We are given the following scenario:
A startup called Sparkify wants to analyze the data they've been collecting on songs and user activity on their new music streaming app. Currently, they don't have an easy way to query their data, which resides in a directory of JSON logs on user activity on the app, as well as a directory with JSON metadata on the songs in their app ('data' folder in this repository).
They'd like us to create a Postgres database with tables designed to optimize queries on song play analysis, constructing an ETL pipeline for the purposes of this analysis.
Note: This project was done in a docker container kindly provided by kenhanscombe.
- import os
- import glob
- import psycopg2
- import pandas
- import sql_queries
- test.ipynb displays the first few rows of each table to let us check the database.
- create_tables.py drops and creates the tables. We run this file to reset our tables before each time we run our ETL scripts.
- etl.ipynb reads and processes a single file from song_data and log_data and loads the data into our tables. This notebook contains detailed instructions on the ETL process for each of the tables.
- etl.py reads and processes files from song_data and log_data and loads them into our tables.
- sql_queries.py contains all of our sql queries, and is imported into the last three files above.
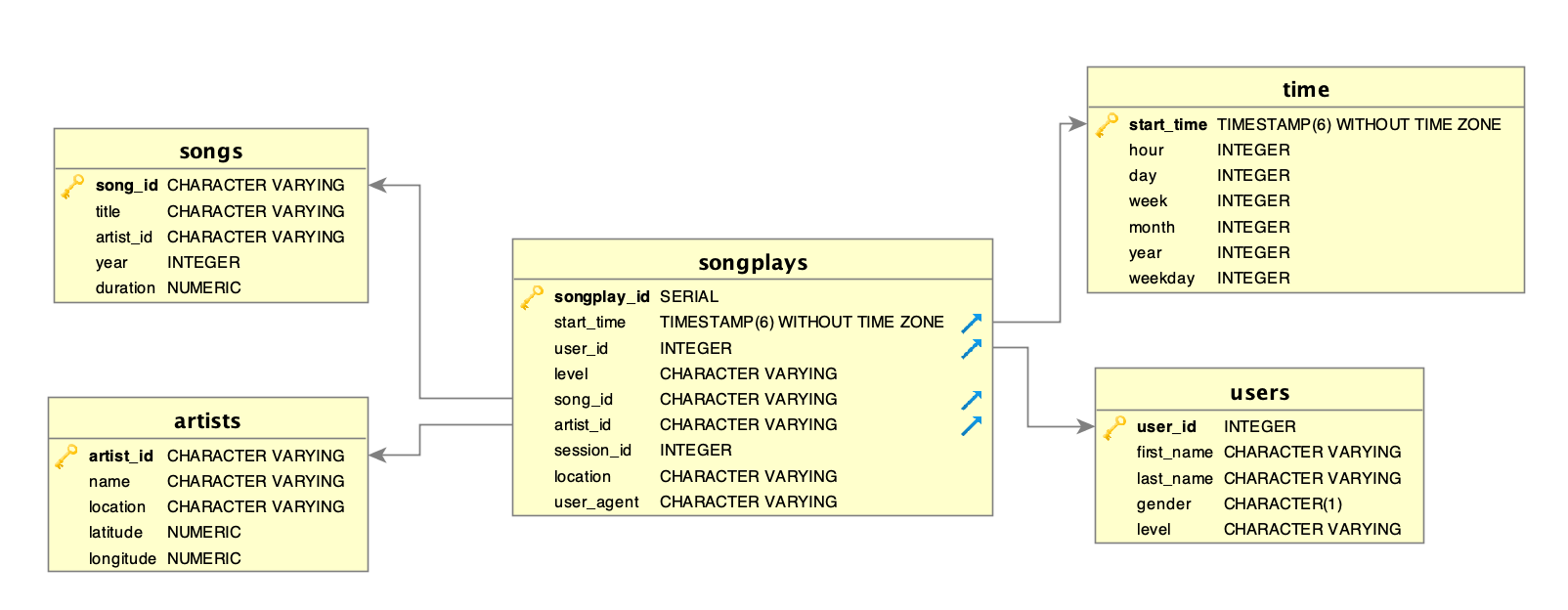
Fact Table
- songplays - records in log data associated with song plays i.e. records with page NextSong
Dimension Tables
- users - users in the app
- songs - songs in music database
- artists - artists in music database
- time - timestamps of records in songplays broken down into specific units
- python create_tables.py - uses functions create_database, drop_tables, and create_tables to create the database sparkifydb and the required tables
- python etl.py - defines the main extract, transform, and load processes