Twitter GraphQL API implementation with SNScrape data models.
pip install twscrapeOr development version:
pip install git+https://github.com/vladkens/twscrape.git- Support both Search & GraphQL Twitter API
- Async/Await functions (can run multiple scrapers in parallel at the same time)
- Login flow (with receiving verification code from email)
- Saving/restoring account sessions
- Raw Twitter API responses & SNScrape models
- Automatic account switching to smooth Twitter API rate limits
Since this project works through an authorized API, accounts need to be added. You can register and add an account yourself. You can also google sites that provide these things.
The email password is needed to get the code to log in to the account automatically (via imap protocol).
Data models:
import asyncio
from twscrape import API, gather
from twscrape.logger import set_log_level
async def main():
api = API() # or API("path-to.db") - default is `accounts.db`
# ADD ACCOUNTS (for CLI usage see BELOW)
await api.pool.add_account("user1", "pass1", "u1@example.com", "mail_pass1")
await api.pool.add_account("user2", "pass2", "u2@example.com", "mail_pass2")
await api.pool.login_all()
# or add account with COOKIES (with cookies login not required)
cookies = "abc=12; ct0=xyz" # or '{"abc": "12", "ct0": "xyz"}'
await api.pool.add_account("user3", "pass3", "u3@mail.com", "mail_pass3", cookies=cookies)
# add account with PROXY
proxy = "http://login:pass@example.com:8080"
await api.pool.add_account("user4", "pass4", "u4@mail.com", "mail_pass4", proxy=proxy)
# API USAGE
# search (latest tab)
await gather(api.search("elon musk", limit=20)) # list[Tweet]
# tweet info
tweet_id = 20
await api.tweet_details(tweet_id) # Tweet
await gather(api.retweeters(tweet_id, limit=20)) # list[User]
await gather(api.favoriters(tweet_id, limit=20)) # list[User]
# get user by login
user_login = "twitterdev"
await api.user_by_login(user_login) # User
# user info
user_id = 2244994945
await api.user_by_id(user_id) # User
await gather(api.followers(user_id, limit=20)) # list[User]
await gather(api.following(user_id, limit=20)) # list[User]
await gather(api.user_tweets(user_id, limit=20)) # list[Tweet]
await gather(api.user_tweets_and_replies(user_id, limit=20)) # list[Tweet]
# list info
list_id = 123456789
await gather(api.list_timeline(list_id))
# NOTE 1: gather is a helper function to receive all data as list, FOR can be used as well:
async for tweet in api.search("elon musk"):
print(tweet.id, tweet.user.username, tweet.rawContent) # tweet is `Tweet` object
# NOTE 2: all methods have `raw` version (returns `httpx.Response` object):
async for rep in api.search_raw("elon musk"):
print(rep.status_code, rep.json()) # rep is `httpx.Response` object
# change log level, default info
set_log_level("DEBUG")
# Tweet & User model can be converted to regular dict or json, e.g.:
doc = await api.user_by_id(user_id) # User
doc.dict() # -> python dict
doc.json() # -> json string
if __name__ == "__main__":
asyncio.run(main())In order to correctly release an account in case of break in loop, a special syntax must be used. Otherwise, Python's events loop will release lock on the account sometime in the future. See explanation here.
from contextlib import aclosing
async with aclosing(api.search("elon musk")) as gen:
async for tweet in gen:
if tweet.id < 200:
break# show all commands
twscrape
# help on specific comand
twscrape search --helpFirst add accounts from file:
# twscrape add_accounts <file_path> <line_format>
# line_format should have "username", "password", "email", "email_password" tokens
# note: tokens delimeter should be same as an file
twscrape add_accounts ./accounts.txt username:password:email:email_passwordThen call login:
twscrape login_accountsAccounts and their sessions will be saved, so they can be reused for future requests
Note: Possible to use _ in line_format to skip some value
Use cookies param in line_format, e.g.:
twscrape add_accounts ./accounts.txt username:password:email:email_password:cookiesIn this case login not required.
twscrape accounts
# Output:
# username logged_in active last_used total_req error_msg
# user1 True True 2023-05-20 03:20:40 100 None
# user2 True True 2023-05-20 03:25:45 120 None
# user3 False False None 120 Login errorIt is possible to re-login specific accounts:
twscrape relogin user1 user2Or retry login for all failed logins:
twscrape relogin_failedUseful if using a different set of accounts for different actions
twscrape --db test-accounts.db <command>
twscrape search "QUERY" --limit=20
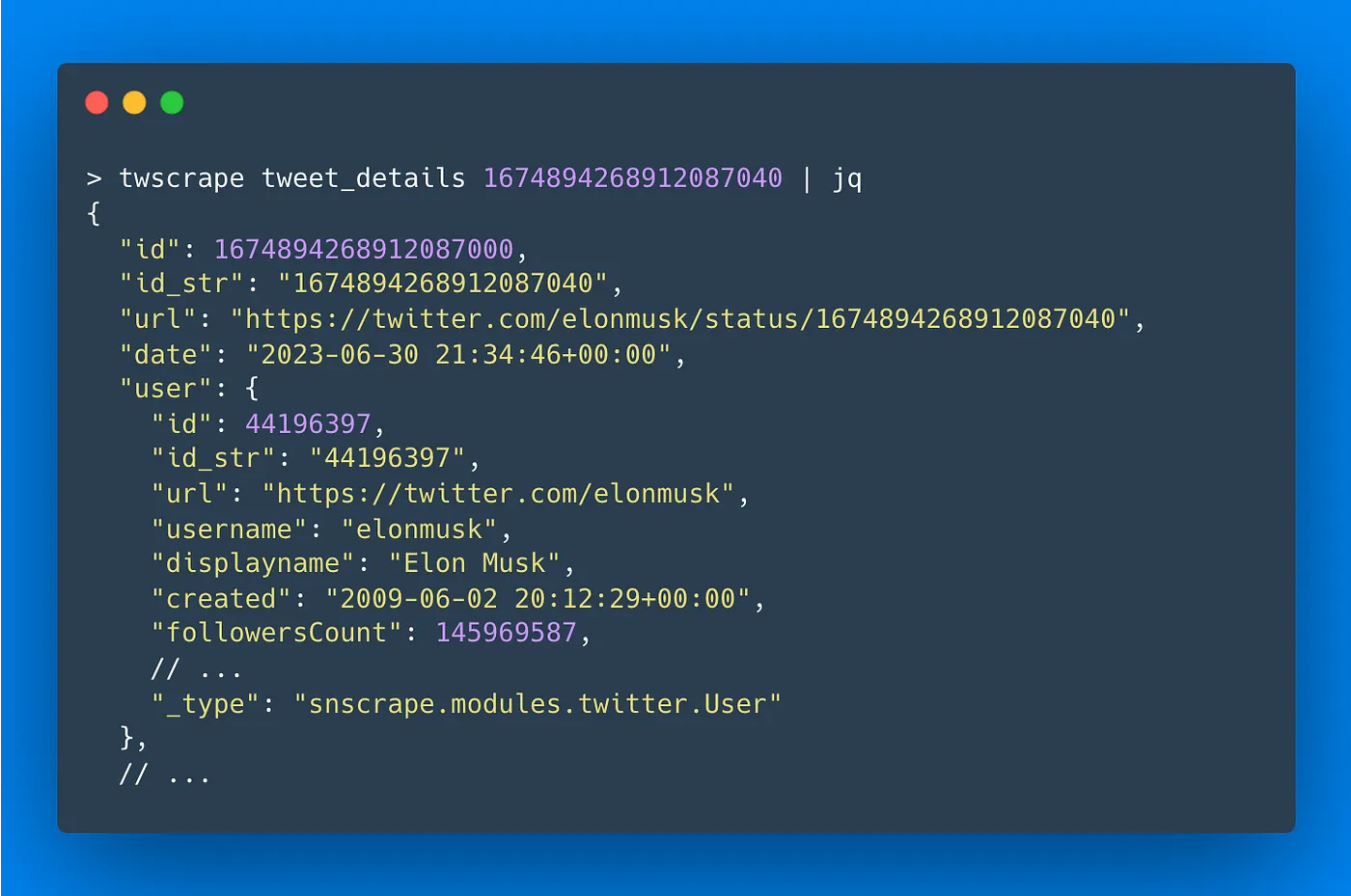
twscrape tweet_details TWEET_ID
twscrape retweeters TWEET_ID --limit=20
twscrape favoriters TWEET_ID --limit=20
twscrape user_by_id USER_ID
twscrape user_by_login USERNAME
twscrape followers USER_ID --limit=20
twscrape following USER_ID --limit=20
twscrape user_tweets USER_ID --limit=20
twscrape user_tweets_and_replies USER_ID --limit=20The default output is in the console (stdout), one document per line. So it can be redirected to the file.
twscrape search "elon mask lang:es" --limit=20 > data.txtBy default, parsed data is returned. The original tweet responses can be retrieved with --raw flag.
twscrape search "elon mask lang:es" --limit=20 --rawAfter 1 July 2023 Twitter introduced new limits and still continue to update it periodically.
The basic behaviour is as follows:
- the reqest limit is updated every 15 minutes for each endpoint individually
- e.g. each account have 50 search requests / 15 min, 50 profile requests / 15 min, etc.
API data limits:
user_tweets&user_tweets_and_replies– can return ~3200 tweets maximum
- twitter-advanced-search – guide on search filters
- twitter-api-client – Implementation of Twitter's v1, v2, and GraphQL APIs
- snscrape – is a scraper for social networking services (SNS)
- twint – Twitter Intelligence Tool