Repository for paper titled "Stacked DeBERT: All Attention in Incomplete Data for Text Classification".
Overview • Requirements • How to Use • How to Cite
-
Proposed model: Stacked Denoising BERT
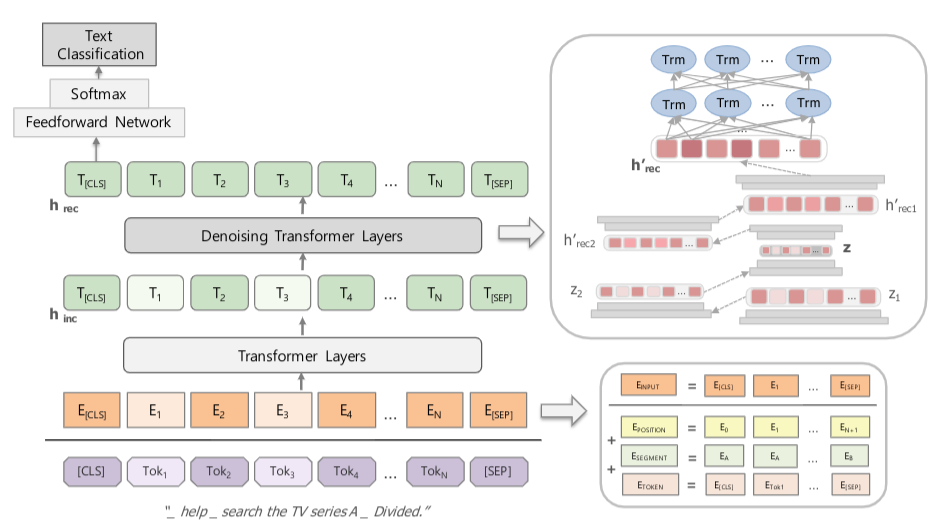
-
Task: Text classification from noisy data
- Twitter Sentiment Classification
- Incomplete Intent Classification: text with STT error
-
Baseline models
- BERT
- NLU Platforms: Rasa (spacy and tf), Dialogflow, and SAP Conversational AI
- Semantic Hashing with Classifier

Python 3.6 (3.7.3 tested), PyTorch 1.0.1.post2, CUDA 9.0 or 10.1
pip install -r requirements.txt
conda install pytorch torchvision cudatoolkit=9.0 -c pytorch
- Chatbot NLU Evaluation Benchmark dataset with missing/incorrect data (STT errors) and Twitter Sentiment dataset (Check Dataset README)
- Training done on:
- Twitter dataset: complete data, incomplete data, complete+incomplete data
- Chatbot dataset: complete data, 2 TTS-STT data (gtts-witai, macsay-witai)
- Twitter Sentiment Corpus
CUDA_VISIBLE_DEVICES=0,1 ./scripts/twitter_sentiment/run_bert_classifier_inc_with_corr.sh
Script for Inc+Corr dataset. Scripts corresponding to Inc and Corr are also available in the same folder.
- Chatbot Incomplete Intent Corpus: texts with STT Error
CUDA_VISIBLE_DEVICES=0,1 ./scripts/stterror_intent/run_bert_classifier_stterror.sh
Script for noisy data (stterror). Script for clean, non-noisy data, is also available (complete).
- Training on Twitter Corpus
CUDA_VISIBLE_DEVICES=0,1 ./scripts/twitter_sentiment/run_stacked_debert_dae_classifier_twitter_inc_with_corr.sh
Make sure the OUTPUT directory is the same as the fine-tuned BERT or copy the BERT model to your new output dir.
- Training on NLU Evaluation Corpora for TTS=gtts/macsay and STT=witai and autoencoder epochs 100-1000.
CUDA_VISIBLE_DEVICES=0,1 ./scripts/stterror_intent/run_stacked_debert_dae_classifier_stterror.sh
In case you wish to use this code, please use the following citation:
@misc{cunha2020stackeddebert,
title={Stacked DeBERT: All Attention in Incomplete Data for Text Classification},
author={Gwenaelle Cunha Sergio and Minho Lee},
year={2020},
eprint={2001.00137},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Email for further requests or questions:
gwena.cs@gmail.com
The authors would like to thank Snips.co and Kaggle for their public datasets (Snips NLU Benchmark and Sentiment140 Twitter Dataset), and HuggingFace's BERT PyTorch code.