEventsPage | https://www.imdb.com/event/all/ | no click necessary |
| AllTopics | TitleAllTopics | https://www.imdb.com/title/tt0068646/keywords/ | no click necessary |
| AlternateTitles | TitleAkasPaginated | https://www.imdb.com/title/tt0068646/releaseinfo/ | click on "More" |
| Awards | TitleAwardsSubPagePagination | https://www.imdb.com/title/tt0068646/awards/ | click on "More" |
| CompanyCredits | TitleCompanyCreditsPagination | https://www.imdb.com/title/tt0068646/companycredits/ | click on "More" |
| Connections | TitleConnectionsSubPagePagination | https://www.imdb.com/title/tt0068646/movieconnections/ | click on "More" |
| EpisodesCard | TMD_Episodes_EpisodesCardContainer | https://www.imdb.com/title/tt0072562/ | no click necessary |
| ExternalReviews | TitleExternalReviewsPagination | https://www.imdb.com/title/tt0068646/externalreviews/ | click on "More" |
| ExternalSites | TitleExternalSitesSubPagePagination | https://www.imdb.com/title/tt0068646/externalsites/ | click on "More" |
| FilmingDates | TitleFilmingDatesPaginated | https://www.imdb.com/title/tt0944947/locations/ | click on "More" |
| FilmingLocations | TitleFilmingLocationsPaginated | https://www.imdb.com/title/tt0068646/locations/ | click on "More" |
| Goofs | TitleGoofsPagination | https://www.imdb.com/title/tt0068646/goofs/ | click on "More" |
| Keywords | TitleKeywordsPagination | https://www.imdb.com/title/tt0068646/keywords/ | click on "More" |
| MainNews | TitleMainNews | https://www.imdb.com/title/tt0072562/ | only scroll down |
| News | TitleNewsPagination | https://www.imdb.com/title/tt0072562/news/ | click on "More" |
| NextEpisode | TMD_Episodes_NextEpisode | https://www.imdb.com/title/tt0072562/ | no click necessary |
| PlotSummaries | TitlePlotSummariesPaginated | https://www.imdb.com/title/tt4154796/plotsummary/ | click on "More" |
| Quotes | TitleQuotesPagination | https://www.imdb.com/title/tt0068646/quotes/ | click on "More" |
| ReleaseDates | TitleReleaseDatesPaginated | https://www.imdb.com/title/tt0068646/releaseinfo/ | click on "More" |
| Storyline | TMD_Storyline | https://www.imdb.com/title/tt0072562/ | only scroll down |
| Trivia | TitleTriviaPagination | https://www.imdb.com/title/tt0068646/trivia/ | click on "More" |
- NuGet: use tar.IMDbScraper.x.x.x.nupkg
- Manual: reference the following
- tar.IMDbScraper.dll
- HtmlAgilityPack (v1.11.48+)
- Selenium.WebDriver (v4.19.0+)
- Selenium.WebDriver.ChromeDriver (v123.0.6312.8600+)
- System.Text.Json (v7.0.3+)
- In order to receive progress information during the scraping you can register the events `Scraper.Updated` and/or `IMDbTitle.Updated`. The complete log is stored in `Scraper.ProgressLog`.
- For detailed usage, see UnitTests and the tar.IMDbExporter project.