
JavaScript time series spike detection for Node.js; like the Octave findpeaks function.
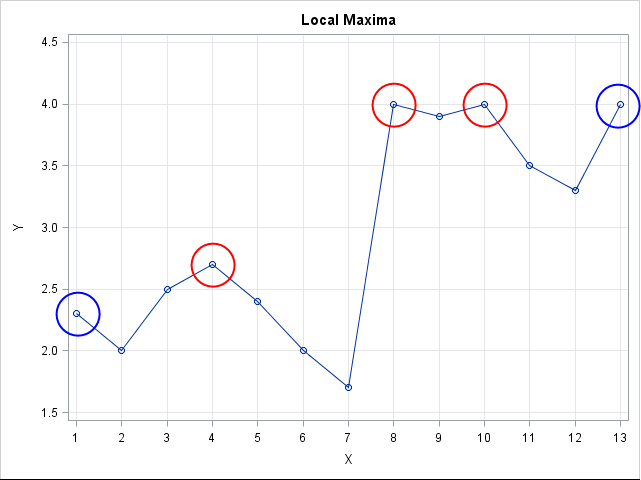
Time series are often displayed as bar, line or area charts. A peak or spike in a time series is a the highest value before the trend start to decrease.
In reality you do not need all the spikes. You only need the highest spike amongst them. Slayer helps to identify these local peaks easily.
| npm | bower | old school |
|---|---|---|
npm install --save slayer |
- | download zip file |
Slayer exposes a fluent JavaScript API and requires as little configuration as possible. The following examples illustrates common use cases.
var slayer = require('slayer');
var arrayData = [0, 0, 0, 12, 0, …];
slayer().fromArray(arrayData).then(spikes => {
console.log(spikes); // [ { x: 4, y: 12 }, { x: 12, y: 25 } ]
});var slayer = require('slayer');
var arrayData = […, { date: '…', value: 12 }, …];
slayer()
.y(item => item.value)
.fromArray(arrayData)
.then(spikes => {
console.log(spikes); // [ { x: 4, y: 12 }, { x: 12, y: 25 } ]
});someStream
.pipe(slayer().createReadStream())
.on('error', err => console.error(err))
.on('data', spike => {
console.log(spike); // { x: 4, y: 12 }
});Access the Slayer API by requiring the CommonJS module:
var slayer = require('slayer');A spike object is an object composed of two keys:
x: the index value within the time series array;y: the spike value within the time series array.
The slayer() factory returns a new chainable instance of Slayer.
The optional config object enables you to adjust its behaviour according to your needs:
minPeakDistance(Integer): size of the values overlooked window. Default is30;minPeakHeight(Number): discard any value below that threshold. Default is0.
Returns a slayer chainable object.
Data accessor applied to each series item and used to determine spike values.
It will return this value as the y value of a spike object.
slayer()
.y(item => item.value) // considering item looks like `{ value: 12 }`
.fromArray(arrayData)
.then(spikes => {
console.log(spikes); // { x: 4, y: 12 }
});Returns a mutated slayer chainable object.
Index accessor applied to each series item.
It will return this value as the x value of a spike object.
slayer()
.x((item, i) => item.date) // considering item looks like `{ date: '2014-04-12T17:31:40.000Z', value: 12 }`
.fromArray(arrayData)
.then(spikes => {
console.log(spikes); // { x: '2014-04-12T17:31:40.000Z', y: 12 }
});Returns a mutated slayer chainable object.
Transforms the spike object before returning it as part of the found spike collections.
It is useful if you want to add extra data to the returned spike object.
slayer()
.transform((xyItem, originalItem, i) => {
xyItem.id = originalItem.id;
return xyItem;
})
.fromArray(arrayData)
.then(spikes => {
console.log(spikes); // { x: 4, y: 12, id: '21232f297a57a5a743894a0e4a801fc3' }
});Returns a mutated slayer chainable object.
Processes a finite array of data and returns them at once.
slayer()
.fromArray(arrayData)
.then(spikes => {
console.log(spikes); // { x: 4, y: 12, id: '21232f297a57a5a743894a0e4a801fc3' }
});Returns an ES2015 Promise object.
Processes a stream of data and emits a data event each time a spike is found.
Although you might notice a slight delay as spike deduplication happens under the hood.
You can optionally pass an options object to tweak and adjust the precision of the analysis:
bufferingFactor(Number): buffer ratio of the sliding window, againstminPeakDistance. Default is4;lookAheadFactor(Number): additional buffer ratio to look ahead, against the sliding window size. Default is0.33.
With this setup, slayer will buffer 4 times the amount of minPeakDistance with an additional 0.33 times before performing an analysis before moving from 4 times the amount of minPeakDistance.
The following example demonstrates the streaming analysis of a file containing single values on each row of the document:
var split = require('split');
fs.createReadStream('./big-big-data.txt')
.pipe(split())
.pipe(slayer().createReadStream())
.on('data', spike => console.log(spike));Returns a ReadableStream.
If you wish to contribute the project with code but you fear to break something, no worries as TravisCI takes care of this for each Pull Request.
Nobody will blame your code. And feel free to ask before making a pull request. We will try to provide you guidance for code design etc.
If you want to run the tests locally, simply run:
npm testIf you want to run them continuously, then run:
npm test -- --watchCopyright 2016 British Broadcasting Corporation
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.