![]()
In the modern era of social media, toxicity in online comments poses a significant challenge, creating a negative atmosphere for communication. From abuse to insults, toxic behavior discourages the free exchange of thoughts and ideas among users.
This project seeks to address this issue by developing a machine learning model to identify and classify varying levels of toxicity in comments. Leveraging the power of BERT (Bidirectional Encoder Representations from Transformers), this system aims to:
- Analyze text for signs of toxicity
- Classify toxicity levels effectively
- Support moderators and users in fostering healthier and safer online communities
- By implementing this technology, the project strives to make social media a more inclusive and positive space for interaction.
Team 16.6 means that each member has an equal contribution to the project ⚖ .
The project was divided into tasks, which in turn were assigned to the following roles:
Desing director - Polina Mamchur
Data science - Olena Mishchenko
Backend - Ivan Shkvyr, Oleksandr Kovalenko
Frontend - Oleksii Yeromenko
Team Lead - Serhii Trush
Scrum Master - Oleksandr Kovalenko, Polina Mamchur
The project started with design development. First, design a prototype of user interface was developed:
Creative director create a visually appealing application, as well as to ensure the presentation of the project to stakeholders. By focusing on both UI/UX and presentation design was able to bring the team's vision to life and effectively communicate the value of the project.
A presentation on the project has been developed and can be viewed here(in PDF format):
- 🖼️ Figma: Online interface development and prototyping service with the ability to organize collaborative work
- 🐍 Python: The application was developed in the Python 3.11.8 programming language
- 🤗 Transformers: A library that provides access to BERT and other advanced machine learning models
- 🔥 PyTorch: Libraries for working with deep learning and support GPU computing
- 📖 BERT: A text analysis model used to produce contextualized word embeddings
- ☁️ Kaggle: To save time, we used cloud computing to train the models
- 🌐 Streamlit: To develop the user interface, used the Streamlit package in the frontend
- 🐳 Docker: A platform for building, deploying, and managing containerized applications
Work was performed on dataset research and data processing to train machine learning models.
To train the machine learning models, we used Toxic Comment Classification Challenge dataset. The dataset have types of toxicity:
- Toxic
- Severe Toxic
- Obscene
- Threat
- Insult
- Identity Hate
The primary datasets (train.csv, test.csv, and sample_submission.csv) are loaded into Pandas DataFrames.
After that make Exploratory Data Analysis of dataframes and obtained the following results:
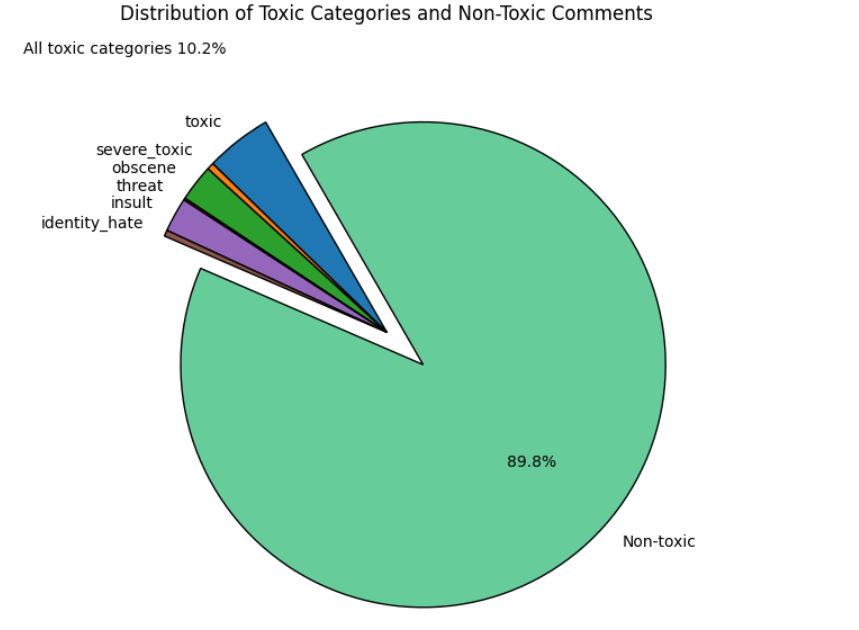
As you can seen from the data analysis, there is an imbalance of classes in the ratio of 1 to 10 (toxic/non-toxic).
Distribution of classes:
| Class | Count | Percentage |
|---|---|---|
| Toxic | 15,294 | 9.58% |
| Severe Toxic | 1,595 | 1.00% |
| Obscene | 8,449 | 5.29% |
| Threat | 478 | 0.30% |
| Insult | 7,877 | 4.94% |
| Identity Hate | 1,405 | 0.88% |
| Non-toxic | 143,346 | 89.83% |
| Total comments | 159,571 | |
| Multiclass comments vs Total comments | 18,873 | 11.8% |
As you can see, this table shows that there is multiclassing in the data, the data of one category can belong to another category.
Here is a visualization of the data from the dataset research. Dataset in bargraph representation:

Graphs show basic information about the dataset to understand the size and types of columns. Such a ratio in the data will have a very negative impact on the model's prediction accuracy.

Because the original dataset includes data imbalances, this will have a bad impact on the accuracy of machine learning models, so we applied oversampling using the Sklearn package(resample function) - copying data while maintaining the balance of classes to increase the importance in the context of models recognition of a particular class.
| Class | Original dataset | Data processing | Persentage about original |
|---|---|---|---|
| Toxic | 15,294 | 40,216 | +262% |
| Severe Toxic | 1,595 | 16,889 | +1058% |
| Obscene | 8,449 | 38,009 | +449% |
| Threat | 478 | 16,829 | +3520% |
| Insult | 7,877 | 36,080 | +458% |
| Identity Hate | 1,405 | 19,744 | +1405% |
| None toxic | 143,346 | 143,346 | 0% |
| Total | 178,444 | 269,396 | +51% |
As a result, after processing the data, the balance of toxic and non-toxic for each class was ~50/50%. Thanks to this data processing, the accuracy of pattern recognition has increased by several percent.
To solve the challenge, we have chosen 3 popular architectures, such as BERT, DistilBERT, ALBERT, each link takes you to the source code as trained by the model.
Here is a visual representation of the main parameters of the models:
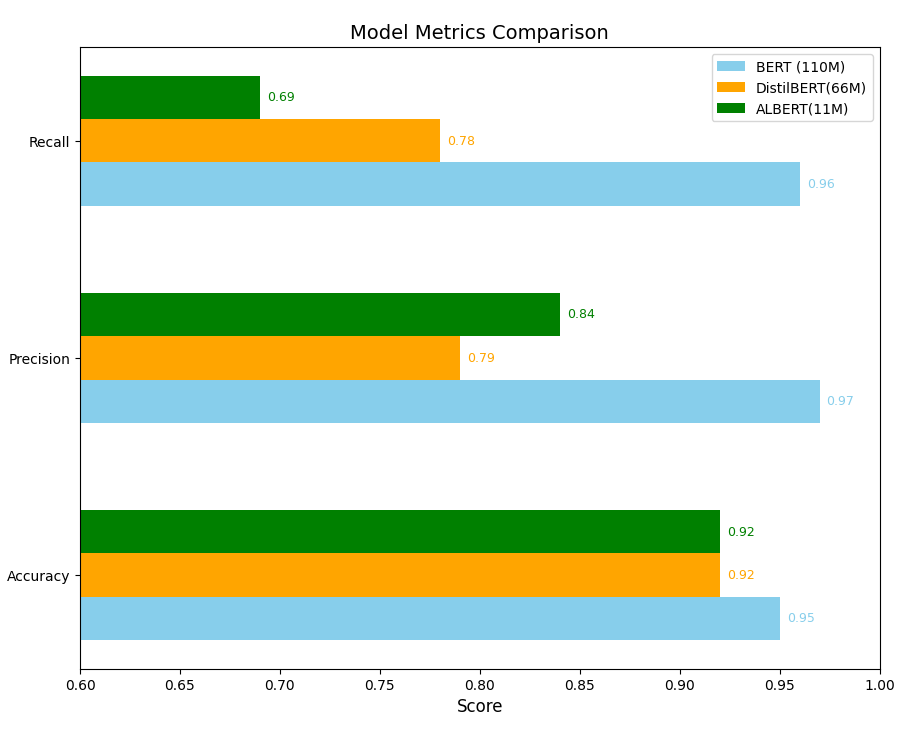
Here is a detailed description of each of the machine learning models we trained:
This project demonstrates toxic comment classification using the bert-base-uncased model from the BERT family. To automate the process of selecting hyperparameters, hepl us Optuna.
- Utilized the
bert-base-uncasedmodel with PyTorch for flexibility and ease of use. - Seamlessly integrated with Hugging Face Transformers.
- Training accelerated by ~30x using a GPU, efficiently handling BERT’s computational demands.
- Addressed dataset imbalance (90% non-toxic, 10% toxic) using oversampling with
sklearn. - Ensured rare toxic categories received equal attention by balancing class distributions.
- Improved model performance in recognizing rare toxic classes.
- Tokenization: Preprocessed data tokenized using
BertTokenizer. - Loss Function: Used
BCEWithLogitsLosswith weighted loss for rare class emphasis. - Gradient Clipping: Optimized training stability with gradient clipping (
max_norm). - Hyperparameter Tuning: Tuned batch size, learning rate, and epochs using Optuna.
- Used
itertools.productto find optimal thresholds for each class. - Improved recall and F1-score (by 1-1.5%) for better multi-label classification.
-
Validation Metrics:
- Accuracy: 0.95 ✅
- Precision: 0.97 ✅
- Recall: 0.96 ✅
-
Model Specifications:
- Vocabulary Size: 30,522
- Hidden Size: 768
- Attention Heads: 12
- Hidden Layers: 12
- Total Parameters: 110M
- Maximum Sequence Length: 512(in this case use 128 tokens)
- Pre-trained Tasks: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP).
This project demonstrates toxic comment classification using the distilbert-base-uncased model, a lightweight and efficient version of BERT.
- Selected for its flexibility, ease of use, and strong community support.
- Seamlessly integrated with Hugging Face Transformers.
- Addressed dataset imbalance (90% non-toxic, 10% toxic) using
sklearn.utils.resample. - Applied stratified splitting for training and test datasets.
- Oversampled rare toxic classes, improving model recognition of all categories.
- Tokenization: Preprocessed data with
DistilBertTokenizer. - Loss Function: Binary Cross-Entropy with Logits (
BCEWithLogitsLoss). - Hyperparameter Tuning: Optimized batch size (
16), learning rate (2e-5), and epochs (3) with Optuna.
- Utilized GPU for training, achieving a ~30x speedup over CPU.
- Used
itertools.productto determine optimal thresholds for each class. - Improved recall and F1-score for multi-label classification.
-
Validation Metrics:
- Accuracy: 0.92 ✅
- Precision: 0.79 ✅
- Recall: 0.78 ✅
-
Model Specifications:
- Vocabulary Size: 30522
- Hidden Size: 768
- Attention Heads: 12
- Hidden Layers: 6
- Total Parameters: 66M
- Maximum Sequence Length: 512(in this case use 128 tokens)
- Pre-trained Tasks: Masked Language Modeling (MLM).
This project demonstrates toxic comment classification using the albert-base-v2 model, a lightweight and efficient version of BERT designed to reduce parameters while maintaining high performance.
- Selected for its flexibility, ease of use, and strong community support.
- Seamlessly integrated with Hugging Face Transformers.
- Addressed dataset imbalance (90% non-toxic, 10% toxic) using
sklearn.utils.resample. - Applied stratified splitting for training and test datasets.
- Oversampled rare toxic classes to improve model recognition of all categories.
- Tokenization: Preprocessed data with
AlbertTokenizer. - Loss Function: Binary Cross-Entropy with Logits (
BCEWithLogitsLoss). - Hyperparameter Tuning: Optimized batch size (
8), learning rate (2e-5), and epochs (3) using Optuna.
- Utilized GPU for training, achieving a ~30x speedup over CPU.
- Used
itertools.productto determine optimal thresholds for each class. - Enhanced recall and F1-score for multi-label classification.
-
Validation Metrics:
- Accuracy: 0.92 ✅
- Precision: 0.84 ✅
- Recall: 0.69 ✅
-
Model Specifications:
- Vocabulary Size: 30000
- Hidden Size: 768
- Attention Heads: 12
- Hidden Layers: 12
- Intermediate Size: 4096
- Total Parameters: 11M
- Maximum Sequence Length: 512(in this case use 128 tokens)
- Pre-trained Tasks: Masked Language Modeling (MLM).
We used to Cloud computing on Kaggle for are speed up model training.
There are two ways to install the application on your computer:
Download Docker -> Log in to your profile in the application -> Open the Docker terminal(bottom of the program) -> Enter command:
docker pull techn0man1ac/toxiccommentclassificationsystem:latest
After that, all the necessary files will be downloaded from DockerHub -> Go to the Images tab -> Launch the image by clicking Run -> Click Optional settings -> Set the host port 8501
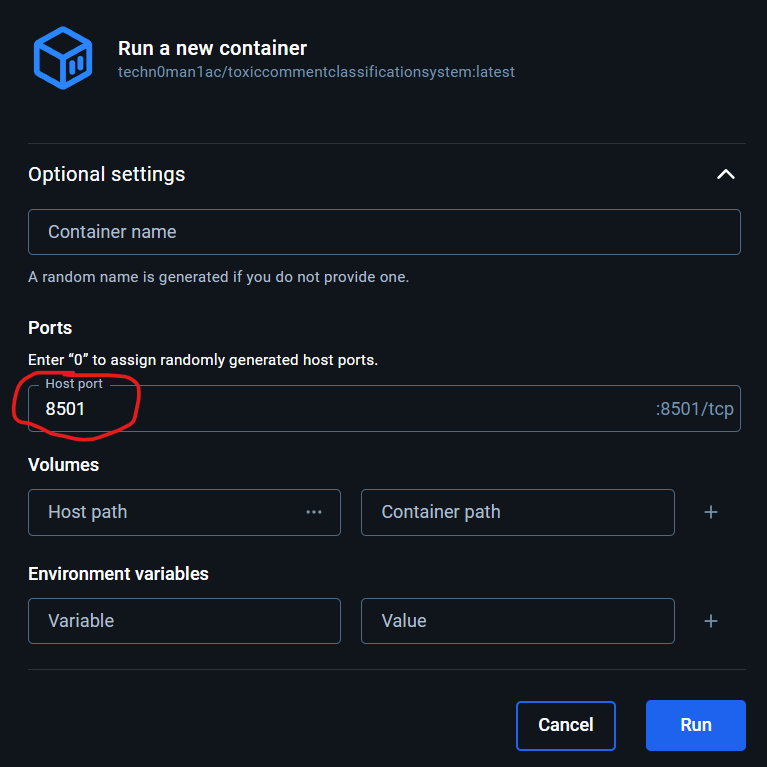
Open http://localhost:8501 in your browser.
This way need from you, to have some skills with command line, GitHub and Docker.
- Cloning a repository:
git clone https://github.com/techn0man1ac/ToxicCommentClassification.git
- Download the model files from this link, after downloading the
albert,bertanddistilbertdirectories, put them in thefrontend\saved_modelsdirectory, like that:
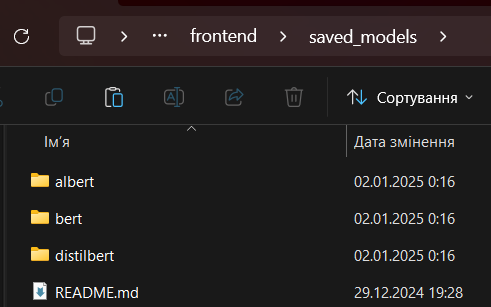
- Open a command line/terminal and navigate to the
ToxicCommentClassificationdirectory, and pack the container with the command:
docker-compose up
- After which the application will immediately start and a browser window will open with the address http://localhost:8501
To turn off the application, run the command:
docker-compose down
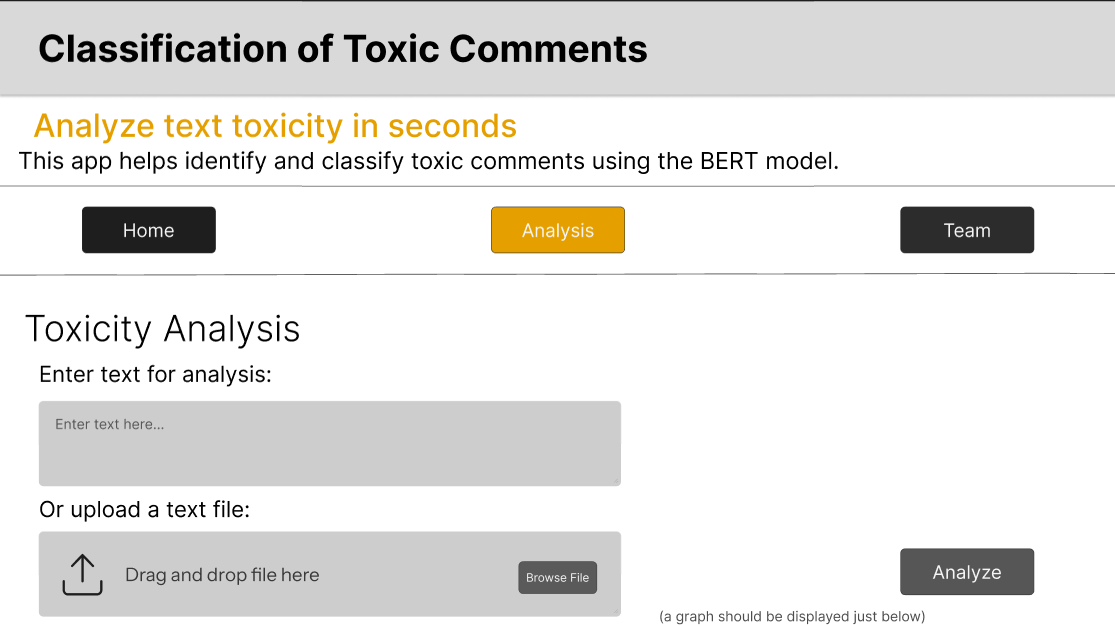
After launching the application, you will see the project's home tab with a description of the application and the technologies used in it. The program looks like this when running:
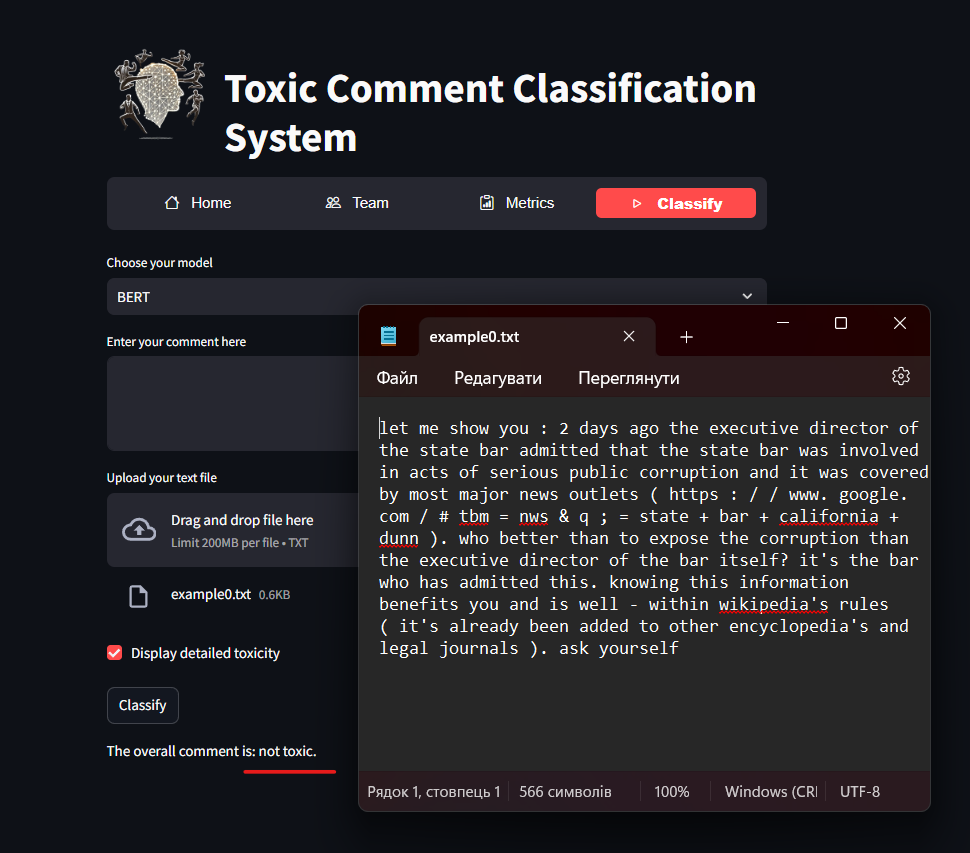
The application interface is intuitive and user-friendly.
The structure of the tabs is as follows:
Home- Here you can find a description of the app, the technologies used for its operation, the mission and vision of the project, and acknowledgmentsTeam- This tab contains those without whom the app would not exist, its creatorsMetrics- In this tab, you can choose one of 3 models, after selecting it, the technical characteristics of each of the machine learning models are loadedClassification- A tab where you can test the work of models.
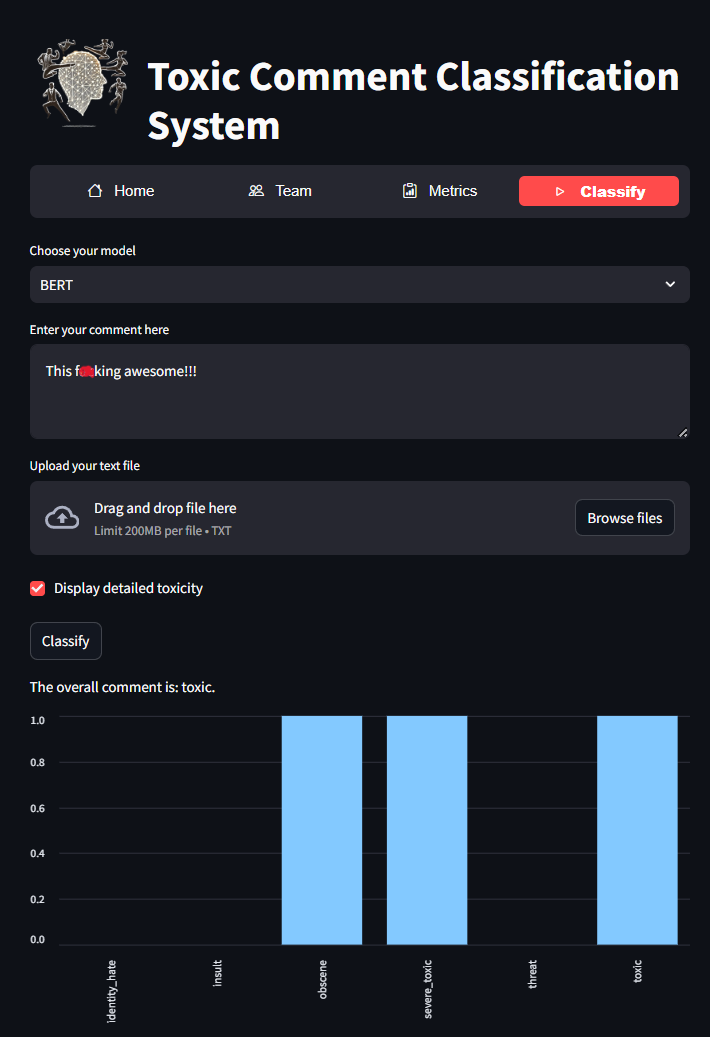
The main elements of the interface:
Choose your model- A drop-down list where you can select one of 3 pre-trained machine learning modelsEnter your comment here- In this field you can manually write a text to test it for toxicity and further classify it in a positive caseUpload your text file- By clicking here, a dialog box will appear with the choice of a file intxt format(after uploading the file, the text in the text field is ignored)Display detailed toxicity- A checkbox that displays a detailed classification by class if the model considers the text to be toxic
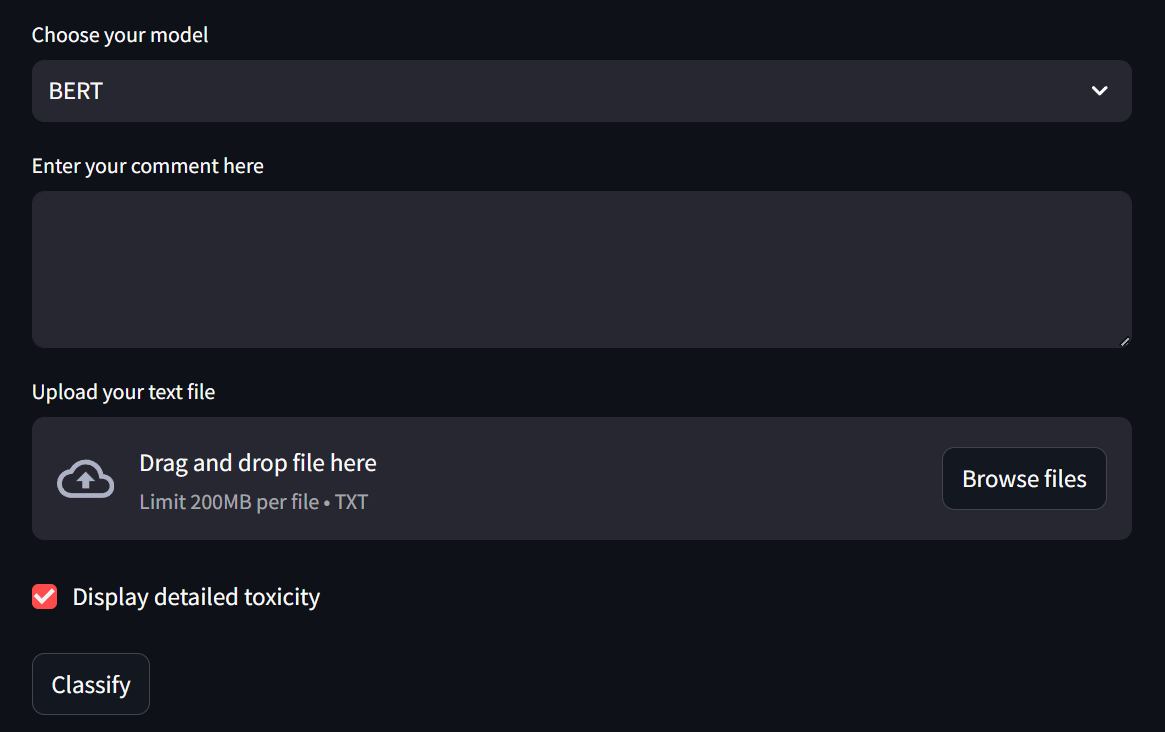
The application interface is intuitive and user-friendly. The application is also able to classify text files in the txt format.
The app written with the help of streamlit provides a user-friendly interface to observe and try out functionality of the included BERT-based models for comment toxicity classification.
The mission of our project is to create a reliable and accurate machine learning model that can effectively classify different levels of toxicity in online comments. We plan to use advanced technologies to analyze text and create a system that will help moderators and users create healthier and safer social media environments.
Our vision is to make online communication safe and comfortable for everyone. We want to build a system that not only can detect toxic comments, but also helps to understand the context and tries to reduce the number of such messages. We want to create a tool that will be used not only by moderators, but also by every user to provide a safe environment for the exchange of thoughts and ideas.
This project is a group work published under the MIT license , and all project contributors are listed in the license text.
This project was developed by a team of professionals as a graduation thesis of the GoIT Python Data Science and Machine Learning course.
Thank you for exploring our project! Together, we can make online spaces healthier and more respectful.