

dstack is an open-source toolkit and orchestration engine for running GPU workloads.
It's designed for development, training, and deployment of gen AI models on any cloud.
Supported providers: AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, and DataCrunch.
- [2024/01] dstack 0.14.0: OpenAI-compatible endpoints preview (Release)
- [2023/12] dstack 0.13.0: Disk size, CUDA 12.1, Mixtral, and more (Release)
- [2023/11] dstack 0.12.3: Vast.ai integration (Release)
- [2023/10] dstack 0.12.2: TensorDock integration (Release)
- [2023/09] RAG with Llama Index and Weaviate (Example)
- [2023/08] Fine-tuning with QLoRA (Example)
Before using dstack through CLI or API, set up a dstack server.
The easiest way to install the server, is via pip:
pip install "dstack[all]" -UIf you have default AWS, GCP, or Azure credentials on your machine, the dstack server will pick them up automatically.
Otherwise, you need to manually specify the cloud credentials in ~/.dstack/server/config.yml.
For further details on setting up the server, refer to installation.
To start the server, use the dstack server command:
$ dstack server
Applying configuration from ~/.dstack/server/config.yml...
The server is running at http://127.0.0.1:3000/
The admin token is "bbae0f28-d3dd-4820-bf61-8f4bb40815da"Note It's also possible to run the server via Docker.
Once the server is up, you can use either dstack's CLI or API to run workloads.
Below is a live demo of how it works with the CLI.
Dev environments allow you to quickly provision a machine with a pre-configured environment, resources, IDE, code, etc.
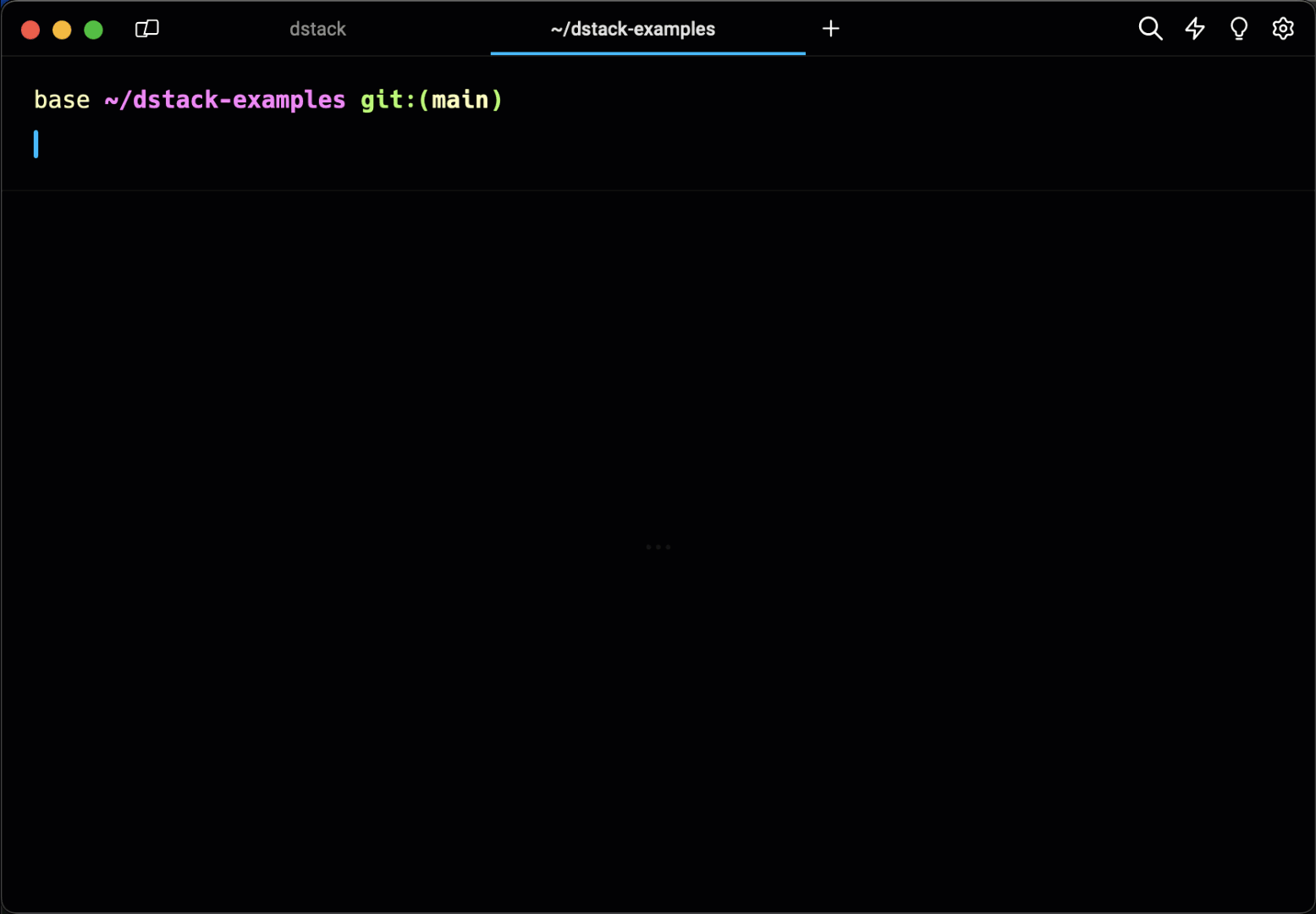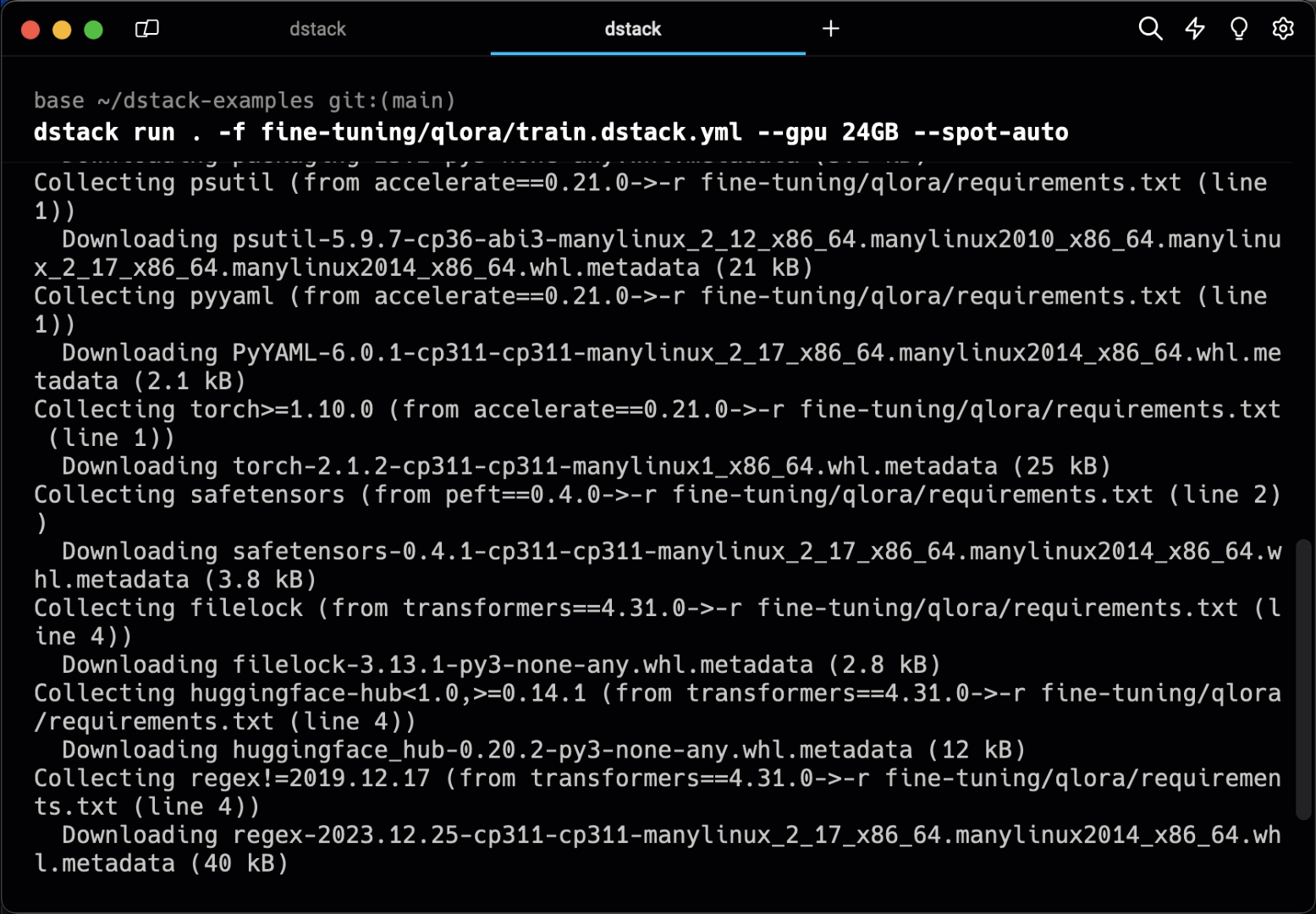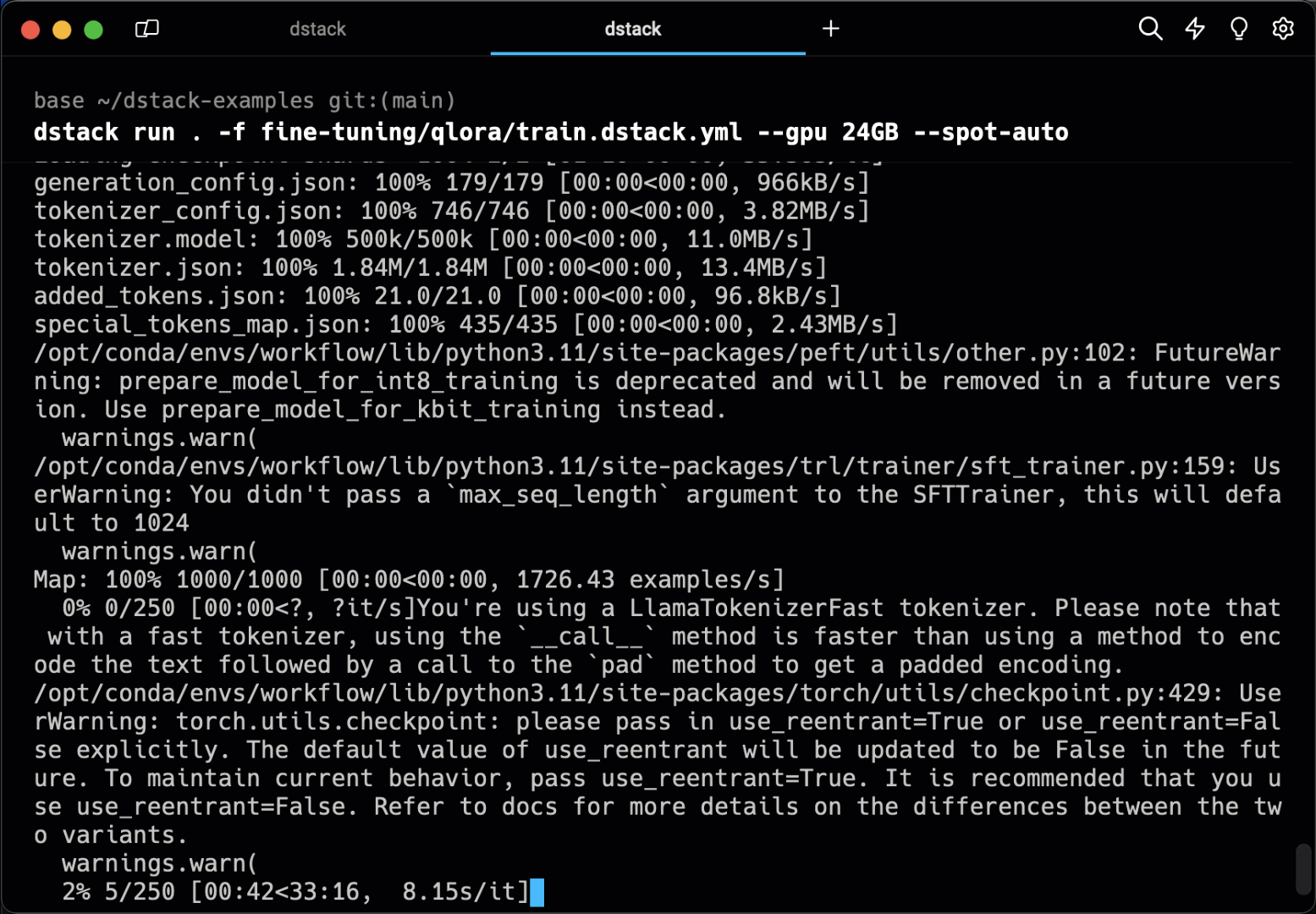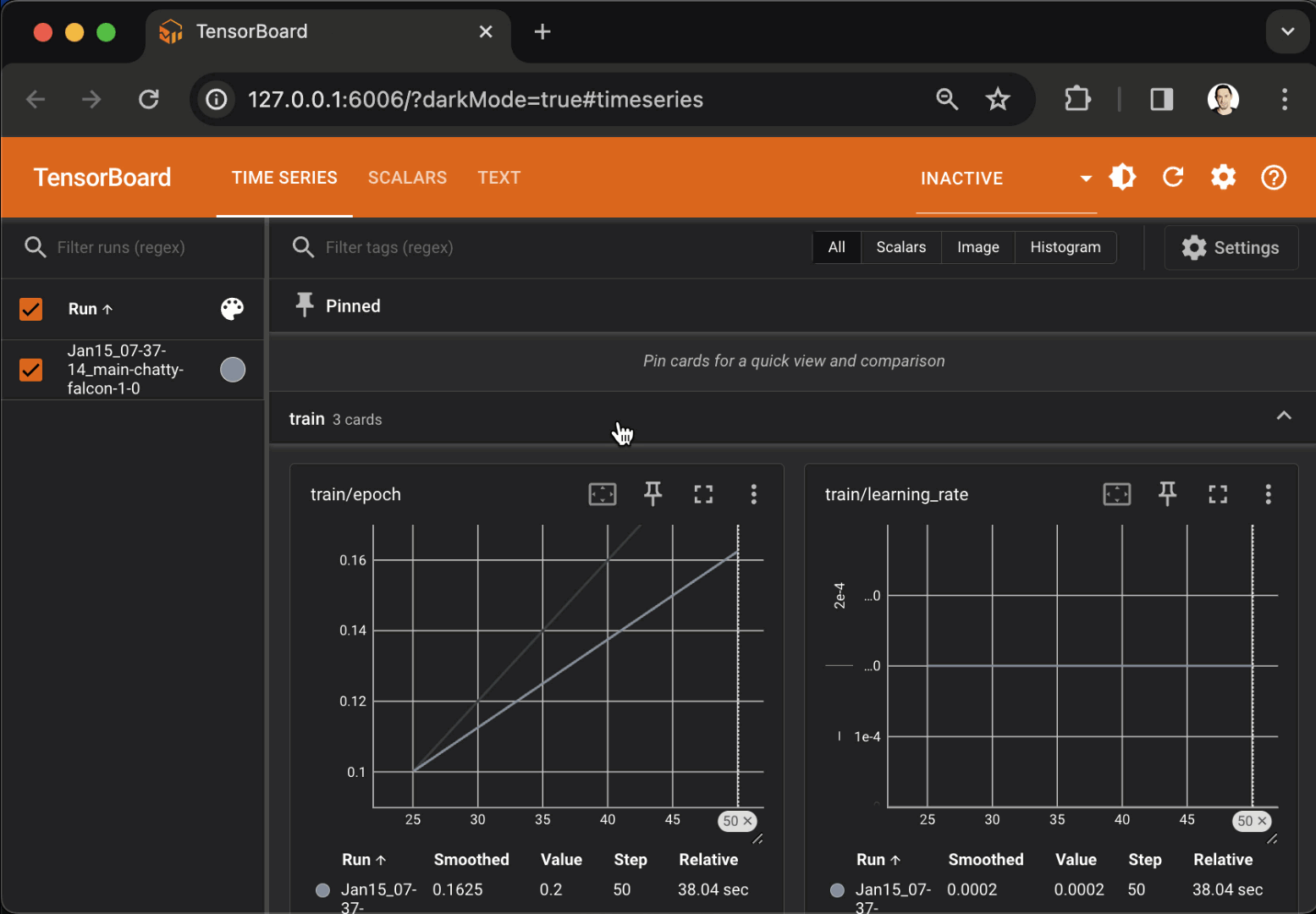
Tasks make it very easy to run any scripts, be it for training, data processing, or web apps. They allow you to pre-configure the environment, resources, code, etc.
Services make it easy to deploy models and apps cost-effectively as public endpoints, allowing you to use any frameworks.
For additional information and examples, see the following links: