This is a research repo for fast AI detection using compression. While there are a number of existing LLM detection systems, they all use a large model trained on either an LLM or its training data to calculate the probability of each word given the preceding, then calculate a score where the more high-probability tokens are more likely to be AI-originated. Techniques and tools in this repo are looking for faster approximation to be embeddable and more scalable.
Below are some other places to learn about ZipPy:
ZipPy uses either the LZMA, Brotli, or zlib compression ratios as a way to indirectly measure the perplexity of a text.
Compression ratios have been used in the past to detect anomalies in network data
for intrusion detection, so if perplexity is roughly a measure of anomalous tokens, it may be possible to use compression to detect low-perplexity text.
LZMA and zlib create a dictionary of seen tokens and then use though in place of future tokens. The dictionary size, token length, etc.
are all dynamic (though influenced by the 'preset' of 0-9--with 0 being the fastest but worse compression than 9). The basic idea
is to 'seed' a compression stream with a corpus of AI-generated text (ai-generated.txt) and then measure the compression ratio of
just the seed data with that of the sample appended. Samples that follow more closely in word choice, structure, etc. will achieve a higher
compression ratio due to the prevalence of similar tokens in the dictionary, novel words, structures, etc. will appear anomalous to the seeded
dictionary, resulting in a worse compression ratio.
Some of the leading LLM detection tools are:
OpenAI's model detector (v2), Content at Scale, GPTZero, CrossPlag's AI detector, and Roberta.
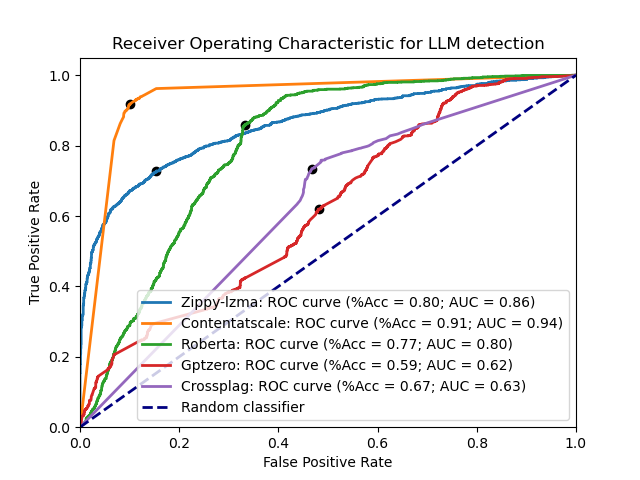
Here are each of them compared with both the LZMA and zlib detector across the test datasets:
You can install zippy one of two ways:
Via pip:
pip3 install thinkst-zippyOr from source:
python3 setup.py build && python3 setup.py sdist && pip3 install dist/*.tar.gzNow you can import zippy in other scripts.
pkgx install zippy # or run it directly `pkgx zippy -h`ZipPy will read files passed as command-line arguments or will read from stdin to allow for piping of text to it.
Once you've installed zippy it will add a new script (zippy) that you can use directly:
$ zippy -h
usage: zippy [-h] [-p P] [-e {zlib,lzma,brotli,ensemble}] [-s | sample_files ...]
positional arguments:
sample_files Text file(s) containing the sample to classify
options:
-h, --help show this help message and exit
-p P Preset to use with compressor, higher values are slower but provide better compression
-e {zlib,lzma,brotli,ensemble}
Which compression engine to use: lzma, zlib, brotli, or an ensemble of all engines
-s Read from stdin until EOF is reached instead of from a file
$ zippy samples/human-generated/about_me.txt
samples/human-generated/about_me.txt
('Human', 0.06013429262166636)If you want to use the ZipPy technology in your browser, check out the Chrome extension or the Firefox extension that runs ZipPy in-browser to flag potentially AI-generated content.
At its core, the output from ZipPy is purely a statistical comparison of the similarity between the LLM-generate corpus (or corpi) and the provided sample to test. Samples that are closer (i.e., more tokens match the known-LLM corpus) will score with higher confidence as AI-generated; samples that are less compressible to an LLM-trained compression dictionary are flagged as human-generated. There are a few caveats to the output that are worth noting:
-
The comparison is based on the similarity of the text, a different type of sample, e.g., in a different language, or with many fictional names, will be less similar to the English-languge corpus. Either a new LLM-generated corpus is needed, or a different (larger) toolchain that can handle multiple language types is needed. Using ZipPy as-built willl provide poor responses to non-English human language samples, computer language samples, and English samples that are not clear prose (or poetry).
-
The confidence score is a raw delta between the compression ratios for the prelude file (LLM-generated corpus), and the compression ratio with the sample included. Higher values indicate more similarity for AI-classified inputs, and more dissimilarity for those classified as human, but the scores are not a percentage or otherwise a point on a discrete range. A score of 0 means there is no indication either way, it is possible in testing to ignore results that are "too close", in the browser extensions these values are adjusted slightly before being used to calculate the transparency to err on the side of not hiding text.