Welcome to the Container Immersion Day Labs!
In this lab, you'll deploy a basic nodejs monolithic application using Auto Scaling & Application Load Balancer. In subsquent labs you would containerize this app using Docker and then use Amazon ECS to break this app in more manageable microservices. Let's get started!
- AWS account - if you don't have one, it's easy and free to create one.
- AWS IAM account with elevated privileges allowing you to interact with CloudFormation, IAM, EC2, ECS, ECR, ALB, VPC, CodeDeploy, CloudWatch, Cloud9. Learn how.
- Familiarity with Docker, and AWS - not required but a bonus.
- Lab Setup: Setup working environment on AWS
- Lab 1: Containerize the monolith
- Lab 2: Deploy the container using AWS Fargate
- Lab 3: Break the monolith into microservices
- Lab 4: CodeDeploy Blue/Green deployments
- Cleanup Put everything away nicely
You will be deploying infrastructure on AWS which will have an associated cost. When you're done with the lab, follow the steps at the very end of the instructions to make sure everything is cleaned up and avoid unnecessary charges.
-
Open the CloudFormation launch template link below in a new tab. The link will load the CloudFormation Dashboard and start the stack creation process in the chosen region (us-east-1 recommended):
Click on one of the Deploy to AWS icons below to region to stand up the core lab infrastructure.
| Region | Launch Template |
|---|---|
| Oregon (us-west-2) |  |
| N.Virginia (us-east-1) | |
- The template will automatically bring you to the CloudFormation Dashboard and start the stack creation process in the specified region. Give the stack a name that is unique within your account, and proceed through the wizard to launch the stack. Leave all options at their default values, but make sure to check the box to allow CloudFormation to create IAM roles on your behalf:

See the Events tab for progress on the stack launch. You can also see details of any problems here if the launch fails. Proceed to the next step once the stack status advances to "CREATE_COMPLETE".
- Access the AWS Cloud9 Environment created by CloudFormation:
On the AWS Console home page, type Cloud9 into the service search bar and select it. Find the environment named like "Project-STACK_NAME":

When you open the IDE, you'll be presented with a welcome screen that looks like this:

On the left pane (Blue), any files downloaded to your environment will appear here in the file tree. In the middle (Red) pane, any documents you open will show up here. Test this out by double clicking on README.md in the left pane and edit the file by adding some arbitrary text. Then save it by clicking File and Save. Keyboard shortcuts will work as well. On the bottom, you will see a bash shell (Yellow). For the remainder of the lab, use this shell to enter all commands. You can also customize your Cloud9 environment by changing themes, moving panes around, etc. (if you like the dark theme, you can select it by clicking the gear icon in the upper right, then "Themes", and choosing the dark theme).
- Clone the Container Immersion Day Repository:
In the bottom panel of your new Cloud9 IDE, you will see a terminal command line terminal open and ready to use. Run the following git command in the terminal to clone the necessary code to complete this tutorial:
```
$ git clone https://github.com/aajolly/container-immersion-day-15-05-2019.git
```
After cloning the repository, you'll see that your project explorer now includes the files cloned.
In the terminal, change directory to the subdirectory for this lab in the repo:
```
$ cd container-immersion-day-15-05-2019/lab-1
```
-
Run some additional automated setup steps with the
setupscript:$ script/setup
This script will delete some unneeded Docker images to free up disk space, update aws-cli version and update some packages. Make sure you see the "Success!" message when the script completes.
This is an example of a basic monolithic node.js service that has been designed to run directly on a server, without a container.
Since Node.js programs run a single threaded event loop it is necessary to use the node cluster functionality in order to get maximum usage out of a multi-core server.
In this example cluster is used to spawn one worker process per core, and the processes share a single port using round robin load balancing built into Node.js
We use an Application Load Balancer to round robin requests across multiple servers, providing horizontal scaling.

Get the ALB DNS name from cloudformation outputs stored in the file cfn-output.json and make sure the following calls work
<pre>
curl http://<<ALB_DNS_NAME>>
curl http://<<ALB_DNS_NAME>>/api
curl http://<<ALB_DNS_NAME>>/api/users | jq '.'
</pre>
The current infrastructure has always been running directly on EC2 VMs. Our first step will be to modernize how our code is packaged by containerizing the current Mythical Mysfits adoption platform, which we'll also refer to as the monolith application. To do this, you will create a Dockerfile, which is essentially a recipe for Docker to build a container image. You'll use your AWS Cloud9 development environment to author the Dockerfile, build the container image, and run it to confirm it's able to process adoptions.
Containers are a way to package software (e.g. web server, proxy, batch process worker) so that you can run your code and all of its dependencies in a resource isolated process. You might be thinking, "Wait, isn't that a virtual machine (VM)?" Containers virtualize the operating system, while VMs virtualize the hardware. Containers provide isolation, portability and repeatability, so your developers can easily spin up an environment and start building without the heavy lifting. More importantly, containers ensure your code runs in the same way anywhere, so if it works on your laptop, it will also work in production.
-
Review the Dockerfile
-
Build the image using the Docker build command.
This command needs to be run in the same directory where your Dockerfile is. Note the trailing period which tells the build command to look in the current directory for the Dockerfile.
$ docker build -t api .
You now have a Docker image built. The -t flag names the resulting container image. List your docker images and you'll see the "api" image in the list. Here's a sample output, note the api image in the list:
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE api latest 6a7abc1cc4c3 7 minutes ago 67.6MB mhart/alpine-node 8 135ddefd2040 3 weeks ago 66MB
Note: Your output will not be exactly like this, but it will be similar.
Notice the image is also tagged as "latest". This is the default behavior if you do not specify a tag of your own, but you can use this as a freeform way to identify an image, e.g. api:1.2 or api:experimental. This is very convenient for identifying your images and correlating an image with a branch/version of code as well.
- Run the docker container and test the application running as a container:
Use the docker run command to run your image; the -p flag is used to map the host listening port to the container listening port.
$ docker run --name monolith-container -p 3000:3000 api
To test the basic functionality of the monolith service, query the service using a utility like cURL, which is bundled with Cloud9.
Click on the plus sign next to your tabs and choose New Terminal or click Window -> New Terminal from the Cloud9 menu to open a new shell session to run the following curl command.
$ curl http://localhost:3000/api/users
You should see a JSON array with data about threads.
Switch back to the original shell tab where you're running the monolith container to check the output from the monolith.
The monolith container runs in the foreground with stdout/stderr printing to the screen, so when the request is received, you should see a GET.
Here is sample output:
GET /api/users - 3
In the tab you have the running container, type Ctrl-C to stop the running container. Notice, the container ran in the foreground with stdout/stderr printing to the console. In a production environment, you would run your containers in the background and configure some logging destination. We'll worry about logging later, but you can try running the container in the background using the -d flag.
$ docker run --name monolith-container -d -p 3000:3000 api
List running docker containers with the docker ps command to make sure the monolith is running.
$ docker ps
$ docker logs CONTAINER_ID or CONTAINER_NAME
Here's sample output from the above command:
$ docker logs monolith-container Worker started Worker started GET /api/users - 3
- Now that you have a working Docker image, you can tag and push the image to Elastic Container Registry (ECR). ECR is a fully-managed Docker container registry that makes it easy to store, manage, and deploy Docker container images. In the next lab, we'll use ECS to pull your image from ECR.
Create an ECR repository using the aws ecr cli. You can use the hint below
<details>
<summary>HINT: Create ECR Repository for monolith service </summary>
aws ecr create-repository --region us-east-1 --repository-name api
</details>
Take a note of the repositoryUri from the output
Retrieve the login command to use to authenticate your Docker client to your registry.
<pre>
$(aws ecr get-login --no-include-email --region us-east-1)
</pre>
Tag and push your container image to the monolith repository.
$ docker tag api:latest ECR_REPOSITORY_URI:latest $ docker push ECR_REPOSITORY_URI:latest
When you issue the push command, Docker pushes the layers up to ECR.
Here's sample output from these commands:
$ docker tag api:latest 012345678912.dkr.ecr.us-east-1.amazonaws.com/api:latest $ docker push 012345678912.dkr.ecr.us-east-1.amazonaws.com/api:latest The push refers to a repository [012345678912.dkr.ecr.us-east-1.amazonaws.com/api:latest] 0169d27ce6ae: Pushed d06bcc55d2f3: Pushed 732a53541a3b: Pushed 721384ec99e5: Pushed latest: digest: sha256:2d27533d5292b7fdf7d0e8d41d5aadbcec3cb6749b5def8b8ea6be716a7c8e17 size: 1158
View the latest image pushed and tagged in the ECR repository
aws ecr describe-images --repository-name api
{ "imageDetails": [ { "imageSizeInBytes": 22702204, "imageDigest": "sha256:2d27533d5292b7fdf7d0e8d41d5aadbcec3cb6749b5def8b8ea6be716a7c8e17", "imageTags": [ "latest" ], "registryId": "012345678912", "repositoryName": "api", "imagePushedAt": 1557648496.0 } ] }
At this point, you should have a working container for the monolith codebase stored in an ECR repository and ready to deploy with ECS in the next lab.
Deploying individual containers is not difficult. However, when you need to coordinate many container deployments, a container management tool like ECS can greatly simplify the task.
ECS refers to a JSON formatted template called a Task Definition that describes one or more containers making up your application or service. The task definition is the recipe that ECS uses to run your containers as a task on your EC2 instances or AWS Fargate.
<details>
<summary>INFO: What is a task? </summary>
A task is a running set of containers on a single host. You may hear or see 'task' and 'container' used interchangeably. Often, we refer to tasks instead of containers because a task is the unit of work that ECS launches and manages on your cluster. A task can be a single container, or multiple containers that run together.
</details>
Most task definition parameters map to options and arguments passed to the docker run command which means you can describe configurations like which container image(s) you want to use, host:container port mappings, cpu and memory allocations, logging, and more.
In this lab, you will create a task definition to serve as a foundation for deploying the containerized adoption platform stored in ECR with ECS. You will be using the Fargate launch type, which let's you run containers without having to manage servers or other infrastructure. Fargate containers launch with a networking mode called awsvpc, which gives ECS tasks the same networking properties of EC2 instances. Tasks will essentially receive their own elastic network interface. This offers benefits like task-specific security groups. Let's get started!
Note:* You will use the AWS CLI for this lab, but remember that you can accomplish the same thing using the AWS Console, SDKs, or CloudFormation.
-
Create an ECS Cluster which will host all services
aws ecs create-cluster --cluster-name "my_first_ecs_cluster" --region us-east-1
-
Create IAM roles for use with ECS
The 3 roles required are mentioned below
-
AWSServiceRoleForECS: This is an IAM role which authorizes ECS to manage resources on your account on your behalf, such as updating your load balancer with the details of where your containers are, so that traffic can reach your containers. Use the command below to check if this role exists
aws iam get-role --region us-east-1 --role-name AWSServiceRoleForECS
If it doesn't exist, you can create it using the following command
aws iam create-service-linked-role --aws-service-name ecs.amazonaws.com
-
TaskRole: This is a role which is used by the ECS tasks. Tasks in Amazon ECS define the containers that should be deployed togehter and the resources they require from a compute/memory perspective. So, the policies below will define the IAM permissions that your docker containers will have. If you write any code for the service that interactes with different AWS service APIs, these roles would need to include those as allowed actions. Create this role using the command line below:
Create a file with name <user_name>_iam-trust-relationship.json that contains:
{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Principal": { "Service": ["ec2.amazonaws.com", "ecs-tasks.amazonaws.com"] }, "Action": "sts:AssumeRole" }] }Create the IAM role:
aws iam create-role --role-name ECSTaskRole --path "/service-role/" --assume-role-policy-document file://<user_name>_iam-trust-relationship.json
Create the policy named <user_name>_ECSTaskRole-Policy.json
{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage" ], "Resource": "" }, { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:GetBucketPolicy", "s3:GetObject", "s3:GetObjectAcl", "s3:PutObject", "s3:PutBucketPolicy" ], "Resource": "arn:aws:s3:::" }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:::*" } ] }Attach the policy with the role:
aws iam put-role-policy --role-name ECSTaskRole --policy-name ECSTaskRole_Policy --policy-document file://<user_name>_ECSTaskRole-policy.json
-
ECSTaskExecutionRole: The Amazon ECS container agent makes calls to the Amazon ECS API on your behalf, so it requires an IAM policy and role for the service to know that the agent belongs to you. It is more convenient to create this role using the console as there is a managed policy for this role.
Create the role by selecting Elastic Container Service as the service and then selecting Elastic Container Service Task as the use case. For the permissions, search for AmazonECSTaskExecutionRolePolicy
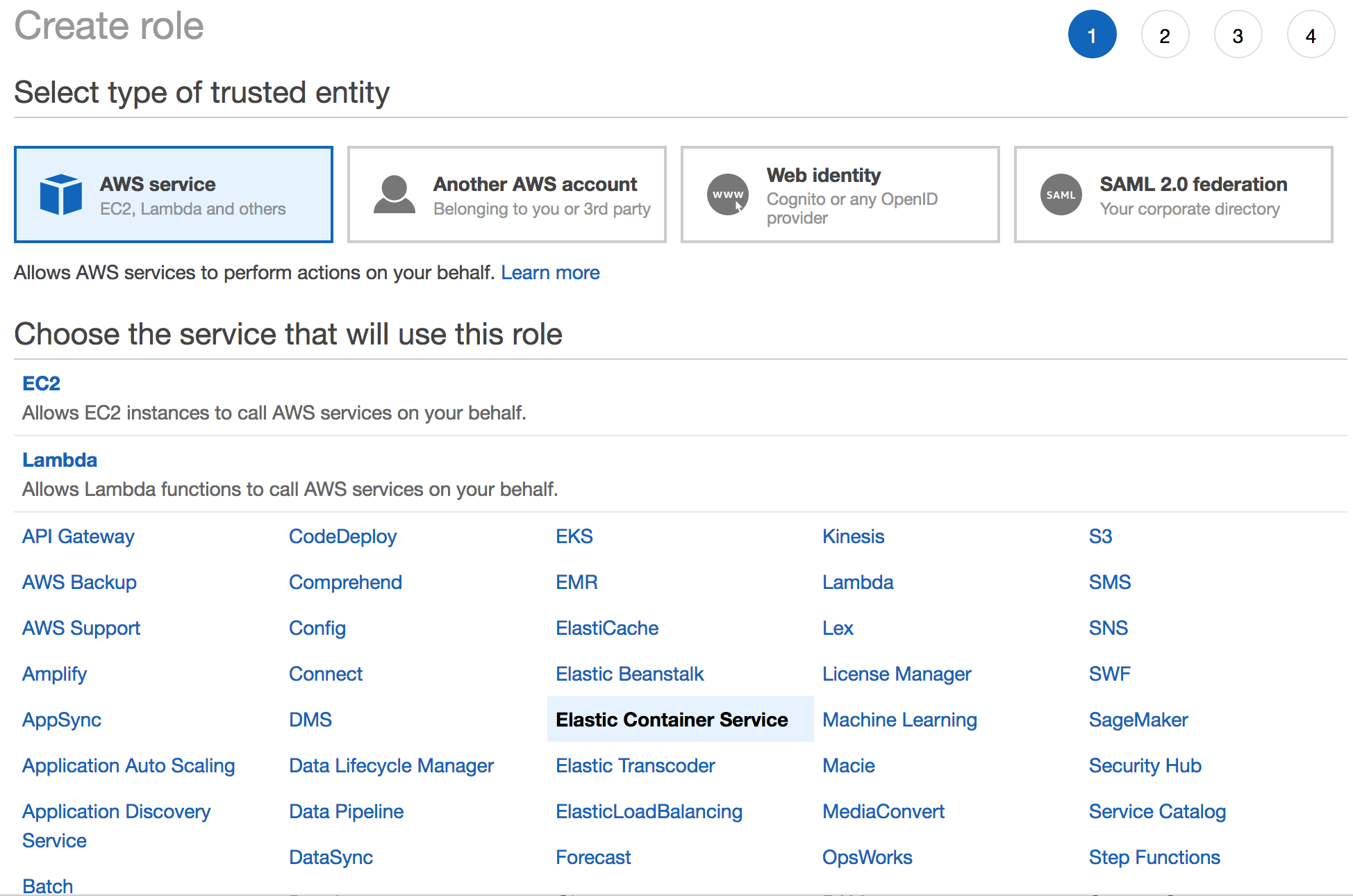
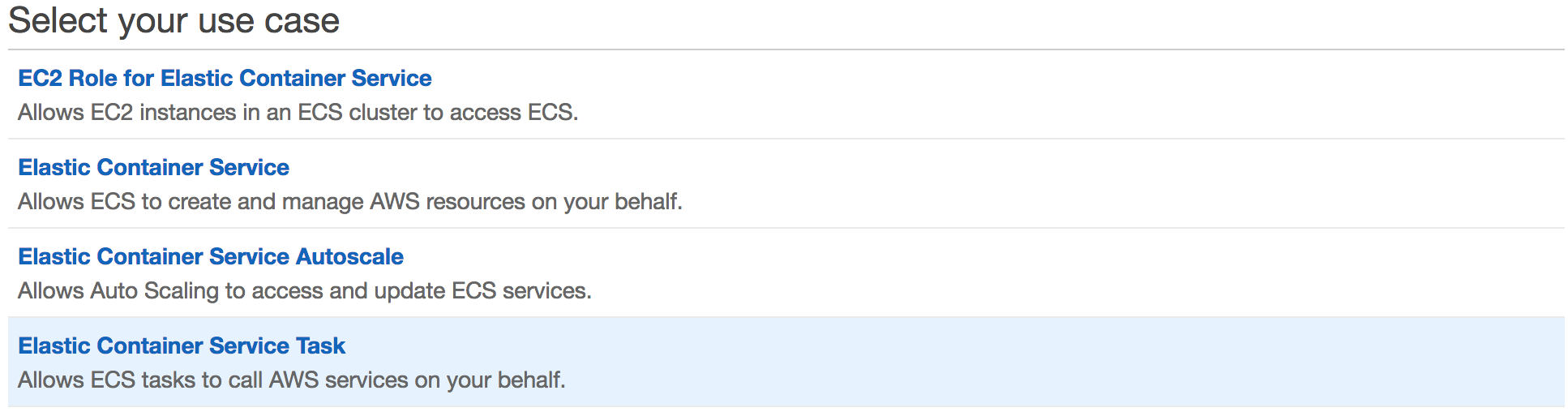


- Create an ECS task definition that describes what is needed to run the monolith.
Before you can run a task on your ECS cluster, you must register a task definition. Task definitions are lists of containers grouped together. Below is an example for our monolith app, name this fargate-task-def.json
{
"requiresCompatibilities": [
"FARGATE"
],
"containerDefinitions": [
{
"name": "monolith-cntr1",
"image": "012345678912.dkr.ecr.us-east-1.amazonaws.com/api:latest",
"memoryReservation": 128,
"essential": true,
"portMappings": [
{
"containerPort": 3000,
"protocol": "tcp"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/monolith-task-def",
"awslogs-region": "us-east-1",
"awslogs-stream-prefix": "ecs"
}
}
}
],
"volumes": [],
"networkMode": "awsvpc",
"memory": "512",
"cpu": "256",
"executionRoleArn": "arn:aws:iam::012345678912:role/ECSTaskExecutionRole",
"taskRoleArn": "arn:aws:iam::012345678912:role/ECSTaskRole",
"family": "monolith-task-def"
}
Note: Replace the placeholder account number with your account number.
- Check the CloudWatch logging settings in the container definition.
In the previous lab, you attached to the running container to get stdout, but no one should be doing that in production and it's good operational practice to implement a centralized logging solution. ECS offers integration with CloudWatch logs through an awslogs driver that can be enabled in the container definition.
Take note of the log configuration i.e. in the logGroup = /ecs/monolith-task-def Create a log group with the same name in cloudwatch logs, else your tasks would fail to start.
aws logs create-log-group --log-group-name "/ecs/monolith-task-def"
-
Register the task definition using the task definition json file we created above.
aws ecs register-task-definition --cli-input-json file://fargate-task-def.json
List task definitions using the below command
aws ecs list-task-definitions
-
Create a new Target Group
<pre> aws elbv2 create-target-group \ --region us-east-1 \ --name monolith-cntr-tg \ --vpc-id <b>vpc-010b11d3ad023b4ed</b> \ --port 3000 \ --protocol HTTP \ --target-type ip \ --health-check-protocol HTTP \ --health-check-path / \ --health-check-interval-seconds 6 \ --health-check-timeout-seconds 5 \ --healthy-threshold-count 2 \ --unhealthy-threshold-count 2 \ --query "TargetGroups[0].TargetGroupArn" \ --output text </pre>
Note: Replace the vpc-id with your specific id. You should be able to get the VPCId for your specific account from the cfn-output.json file. The output of the above command will provide the TargetGroup ARN, make a note of it.
Now lets modify the listener to point the load balancer to this new target group
<pre>
Get the listener-arn
aws elbv2 describe-listeners \
--region us-east-1 \
--query "Listeners[0].ListenerArn" \
--load-balancer-arn arn:aws:elasticloadbalancing:us-east-1:<b>012345678912</b>:loadbalancer/app/alb-container-labs/86a05a2486126aa0/0e0cffc93cec3218 \
--output text
Modify the listener
aws elbv2 modify-listener \
--region us-east-1 \
--listener-arn arn:aws:elasticloadbalancing:us-east-1:<b>012345678912</b>:listener/app/alb-container-labs/86a05a2486126aa0/0e0cffc93cec3218 \
--query "Listeners[0].ListenerArn" \
--default-actions Type=forward,TargetGroupArn=arn:aws:elasticloadbalancing:us-east-1:<b>012345678912</b>:targetgroup/monolith-cntr-tg/566b90ffcc10985e \
--output text
</pre>
**Note:** Replace the placeholder arn's with your own arns. Make a note of the listener arn.
- Create a new service now
Amazon ECS allows you to run and maintain a specified number of instances of a task definition simultaneously in an Amazon ECS cluster. This is called a service. If any of your tasks should fail or stop for any reason, the Amazon ECS service scheduler launches another instance of your task definition to replace it and maintain the desired count of tasks in the service depending on the scheduling strategy used. Create a file named ecs-service.json with the following parameters
<pre>
{
"cluster": "my_first_ecs_cluster",
"serviceName": "monolith-service",
"taskDefinition": "monolith-task-def:1",
"loadBalancers": [
{
"targetGroupArn": "arn:aws:elasticloadbalancing:us-east-1:**012345678912**:targetgroup/monolith-cntr-tg/566b90ffcc10985e",
"containerName": "monolith-cntr",
"containerPort": 3000
}
],
"desiredCount": 2,
"clientToken": "",
"launchType": "FARGATE",
"networkConfiguration": {
"awsvpcConfiguration": {
"subnets": [
"**subnet-06437a4061211691a**","**subnet-0437c573c37bbd689**"
],
"securityGroups": [
"**sg-0f01c67f9a810f62a**"
],
"assignPublicIp": "DISABLED"
}
},
"deploymentController": {
"type": "ECS"
}
}
</pre>
Note: Replace all placeholders for targetGroupArn, subnets & securityGroups with your account specific values for those parameters. You should be able to find these using the cfn-outputs.json file. The subnets used here are the private subnets.
Create service using the command below
aws ecs create-service
--region us-east-1
--cluster my_first_ecs_cluster
--service-name monolith-service
--cli-input-json file://ecs-service.json
Run the same curl command as before (or view the load balancer endpoint in your browser) and ensure that you get a response which says it runs on a container.
<details>
<summary>HINT: CURL Commands</summary>
<pre>
curl http://<<ALB_DNS_NAME>>
curl http://<<ALB_DNS_NAME>>/api
curl http://<<ALB_DNS_NAME>>/api/users | jq '.'
</pre>
</details>
Nice work! You've created a task definition and are able to deploy the monolith container using ECS. You've also enabled logging to CloudWatch Logs, so you can verify your container works as expected.
Take this lab as a challange where you break this monolith into microservices. Below is a quick reference architecture for microservices on ECS.

Define microservice boundaries: Defining the boundaries for services is specific to your application's design, but for this REST API one fairly clear approach to breaking it up is to make one service for each of the top level classes of objects that the API serves:
/api/users/* -> A service for all user related REST paths
/api/posts/* -> A service for all post related REST paths
/api/threads/* -> A service for all thread related REST paths
So each service will only serve one particular class of REST object, and nothing else.
There are no instructions for this lab, however you can find the relevant resources in folder named lab-2
Sweet! Now you have a load-balanced ECS service managing your containerized Mythical Mysfits application. It's still a single monolith container, but we'll work on breaking it down next.
In AWS CodeDeploy, blue/green deployments help you minimize downtime during application updates. They allow you to launch a new version of your application alongside the old version and test the new version before you reroute traffic to it. You can also monitor the deployment process and, if there is an issue, quickly roll back.
With this new capability, you can create a new service in AWS Fargate or Amazon ECS that uses CodeDeploy to manage the deployments, testing, and traffic cutover for you. When you make updates to your service, CodeDeploy triggers a deployment. This deployment, in coordination with Amazon ECS, deploys the new version of your service to the green target group, updates the listeners on your load balancer to allow you to test this new version, and performs the cutover if the health checks pass.
Note: Although not necessary, however it is useful if you have completed lab-3 above i.e. breaking the monolith into microservices.
- Setup an IAM service role for CodeDeploy
Because you will be using AWS CodeDeploy to handle the deployments of your application to Amazon ECS, AWS CodeDeploy needs permissions to call Amazon ECS APIs, modify your load balancers, invoke Lambda functions, and describe CloudWatch alarms. Before you create an Amazon ECS service that uses the blue/green deployment type, you must create the AWS CodeDeploy IAM role (ecsCodeDeployServiceRole).
-
Create a file named CodeDeploy-iam-trust-policy.json
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": [ "codedeploy.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] } -
Create the role with name ecsCodeDeployServiceRole
aws iam create-role --role-name ecsCodeDeployServiceRole --assume-role-policy-document file://CodeDeploy-iam-trust-policy.json
-
Since the compute platform we'll be working with is ECS, use the managed policy AWSCodeDeployRoleForECS
aws iam attach-role-policy --role-name ecsCodeDeployServiceRole --policy-arn arn:aws:iam::aws:policy/service-role/AWSCodeDeployRoleForECS
- Lets pick threads service for this lab.
Since the services we deployed in previous labs use ECS as the deployment controller, it is not possible to change this configuration using the update-service API call. Hence, we need to either a) delete the service or, b) create a new service with a different deployment controller i.e. CODE_DEPLOY. For this lab, we'll go with option a)
-
Change the desired count for this service to 0
aws ecs update-service \ --region us-east-1 \ --cluster my_first_ecs_cluster \ --service threads \ --desired-count 0
Note: Wait for the running count to be 0
aws ecs describe-services \ --region us-east-1 \ --cluster my_first_ecs_cluster \ --service threads \ --query "services[*].taskSets[*].runningCount"
-
Delete the service once the runningCount = 0
aws ecs delete-service \ --region us-east-1 \ --cluster my_first_ecs_cluster \ --service threads
-
Lets update the db.json file for threads microservice and add another thread to it.
-
Once done, build a new docker image with a tag of 0.1. Tag & push this image to ECR repository of threads. By now, you should be familiar with this process.
-
Re-use the taskDefinition file for threads i.e. fargate-task-def-threads.json
-
Update the ecs-service-threads.json file to reflect CODE_DEPLOY as the deployment controller
{ "cluster": "my_first_ecs_cluster", "serviceName": "threads", "taskDefinition": "threads-task-def:1", "loadBalancers": [ { "targetGroupArn": "arn:aws:elasticloadbalancing:us-east-1:776055576349:targetgroup/threads-tg/b61b2b03ecb4c757", "containerName": "threads-cntr", "containerPort": 3000 } ], "desiredCount": 1, "clientToken": "", "launchType": "FARGATE", "schedulingStrategy": "REPLICA", "networkConfiguration": { "awsvpcConfiguration": { "subnets": [ "subnet-06437a4061211691a","subnet-0437c573c37bbd689" ], "securityGroups": [ "sg-0f01c67f9a810f62a" ], "assignPublicIp": "DISABLED" } }, "deploymentController": { "type": "CODE_DEPLOY" } } -
Re-create the threads service
aws ecs create-service \ --region us-east-1 \ --cluster my_first_ecs_cluster \ --service-name threads \ --cli-input-json file://ecs-service-threads.json
-
Create a new target group & a listener for green environment
These will be referenced in the deployment-group you'd create for CodeDeploy.
-
Target Group
aws elbv2 create-target-group \ --region us-east-1 \ --name threads-tg-2 \ --vpc-id VPCId \ --port 3000 \ --protocol HTTP \ --target-type ip \ --health-check-protocol HTTP \ --health-check-path / \ --health-check-interval-seconds 6 \ --health-check-timeout-seconds 5 \ --healthy-threshold-count 2 \ --unhealthy-threshold-count 2 \ --query "TargetGroups[0].TargetGroupArn" \ --output text
-
Listener with a different port
aws elbv2 create-listener \ --region us-east-1 \ --load-balancer-arn arn:aws:elasticloadbalancing:us-east-1:012345678912:loadbalancer/app/alb-container-labs/86a05a2486126aa0 \ --port 8080 \ --protocol HTTP \ --default-actions Type=forward,TargetGroupArn=arn:aws:elasticloadbalancing:us-east-1:012345678912:targetgroup/threads-tg-2/b0ce12f4f6957bb7 \ --query "Listener[0].Listener.Arn" \ --output text
Note: Make note of the targetGroupArn & listenerArn
- Create CodeDeploy resources
-
Create the application which is a collection of deployment groups and revisions.
INFO: What is an Application?
A name that uniquely identifies the application you want to deploy. CodeDeploy uses this name, which functions as a container, to ensure the correct combination of revision, deployment configuration, and deployment group are referenced during a deployment.aws deploy create-application \ --region us-east-1 \ --application-name threadsApp \ --compute-platform ECS
-
Create an input json file for deployment-group named deployment-group-threads.json
INFO: What is a Deployment Group?
From an Amazon ECS perspective, specifies the Amazon ECS service with the containerized application to deploy as a task set, a production and optional test listener used to serve traffic to the deployed application, when to reroute traffic and terminate the deployed application's original task set, and optional trigger, alarm, and rollback settings.{ "applicationName": "threadsApp", "deploymentGroupName": "threadsDG", "deploymentConfigName": "CodeDeployDefault.ECSAllAtOnce", "serviceRoleArn": "arn:aws:iam::012345678912:role/ecsCodeDeployServiceRole", "ecsServices": [ { "serviceName": "threads", "clusterName": "my\_first\_ecs\_cluster" } ], "alarmConfiguration": { "enabled": false, "ignorePollAlarmFailure": true, "alarms": [] }, "autoRollbackConfiguration": { "enabled": true, "events": [ "DEPLOYMENT_FAILURE", "DEPLOYMENT\_STOP\_ON\_REQUEST", "DEPLOYMENT\_STOP\_ON\_ALARM" ] }, "deploymentStyle": { "deploymentType": "BLUE_GREEN", "deploymentOption": "WITH\_TRAFFIC\_CONTROL" }, "blueGreenDeploymentConfiguration": { "terminateBlueInstancesOnDeploymentSuccess": { "action": "TERMINATE", "terminationWaitTimeInMinutes": 5 }, "deploymentReadyOption": { "actionOnTimeout": "CONTINUE_DEPLOYMENT", "waitTimeInMinutes": 0 } }, "loadBalancerInfo": { "targetGroupPairInfoList": [ { "targetGroups": [ { "name": "threads-tg" }, { "name": "threads-tg-2" } ], "prodTrafficRoute": { "listenerArns": [ "arn:aws:elasticloadbalancing:us-east-1:012345678912:listener/app/alb-container-labs/86a05a2486126aa0/0e0cffc93cec3218" ] }, "testTrafficRoute": { "listenerArns": [ "arn:aws:elasticloadbalancing:us-east-1:012345678912:listener/app/alb-container-labs/86a05a2486126aa0/d3336ca308561265" ] } } ] } }aws deploy create-deployment-group \ --region us-east-1 \ --cli-input-json file://deployment-group-threads.json
-
Creating a lifecycle hook for testing the new release. As discussed in the theory session, these are very helpful. The content in the 'hooks' section of the AppSpec file varies, depending on the compute platform for your deployment. The 'hooks' section for an EC2/On-Premises deployment contains mappings that link deployment lifecycle event hooks to one or more scripts. The 'hooks' section for an Amazon ECS deployment specifies Lambda validation functions to run during a deployment lifecycle event. If an event hook is not present, no operation is executed for that event. This section is required only if you are running scripts or Lambda validation functions as part of the deployment. So there are two parts to creating a hook, first an IAM role needs to be created which is used by lambda to pass back the testing results to CodeDeploy. You can either create the role using the CLI with the following policies
-
Managed Policy - AWSLambdaBasicExecutionRole for CloudWatch logs
-
And a new policy with the following permissions
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "codedeploy:PutLifecycleEventHookExecutionStatus" ], "Resource": "arn:aws:codedeploy:us-east-1:012345678912:deploymentgroup:*", "Effect": "Allow" } ] }
-
-
Change directory to lab-3/hooks, do npm install and zip the contents.
-
Create a lambda function
aws lambda create-function \ --region us-east-1 --function-name CodeDeployHook_pre-traffic-hook \ --zip-file fileb://file-path/file.zip \ --role role-arn \ --environment Variables={TargetUrl=http://alb-container-labs-1439628024.us-east-1.elb.amazonaws.com:8080/api/threads} \ --handler pre-traffic-hook.handler \ --runtime nodejs8.10
Note: Feel free to review the configuration of the lambda function, its a simple check to verify the API works, however you can add other validation checks as well.
-
Create an AppSpec file. It is used to manage each deployment as a series of lifecycle event hooks, which are defined in the file. For ECS as the compute platform, it can be either YAML or JSON formatted. For this lab, we'll use JSON.
{ "version": 0.0, "Resources": [ { "TargetService": { "Type": "AWS::ECS::Service", "Properties": { "TaskDefinition": "threads-task-def:1", "LoadBalancerInfo": { "ContainerName": "threads-cntr", "ContainerPort": 3000 }, "PlatformVersion": "LATEST", "NetworkConfiguration": { "awsvpcConfiguration": { "subnets": [ "subnet-06437a4061211691a","subnet-0437c573c37bbd689" ], "securityGroups": [ "sg-0f01c67f9a810f62a" ], "assignPublicIp": "DISABLED" } } } } } ], "Hooks": [ { "BeforeAllowTraffic": "CodeDeployHook_pre-traffic-hook" } ] } -
Start the deployment using the new aws ecs deloy CLI commands
aws ecs deploy \ --region us-east-1 \ --cluster my\_first\_ecs\_cluster \ --service threads \ --task-definition fargate-task-def-threads.json \ --codedeploy-appspec appspec.json \ --codedeploy-application threadsApp \ --codedeploy-deployment-group threadsDG
Note: The above will trigger a CodeDeploy Deployment, you can view the status of this deployment, at the end of it, it should look like 
If you now make some changes to the docker container threads, for example add another thread to db.json file and build a new container with a tag 0.1 + push to ECR. You can then create a revision of task definition and specifying the new image. During this process, selecting the existing CodeDeploy Application & Deployment-Group. This should trigger a new deployment in CodeDeploy and you can monitor the status in a similar way. Also feel free to check lambda logs in CloudWatch and add some of your own tests to this lambda.
Congratulations, you've successfully deployed a service with blue/green deployments from CodeDeploy and with 0 downtime. If you have time, convert the other services to blue/green as well. Otherwise, please remember to follow the steps below in the Lab Cleanup to make sure all assets created during the workshop are removed so you do not see unexpected charges after today.
This is really important because if you leave stuff running in your account, it will continue to generate charges. Certain things were created by CloudFormation and certain things were created manually throughout the workshop. Follow the steps below to make sure you clean up properly.
Delete manually created resources throughout the labs:
- ECS service(s) - first update the desired task count to be 0. Then delete the ECS service itself.
- Delete the ECS cluster as well
- ECR - delete any Docker images pushed to your ECR repository.
- CloudWatch log groups
- Delete the newly created Target groups for microservices
- Remove the project folder(container-immersion-day-15-05-2019) from cloud9 using the rm -vrf command
- Delete the cloudformation stack