- Introduction
- What's included
- File Descriptions
- Installation
- Instructions
- Usage
- Licensing, Authors, and Acknowledgements
The project aims at providing a web application called "Disasters" for end-users to enter text message during disaster, and it is able to classify the text message into 36 categories.
(project folder)/
├── data/
│ ├── disaster_categories.csv
│ ├── disaster_messages.csv
│ ├── process_data.py
│ ├── output.png
│ ├── (DisasterResponse.db)
├── models/
│ ├── train_classifier.py
│ ├── output.png
│ ├── (classifier.pkl)
└── app/
├── run.py
├── output.png
├── templates/
├── go.html
├── master.html
- data/disaster_categories.csv
- Categories dataset from Figure Eight.
- data/disaster_messages.csv
- Messages dataset from Figure Eight.
- data/process_data.py
- Python script file for ETL pipeline.
- data/output.png
- Screenshot of process_data.py output.
- data/DisasterResponse.db
- The output database file combining Categories and Messages datasets. This file is not initially included in the project, but generated after executing process_data.py.
- models/train_classifier.py
- Python script file for ML pipeline.
- models/output.png
- Screenshot of train_classifier.py output.
- models/classifier.pkl
- The saved model generated by train_classifier.py.
- app/run.py
- The web application "Disasters" for end-user to enter custom message and get classification result.
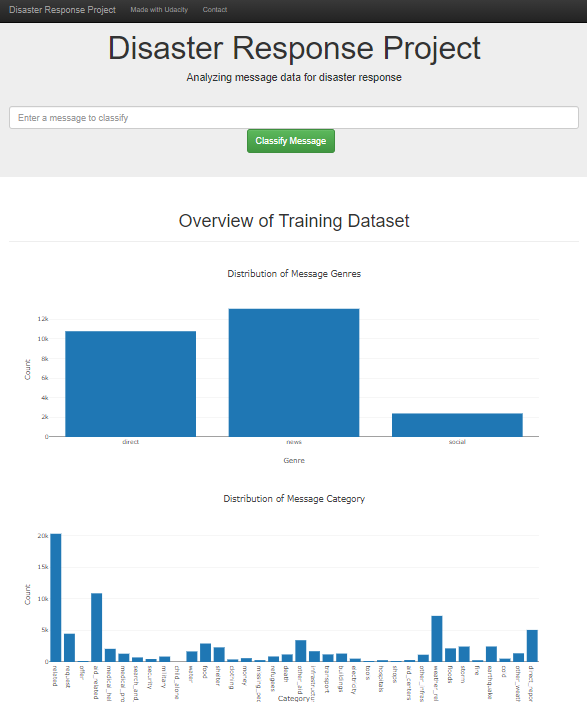
- app/output.png
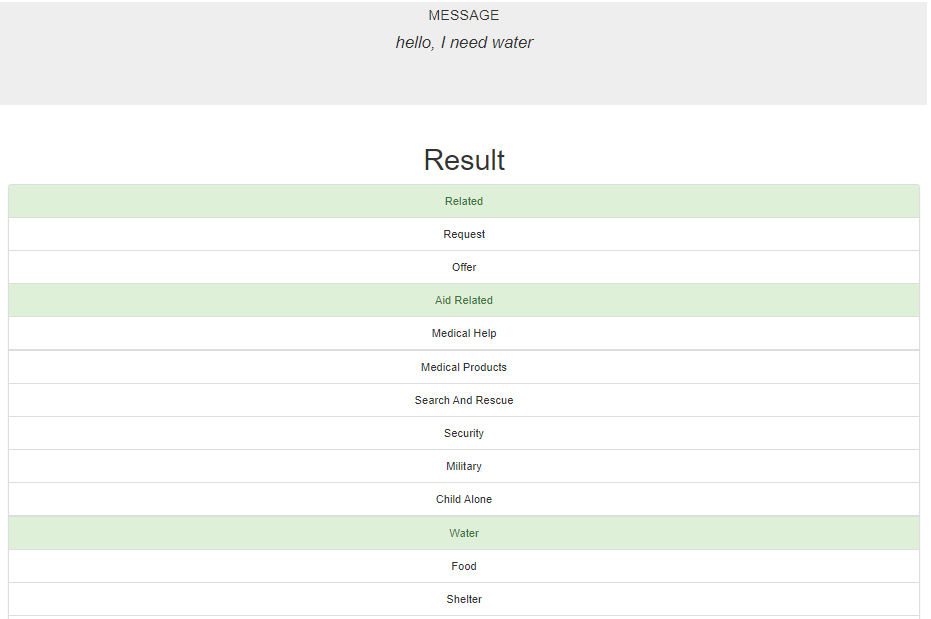
- Screenshot of web application "Disasters".
- app/templates/go.html
- HTML template file used by the web application "Disasters".
- app/templates/master.html
- HTML template file used by the web application "Disasters".
The code should run with no issues using Python versions 3.6.3
Python libraries used in the project:
- pandas
- numpy
- sqlalchemy
- re
- nltk
- nltk.tokenize
- nltk.stem
- sklearn.model_selection
- sklearn.pipeline
- sklearn.base
- sklearn.feature_extraction.text
- sklearn.ensemble
- sklearn.multioutput
- sklearn.metrics
- json
- plotly
- plotly.graph_objs
- flask
- joblib
- sys
-
Run the following commands in the project's root directory to set up your database and model.
-
To run ETL pipeline that cleans data and stores in database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db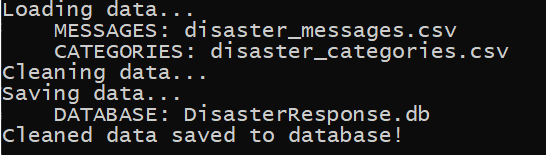
-
To run ML pipeline that trains classifier and saves
python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl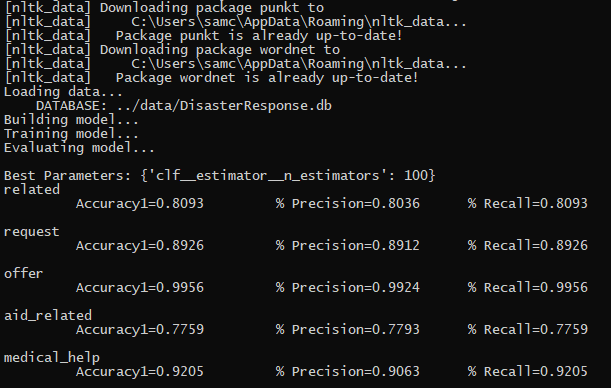
-
-
Run the following command in the app's directory to run your web app.
python run.py -
Go to http://localhost:3001/



-
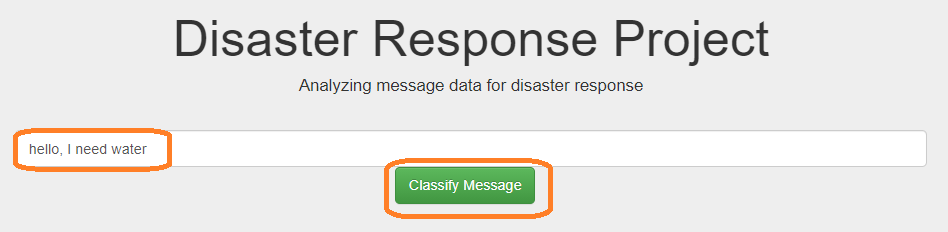
Enter the custom message in the textbox. Then hit "Classify Message".
-
It will show all categories that the custom message belongs to with green highlighted.


Code released under the MIT License. Must give credit to Figure Eight for the data.