This package has both training and classifying capabilities to handle text content from:
- MicroBlog
- Blogs_News
- Reviews
- Comments
- General Text
The "Reviews" are further categorized as (Thus supporting Multiple Domains):
- products
- apparel
- automotive
- baby
- beauty
- food
- grocery
- health
- jewelry
- housewares
- magazines
- musical_instruments
- office_products
- outdoor_living
- sports
- tools
- toys
- electronics_tech
- general
- camera
- cell_phones
- computer
- software -movie
- general
- dvd
- video
- services
- automotive
- beauty
- healthcare
- other
- books
- food
- hotels_bars
- music_albums
- places
- restaurants
- travel_tour
Sentiment Analysis has always been an excellent source of information that expresses user opinion towards any particular product or service, topic, etc. It is also capable of providing numerous insights that can be used to formulate marketing strategies, improve campaign success, improve customer service etc of any company. In short, if perfect sentiment analysis is done it will improve any company's bottom line for sure.
Sentiment Analysis has always been a great research problem to solve, most of the solutions that companies use today are more rule based and are not capable of adapting to the dynamic world, we data scientists at Serendio are proposing a Machine Learning approach to this problem and we have developed a model that is capable of learning sentiments from nearly 36 Domains and also dynamically adapts to the new trends, unlike the rule based approaches. We also support 5 different types of text sources that include blogs, microblogs, news articles, reviews, comments and general text.
-
Social Text Processor (SocialFilters): Of all the text data available to us, 60% to 70% are completely unstructured and are not suitable for most of the NLP tools available today for processing them. We at serendio are working to process all of this unstructured data into text suitable for Text Analytics applications with Processing Filters for:
- Acronyms [LOL, OMG, etc.]
- Emoticons [ :) , :( , etc.]
- Spell Check
- Contractions
- Hashtags
- Sentiment Scorer for Emoticons, Acronyms, Hashtags. We have discovered that by processing the hashtags, emoticons, acronyms, etc the sentiment engine becomes more wiser in predicting the sentiment score.
-
Multi Domain Support: The main reason why Sentiment Analysis has always been a challenging problem is because of the wide range of domains available and each domain has its own set of sentiment rich words or phrases that conflict with those in the other domains. To overcome this we have built Domain specific models that are capable of capturing the sentiment semantics of each domain and thus able to handle text from any domain with great precision. Especially for reviews we support a set of:
- 11 Top Domains Products, Electronics and Technology, Movies, Services, Books, Food, Hotels and Bars, Music, Places, Restaurants, Travel and Tour.
- 36 Finer Sub Domains, that comes under each of the top domains.
- Example: The top domain “Products” has 16 sub domains ranging from apparels to grocery.
-
Multiple Text Sources Support: We at serendio have done extensive research on the best mechanisms to predict the sentiment of various text types that include text from sources like: Blogs, Microblogs, News Articles, Reviews, Comments and General text. Each of these text sources has its own sentiment rich spots that we need to concentrate on to get the precise sentiment scores. Some Sentiment Rich Spots,
- Title of the text in the case of News Articles, reviews, etc.
- First and Last paragraphs in the case of Blogs.
- Emoticons, Acronyms and Abbreviations in the case of Comments and Microblogs. We have intelligent mechanism to dynamically vary the sentiment scoring of any text based on its source and sentiment hotspots. We have intelligent mechanism to dynamically vary the sentiment scoring of any text based on its source and sentiment hotspots.
-
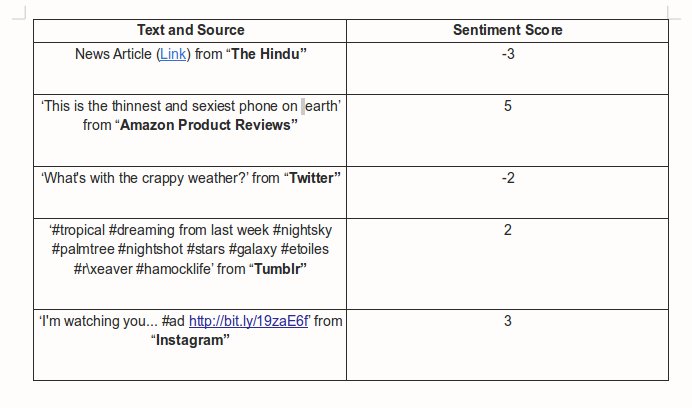
Scored Results and Power to the Customer: Most often in the field of sentiment analysis the end results are either positive, negative or neutral given any text, but we at serendio were really curious to know about the degree of positivity or negativity, that is, given any text we wanted to determine its sentiment polarity. So instead of just giving class labels, we give integer values ranging from -5 to +5 (Most Negative to Most Positive) depending on the polarity of the text as results. Thus making our models more fine and precise in determining the sentiments with more granularity. We give the Customers the power to determine what score ranges they feel is positive, negative or neutral, thus making the sentiment models more adaptive to different kinds of businesses, rather than enforcing something predetermined on them.
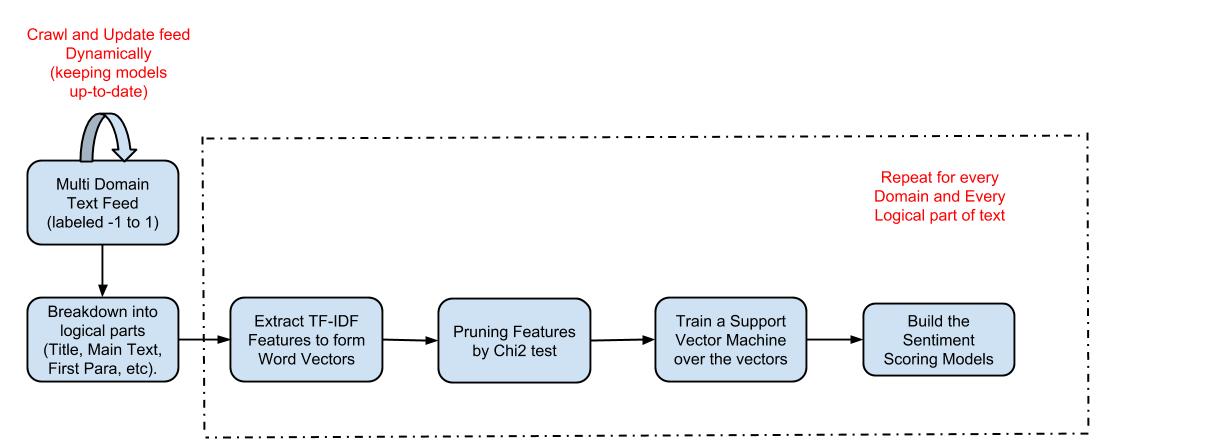
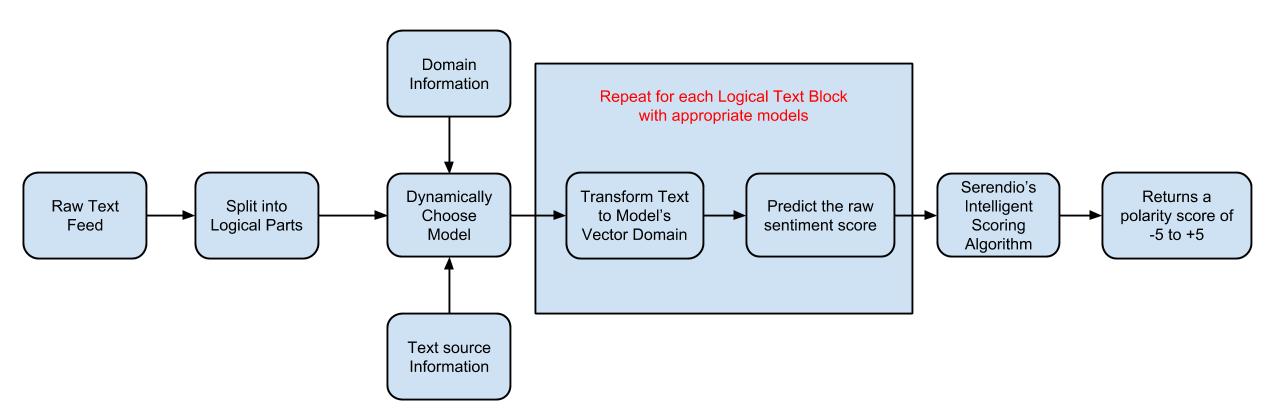
On an average each of our models have exceptional recall values ranging from 85% to 90%. (we are still working on ways to improve the accuracy). Find below the result snippets,
Copyright 2015 Satish Palaniappan
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.