Данный "справочник" не является авторским, а лишь собранная информация из открытого доступа в одном месте для удобства
- Java Core
- ООП. Наследование
- ООП. Инкапусляция
- ООП. Полиморфизм
- ООП. Абстракция
- Модификаторы доступа
- Конструктор
- Связь любых классов с Object
- Local Variable
- Instance Variable
- Объект
- Класс
- Интерфейс
- Абстрактный класс
- Абстрактный метод
- Разница между интерфейсом и абстрактным классом
- Типы данных
- Автоупаковка и автораспаковка
- Mutable и Immutable
- Final
- Static
- Сигнатура метода
- Отношения между классами (объектами)
- Ассоциация. Агрегация и композиция
- Разница между == и equals()
- equals()
- hashCode()
- Контракт между equals() и hashCode()
- Правила переопределения equals()
- Коллизия в hashCode
- Класс String
- StringBuilder и StringBuffer
- String Pool (строковый пул)
- Память в Java
- Java Collections
- Java Exceptions
- Stream API
- Java Multithreading
- Java лямбда-выражения и функциональные интерфейсы
- Spring Framework
- Что такое Spring
- Особенности и преимущества Spring Framework
- Spring контейнеры
- Жизненный цикл Context
- Bean
- Жизненный цикл бинов
- Как настроить класс как Spring Bean
- Статический Bean
- Inversion of Control
- Dependency Injection
- Как реализуется DI в Spring Framework
- Связывание и @Autowired
- MVC
- Шаблон проектирования Front Controller
- В чем разница между Filters, Listeners и Interceptors
- Связывание форм
- Исключения в Spring MVC
- Локализация в приложениях Spring MVC
- Spring Interceptor
- CommandLineRunner и ApplicationRunner
- Реактивное программирование
- Паттерны в Spring Framework
- AOP и составные части
- Spring AOP vs ASPECTJ
- Некоторые частые аннотации Spring
- Различия @Component, @Service, @Repository, @Controller
- Различия @Controller и @RestController
- @Qualifier and @Primary
- @Profile
- @LookUp
- @Target и @Retention
- @Resource
- @Inject
- @Autowired vs @Resource vs @Inject
- @Conditional
- Как управлять транзакциями в Spring
- Как Spring работает с DAO
- Model vs ModelMap vs ModelAndView
- В чем разница между model.put() и model.addAttribute()
- PreparedStatementCreator
- SOAP vs REST
- Spring Data
- Конфигурация Spring Data
- Spring Security
- Spring Boot
- Starter packs
- @Value
- Что нового в Spring 5
- RestTemplate и JDBCTemplate
- Socket
- SOLID
- Single Responsibility Principle (Принцип единственной ответственности)
- Open Closed Principle (Принцип открытости/закрытости)
- Liskov’s Substitution Principle (Принцип подстановки Барбары Лисков)
- Interface Segregation Principle (Принцип разделения интерфейса)
- Dependency Inversion Principle (Принцип инверсии зависимостей)
- Паттерны
- БД
- Что такое база данных
- Что такое система управления базами данных
- Что такое реляционная модель данных
- Простой, составной, потенциальный, альтернативный, естественный, сурогатный ключи
- Что такое первичный ключ (Primary Key)
- Что такое внешний ключ (Foreign Key)
- Что такое нормализация
- Нормальные формы
- Денормализация
- Виды связей в БД
- Что такое индексы
- Какие типы индексов существуют
- Кластерные и некластерные индексы
- Индексация данных с небольшим количеством возможных значений
- Полное сканирование набора данных или индексирование
- Транзакция
- Требования к транзакциям
- Уровни изолированности транзакций
- Проблемы при параллельном доступе с использованием транзакций
- Cup теорема
- SQL
- Что такое SQL
- Операторы SQL
- NULL в SQL
- Временная таблица
- Представление (view)
- Синтаксис оператора SELECT
- Что такое JOIN
- Типы JOIN
- JOIN или подзапросы
- Оператор HAVING
- Различие между HAVING и WHERE
- Оператор ORDER BY
- Оператор GROUP BY
- Как GROUP BY обрабатывает значение NULL
- Разница между GROUP BY и DISTINCT
- Основные агрегатные функции
- Оператор EXISTS
- Операторы IN, BETWEEN, LIKE
- Ключевое слово UNION
- Ограничения на целостность данных
- Отличия PRIMARY и UNIQUE
- Как создать индекс
- Оператор MERGE
- Отличие DELETE и TRUNCATE
- Оператор EXPLAIN
- Что такое RETURNING
- Что такое хранимая процедура
- Что такое триггер
- Что такое курсор
- Разница типов данных DATETIME и TIMESTAMP
С помощью наследования можно создавать дочерние классы (child) на основе родительских (parent), путем наследования свойств и поведения. В Java для наследования используется ключевое слово extends
Особенности наследования:
- Множественное наследование в Java отсутствует
- Приватные поля и методы тоже наследуются, только к ним нет доступа у наследника (решение: геттеры и сеттеры)
- final классы не наследуются
- final методы не переопределяются
- static методы и переменные не наследуются (так как привязаны к классам, а не объектам)
- При наследовании от абстрактных классов, обязательна реализация их абстрактных методов, либо текущий класс тоже нужно объявить абстрактным
- При наличии не дефолтных конструкторов в родителе, в классе потомке их необходимо переопределять
- Переопределенным методам в наследнике можно расширять модификаторы доступа: private -> default -> protected -> public
- Переопределенным методам можно сужать присваиваемые исключения: Exception -> IOException -> FileNotFoundException
Сокрытие отдельных деталей внутреннего устройства классов от внешних по отношению к нему объектов или пользователей. За инкапсуляцию отвечают модификаторы доступа
Возможность идентично использовать объекты с одинаковыми интерфейсами без информации о конкретном типе этого объекта. Один интерфейс – множество реализаций. В Java за полиморфизм отвечают ключевые слова extends и implements Существует два вида полиморфизма – раннее и позднее связывание
Статический полиморфизм (раннее связывание):
- Происходит во время компиляции
- Решает, какой метод выполнять во время компиляции
- Перегрузка методов – пример статического полиморфизма
- К нему относятся приватные, статические и терминальные методы
- Наследование не участвует в раннем связывании
- В статическом полиморфизме участвуют не конкретные объекты, а информация о классе, тип которого представлен
Динамический полиморфизм (позднее связывание):
- Происходит во время выполнения
- Решает, какая конкретно реализация будет у метода во время выполнения
- Переопределение метода – пример динамического полиморфизма
- Позднее связывание – это назначение конкретного объекта, ссылки его типа или его суперкласса
- Наследование связано с динамическим полиморфизмом
Придание объекту характеристик, которые отличают его от всех других объектов, четко определяя его концептуальные границы. В Java за абстракцию отвечают интерфейсы
Инструмент, при помощи которого можно настроить доступ к классам, методам и переменным.
- private – только класс, внутри которого он объявлен
- default (не указан) – доступ только в конкретном пакете, в котором объявлен класс, метод, переменная
- protected – такой же доступ как в default, но еще и для тех классов, которые наследуются от класса с модификатором protected
- public – полный доступ во всем приложении
- Когда новый объект создается, программа использует для этого соответствующий конструктор
- Конструктор похож на метод. Его особенность заключается в том, что нет возвращаемого элемента, а его имя совпадает с именем класса
- Если не создается явно ни одного конструктора, то пустой конструктор будет создан автоматически
- Конструктор может быть переопределен
- Если был создан конструктор с параметрами, а нужен еще и пустой, то его нужно писать отдельно, так как он не создается автоматически при уже существующем с параметрами
Все классы прямо или через предков наследуются от класса Object
У класса Object есть 11 методов:
Class<?> getClass()— получение класса текущего объектаint hashCode()— получение хеш кода текущего объектаboolean equals(Object obj)— сравнение текущего объекта с другимObject clone()— создание и возвращение копии текущего объектаString toString()— получение строкового представления объектаvoid notify()— пробуждение одного потока, ожидающего на мониторе данного объекта (выбор потока рандомный)void notifyAll()— пробуждение всех потоков, ожидающего на мониторе данного объектаvoid wait()— переключает текущий поток в режим ожидания (замораживает его) на текущий монитор, работает только в synchronized блоке, пока какой-нибудь notify или notifyAll не разбудит потокvoid wait(long timeout)— также замораживает текущий поток на текущий монитор (на текущий synchronized), но уже с таймером выхода из этого состояния (ну или опять же: пока notify или notifyAll не разбудит)void wait(long timeout, int nanos)— метод, аналогичный вышеописанному, но с более точным таймеров выхода из заморозкиvoid finalize()— перед удалением этого объекта сборщиком мусора вызывается этот метод (напоследок). Он используется для очистки занимаемых ресурсов
Для корректного использования методов hashCode, equals, clone, toString, finalize их необходимо переопределять, учитывая текущую задачу и обстоятельства.
Переменная, которая определена внутри метода и существует до тех пор, пока выполняется этот метод. Как только выполнение закончится, локальная переменная перестанет существовать
Переменная, которая определена внутри класса, и она существует до того момента, пока существует объект
Объекты – некоторые сгруппированные, в которых содержатся различные методы, для работы с этими данными
Класс – шаблон для создания объектов. Может быть множество объектов одного класса
Совокупность методов и правил взаимодействия элементов системы. Другими словами, интерфейс определяет как элементы будут взаимодействовать между собой
- Все методы в интерфейсы публичные и абстрактные
- Все переменные public static final
- Бесконечное кол-во имплементаций
- Классы, которые реализуют интерфейс должны предоставить реализацию всех методов, которые есть в интерфейсе
Класс, который не может иметь экземпляров. Так же он может содержать абстрактные методы
Метод, который создан без реализации с ключевым словом abstract в абстрактном классе
Абстрактный класс:
- Имеет дефолтный конструктор; вызывается при создании потомка
- Содержит как абстрактные методы, так и не абстрактные
- Класс, который наследуется от абстрактного, должен реализовывать только абстрактные методы
- Абстрактный класс может содержать Instance Variable
Интерфейс:
- Не имеет никакого конструктора и не может быть инициализирован
- Содержит только абстрактные методы
- Класс, реализующий интерфейс, должен реализовать все методы
- Интерфейсы могут содержать только константы
В Java типы данных бывают двух видов: примитивные и ссылочные
Примитивные:
- Целые числа (byte, short, int, long)
- Числа с плавающей точкой (float, double)
- Логический (Boolean)
- Символьный (char)
Ссылочные:
- Классы
- Интерфейсы
- Массивы
- String
| Примитивные | Ссылочные |
|---|---|
| Хранят значение | Хранят ссылку объекта в памяти, на который ссылаются |
| Создаются присваиванием значения | Создаются через конструктор класса (присваивание только создает вторую ссылку) |
| Имеют строго заданный диапазон допустимых значений | По умолчанию – null |
| В аргументы методов попадают копии значения переменной | В методы передается значение ссылки – операция выполняется над оригинальным объектом, на который ссылается переменная |
| Могут использоваться для ссылки на любой объект объявленного или совместимого типа |
Автоупаковка – процесс автоматического преобразования из примитивного типа в соответствующий класс обертку
Автораспаковка – преобразование класса обертки в примитив. При null -> исключение NPE (NullPointerException)
Mutable – объекты, состояние и переменные которых можно изменить после создания
Immutable – объекты, состояние которых нельзя изменить после создания
final можно использовать для переменных, методов и классов
- final переменную нельзя переназначить на другой объект
- final метод не может быть переопределен
- final класс не может иметь наследников
static – модификатор, применяемый к полю, блоку, методу или внутреннему классу. Если этого не делать, то значение переменной будет привязываться к объекту, созданному по этому классу
- НЕЛЬЗЯ получить доступ к НЕ статическим членам класса, внутри статического контекста (метода/блока/…)
- В отличии от локальных переменных, статические поля и методы НЕ потокобезопасны. Учитывая, что каждый экземпляр класса имеет одну и ту же копию статической переменной, то такая переменная нуждается в защите. При использовании статических переменных они должны бить синхронизированы (synchronized)
- Применяя статические методы, отсутствует необходимость каждый раз создавать новый объект. Статический метод можно вызвать, используя тип класса, в котором эти методы описаны
- Нельзя переопределить статические методы. При попытке переопределения лишь спрячем метод суперкласса, такое явление называется сокрытием
- Объявить статическим можно и класс, за исключением класса верхнего уровня. Такие классы известны как “вложенные статические классы” (nested static class). Они бывают полезными для представления улучшенных связей
- Модификатор static так же можно объявить в статическом блоке инициализации, который будет выполнен во время загрузки класса
- Статические методы связываются во время компиляции, в отличии от связывания виртуальных или не статических методов, которые связываются во время исполнения на реальном объекте. Следовательно статические методы не могут быть переопределены, так как полиморфизм во время выполнения не распространяется на них
- Статические поля или переменные инициализируются после загрузки класса в память. Порядок инициализации сверху вниз, в том же порядке, в каком они описаны в исходном файле Java класса
- Во время сериализации статические поля, переменные не сериализуются
- static import. Данный модификатор имеет много общего со стандартным import, но в отличии от него позволяет импортировать один или все статические члены класса. При импортировании статических методов, к ним можно обращаться как будто они определены в этом же классе, можно получить доступ без указания имени класса
Сигнатура метода – это имя метода плюс его аргументы (причем порядок аргументов имеет значение). В сигнатуру метода не входит возвращаемое значение, а также бросаемы исключения.
Пример правильной сигнатуры:
doSomething(int a, double b, double c)Пример неправильной сигнатуры:
int doSomething(int firstArg, int secondArg) throws ExceptionСигнатура метода в сочетании с возвращаемым типом и бросаемыми исключениями называется контрактом метода
В Java есть два вида отношений
IS-A:
Принцип IS-A в ООП основан на наследовании классов или реализации интерфейсов. К примеру, если класс Lion наследует класс Cat, мы говорим, что Lion является Cat
Lion IS-A Cat
(но не всякий Cat является Lion)
HAS-A:
Ассоциация – это один класс ссылается на другой (или на друг друга)
Например, класс Car может ссылаться на класс Passenger:
Car HAS-A Passenger
И наоборот: если Passenger имеет ссылку на Car:
Passenger HAS-A Car
Агрегация и композиция – частные случаи ассоциации
Агрегация – отношение, когда один объект является частью другого (но не обязательно это связь должна быть). Например: пассажир может находиться в машине, так же их может быть несколько или не быть совсем. Один пассажир, несколько или ни одного – от этого не зависит работоспособность второго в агрегации класса. Агрегация более свободные ассоциативные отношения классов.
Композиция – более жесткое отношение, когда объект является не просто частью другого, но и работа второго зависит от первого. Например, двигатель может быть без машины, но вне машины он бесполезен, так же и машина не может работать без двигателя.
При сравнении примитивных типов используется ==, так как переменные содержат конкретные значения и есть возможность их сравнить. Так же примитивные переменные не являются объектами – они не наследуются от класса Object и не имеют метода equals(). Когда сравниваем ссылочные переменные, то == будет сравнивать лишь значение ссылок, на тот же объект ведет ссылка или нет. И даже при условии, что объекты идентичны, то результат такого сравнения будет false, так как это другой объект. Для сравнения ссылочных переменных надо использовать метод equals(). Важно заметить, что для корректной работы метода equals() его необходимо переопределить, в противном случае он будет работать так же, как и ==
equals() – метод класса Object, задача которого сравнивать объекты и определять равны они или нет
hashCode() – метод класса Object, который генерирует некоторое число на основе предоставленного объекта
Для корректной работы методов equals() и hashCode() в первую очередь их нужно переопределить. После чего они должны соблюдать правила:
- Одинаковые объекты, для которых сравнение через equals() возвращает true, обязательно имеют одинаковые хэш-коды
- Объекты с одинаковыми хэш-кодами не всегда могут быть равны
Рефлексивность – для любого значения x выражение вида x.equals(x) всегда должно возвращать true (если x != null)
Симметричность – для любых значений x и y выражение вида x.equals(y) должно возвращать true только в том случае, если y.equals(x) тоже возвращает true
Транзитивность – для любых значений x, y и z, если выражение x.equals(y) возвращает true, при этом y.equals(z) тоже возвращает true, тогда и x.equals(z) должно возвращать true
Согласованность – для любых значение x и y повторный вызов x.equals(y) будет всегда возвращать значение предыдущего вызова этого метода при условии, что поля, используемые для сравнения двух объектов, не были изменены между вызовами
Сравнение null – для любого значения x вызов x.equals(null) всегда будет возвращать false
Коллизия – это ситуация, когда два разных объекта имеют одинаковые хэш-коды Для борьбы с коллизией нужно иметь хорошую имплементацию метода hashCode, чтобы разброс значений был максимальным и шанс повторения значений был минимальным
String – стандартный класс в Java, отвечающий за хранение и манипуляции со строковыми значениями, является immutable классом. Так же String является final. Особенности:
- Благодаря неизменности, хэш-код экземпляра класса кэшируется. Его не нужно вычислять каждый раз
- Класс String можно использовать в многопоточной среде без дополнительной синхронизации
- Для него перегружен оператор
+для конкатенации строк, поэтому она выполняется быстро. Под капотом конкатенация строк выполняется StringBuilder’ом или StringBuffer’ом (на усмотрение компилятора) и методом append
Это два фактически одинаковых класса с той лишь разницей, что один из них используется в многопоточной среде (StringBuffer)
В памяти Java (Heap) есть область - строковый пул, которая предназначена для хранения строковых значений. Например, при создании строки:
String str = “Hello, World!”;Происходит проверка, имеется ли такое значение в строковом пуле, если нет, то создается новое значение, если имеется, то присваивается ссылка на существующее.
При необходимости можно создать новое значение в пуле даже если такое уже существует, через оператор new
Для оптимальной работы приложения JVM делит память на две области: стек (stack) и куча (heap). Каждый раз при создании переменной, обновления переменной, создании метода JVM выделяет область памяти под это в стеке или куче.
Стек:
Стек работает по схеме LIFO - last in first out (последний вошел, первый вышел) При каждом вызове метода, который содержит примитивные значения или ссылки на объекты в куче, то на вершине стека выделяется блок памяти под них Стек хранит примитивные значения, создаваемых в методах, а также ссылки на объекты в куче, на которые ссылается метод
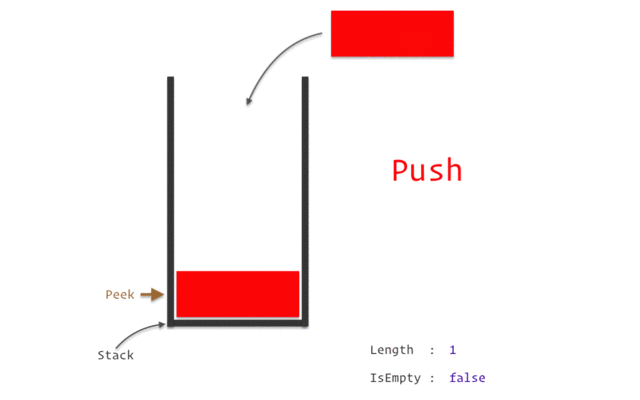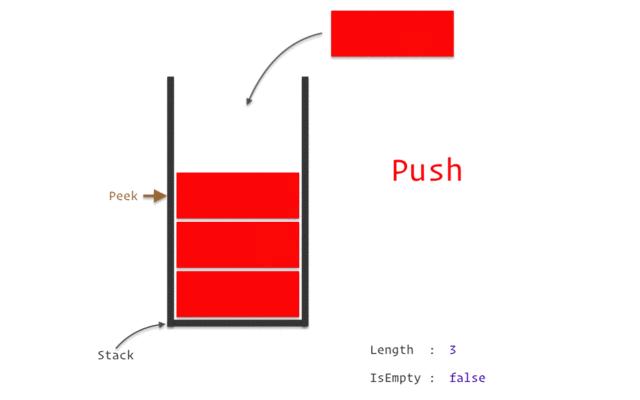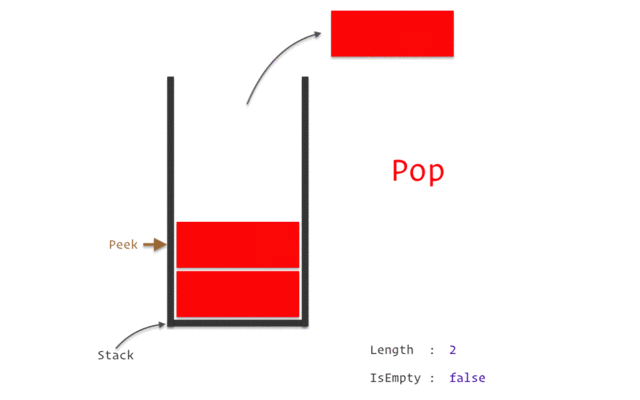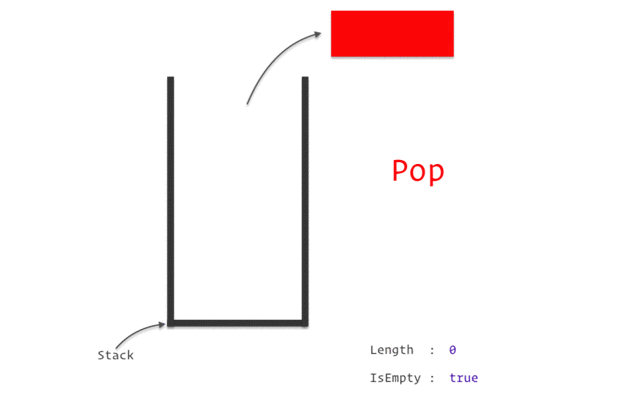
Когда метод завершает выполнение, блок памяти, отведенный для его нужд, очищается, и пространство становится свободным для следующего метода. Особенности стека:
- Стек заполняется и очищается по мере вызова и завершения методов
- Переменные в стеке существуют до тех пор, пока выполняется метод, в котором они были созданы
- Если память стека будет заполнена, то выбросится исключение StackOverFlowError
- Доступ к стеку осуществляется быстрее, чем к куче
- Является потокобезопасным, так как для каждого потока создается свой стек
Куча:
Эта область памяти используется для динамического выделения памяти для объектов и классов JRE во время выполнения. Новые объекты всегда создаются в куче, а ссылки на них хранятся в стеке. Эта область памяти разбита на несколько частей, которые называются поколения:
- Young Generation – область, где размещаются новые созданные объекты. Когда она заполняется происходит сборка мусора.
- Old (Tenured) Generation – здесь хранятся долгоживущие объекты. Когда объекты из Young Generation достигают определенного “возраста”, они перемещаются в Old Generation.
- Permanent Generation – эта область содержит метаинформацию о классах и методах приложения, но начиная с java 8 данная область памяти была упразднена.

Особенности кучи:
- Когда эта область памяти заполняется, то выбрасывается исключение OutOfMemoryError
- Доступ к ней медленнее, чем к стеку
- Эта памяти, в отличии от стека автоматически не освобождается. Для сбора неиспользуемых объектов здесь используется сборщик мусора
- В отличии от стека, куча не является потокобезопасной и ее необходимо контролировать, правильно синхронизируя код
Существует две иерархии коллекций в Java
Первая – непосредственно Collection:

- Set – интерфейс, описывающий такую структуру данных, как множество, содержащее неупорядоченные уникальные элементы. У интерфейса есть стандартные реализации – HashSet, TreeSet, LinkedHashSet
- List – интерфейс, описывающий структуру данных, которая хранит упорядоченную последовательность объектов. Стандартные реализации – ArrayList, LinkedList
- Queue – интерфейс, описывающий структуру данных, хранящую элементы в виде очереди, которая следует правилу FIFO – first in first out (первый ушел, первый пришел). Стандартные реализации – LinkedList, PriorityQueue
Вторая - Map:

Тут подразделений как таковых нет, так как эта коллекция является в своем роде подколлекцией, которая лежит отдельно. Стркутура данных Map подразумевает, что в ней хранятся даные в виде пар ключ-значение

ArrayList – реализация изменяемого массива интерфейса List, который отвечает за список (динамический массив). Этот класс реализует все необязательные операции со списком и предоставляет методы управления размером массива, который используется для хранения списка. В основе лежит идея динамического массива. А именно, возможность добавлять и удалять элементы, при этом будет увеличиваться или уменьшаться по необходимости. В ArrayList можно хранить только ссылочные типы, для хранения примитивов необходимо использовать классы-обертки.
У ArrayList есть 3 конструктора:
- Пустой конструктор с начальной емкостью массива = 10
- Конструктор, который ждет на входе другую коллекцию, на основе которой создаст список
- С параметром int, который выступает в роли начальной емкости списка
При заполнении списка он автоматически расширяется путем создания нового массива и переносом элементов по формуле: размер старого массива * 1.5 + 1
Особенности ArrayList:
- Вставка в конец и доступ по индексу очень быстрые O(1)
- Что бы вставить элемент в начало или середину, понадобиться скопировать все элементы на одну ячейку вправо, а затем вставить новый элемент в нужную позицию
- Доступ по значению зависит от количества элементов O(n)
- В отличии от классического массива может хранить null
LinkedList – двусвязный список. Все элементы по сути являются одной цепью. У каждого элемента помимо тех данных, которые он хранит имеется ссылка на следующий и предыдущий элементы. По этим ссылкам можно переходить от одного элемента к другому.

Внутри LinkedList есть главный объект – head, который хранит информацию о количестве элементов, а также ссылку на первый и последний элементы.

На данном этапе поле size = 0, а ссылки first и last = null. После добавления элемента список будет выглядеть следующим образом:

Теперь size = 1, а first и last указывают на “ноду” - “Johnny”.
Добавим еще один элемент в список:

Теперь в head size = 2, first указывает на “Johnny’, last указывает на “Watson”.
Нода “Johnny”: previous = null (так как это первая нода), next = “Watson”
Нода “Watson”: previous = “Johnny”, next = null (так как это последняя нода)
Вот по какому принципу добавляются элементы в середину списка:

Добавлен новый элемент “Hamish”, для этого было нужно просто переприсвоить ссылки на элементы.
Особенности LinkedList:
- Так же, как и массив, индексируется с 0
- Доступ к первому и последнему элементу не зависят от количества элементов – O(1)
- Получение элемента по индексу, вставка или удаление из середины списка зависят от количества элементов – O(n)
- Можно использовать механизм итератора: тогда вставка и удаление будут происходить за константное время
- В отличии от классического массива, может хранить null
ArrayList следует использовать, когда в приоритете доступ по индексу, так как эти операции выполняются за константное время. Минусы в скорости вставки/удаления из середины списка, так как при этой операции все элементы правее добавляемого/удаляемого сдвигаются.
LinkedList удобен когда важнее быстродействие операций удаления/вставки, так как выполняются за константное время. Операции доступа по индексу производятся путем перебора с начала или конца.
Если необходимо часто вставлять/удалять из середины списка – лучше использовать LinkedList, во всех остальных случаях ArrayList
| Операция | ArrayList | LinkedList |
|---|---|---|
| get | O(1) | O(n) |
| add | O(1)* | O(1) |
| add(index, value) | O(n) | O(n-index) |
| remove | O(n) | O(n-index) |
Класс HashSet реализует интерфейс Set, основан на хэш-таблице, а также поддерживается с помощью экземпляра HashMap. В HashSet элементы не упорядочены, нет никаких гарантий, что элементы будут в том же порядке спустя какое-то время. Операции добавления, удаления и поиска будут выполняться за константное время при условии, что хэш-функция правильно распределяет элементы по «корзинам».
Особенности:
- Т.к. класс реализует интерфейс Set, он может хранить только уникальные значения
- Может хранить NULL – значения
- Порядок добавления элементов вычисляется с помощью хэш-кода
Для поддержания постоянного времени выполнения операций время, затрачиваемое на действия с HashSet, должно быть прямо пропорционально количеству элементов в HashSet + «емкость» встроенного экземпляра HashMap (количество «корзин»). Поэтому для поддержания производительности очень важно не устанавливать слишком высокую начальную ёмкость (или слишком низкий коэффициент загрузки).
Начальная емкость – изначальное количество ячеек («корзин») в хэш-таблице. Если все ячейки будут заполнены, их количество увеличится автоматически.
Коэффициент загрузки – показатель того, насколько заполненным может быть HashSet до того момента, когда его емкость автоматически увеличится. Когда количество элементов в HashSet становится больше, чем произведение начальной емкости и коэффициента загрузки, хэш-таблица ре-хэшируется (заново вычисляются хэшкоды элементов, и таблица перестраивается согласно полученным значениям) и количество ячеек в ней увеличивается в 2 раза.
Коэффициент загрузки = Количество хранимых элементов в таблице / размер хэш-таблицы
Коэффициент загрузки и начальная емкость – два главных фактора, от которых зависит производительность операций с HashSet. Коэффициент загрузки, равный 0,75, в среднем обеспечивает хорошую производительность. Если этот параметр увеличить, тогда уменьшится нагрузка на память (так как это уменьшит количество операций ре-хэширования и перестраивания), но это повлияет на операции добавления и поиска. Чтобы минимизировать время, затрачиваемое на ре-хэширование, нужно правильно подобрать параметр начальной емкости. Если начальная емкость больше, чем максимальное количество элементов, поделенное на коэффициент загрузки, то никакой операции ре-хэширования не произойдет в принципе.
HashSet не является структурой данных с встроенной синхронизацией, поэтому если с ним работают одновременно несколько потоков, и как минимум один из них пытается внести изменения, необходимо обеспечить синхронизированный доступ извне. Часто это делается за счет другого синхронизируемого объекта, инкапсулирующего HashSet. Если такого объекта нет, то лучше всего подойдет метод Collections.synchronizedSet(). На данный момент это лучшее средство для предотвращения несинхронизированных операций с HashSet.
Конструкторы HashSet:
HashSet h = new HashSet();— конструктор по умолчанию. Начальная емкость по умолчанию –16, коэффициент загрузки –0,75.HashSet h = new HashSet(int initialCapacity);– конструктор с заданной начальной емкостью. Коэффициент загрузки –0,75.HashSet h = new HashSet(int initialCapacity, float loadFactor);— конструктор с заданными начальной емкостью и коэффициентом загрузки.HashSet h = new HashSet(Collection C);– конструктор, добавляющий элементы из другой коллекции.
Все классы, реализующие интерфейс Set, внутренне поддерживаются реализациями Map. HashSet хранит элементы с помощью HashMap. Хоть и для добавления элемента в HashMap он должен быть представлен в виде пары «ключ-значение», в HashSet добавляется только значение.
На самом деле значение, которые мы передаем в HashSet, является ключом к объекту HashMap, а в качестве значения в HashMap используется константа. Таким образом, в каждой паре «ключ-значение» все ключи будут иметь одинаковые значения.
HashSet основан на хэш-таблице, и операции добавления, удаления или поиска в среднем будут выполняться за константное О(1) время.
Класс LinkedHashSet расширяет класс HashSet, не добавляя никаких новых методов. Класс поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор.
Класс TreeSet в Java обеспечивает реализацию интерфейса Set, который использует древо для хранения. Объекты хранятся в отсортированном и возрастающем порядке.
Время доступа и поиска довольно быстрое, что делает TreeSet отличным выбором при хранении большого количества отсортированной информации, которая должна быть найдена быстро.
Конструкторы:
TreeSet();- Этот конструктор создает пустое дерево, которое будет сортироваться в порядке возрастания в соответствии с естественным порядком его элементов.TreeSet(Collection c);- Этот конструктор создает набор деревьев, содержащий элементы коллекции c.TreeSet(Comparator comp);- Этот конструктор создает пустой набор деревьев, который будет сортироваться в соответствии с данным компаратором.TreeSet(SortedSet ss)- Этот конструктор создает TreeSet, который содержит элементы данного SortedSet.
Map — это структура данных, которая содержит набор пар “ключ-значение”. По своей структуре данных напоминает словарь, поэтому ее часто так и называют. В то же время, Map является интерфейсом, и в стандартном jdk содержит основные реализации: Hashmap, LinkedHashMap, Hashtable, TreeMap. Самая используемая реализация — Hashmap.
HashMap работает с парами ключ – значение.
Внутри HashMap есть массив нод:
Node<K,V>[] table
По умолчанию размер массива — 16, и он увеличивается каждый раз в два раза по мере заполнения элементами (при достижении LOAD_FACTOR — определенного процента заполненности, по умолчанию он — 0.75).
Каждая из нод хранит в себе хеш ключа, ключ, значение, ссылку на следующий элемент:

Собственно, “ссылка на следующий элемент” означает, что мы имеем дело с односвязным списком, где каждый элемент содержит ссылку на следующий.
То есть HashMap хранит данные в массиве односвязных списков.
Когда одна ячейка массива table имеет ссылку на подобный односвязный список, состоящий из более чем одного элемента, это не есть хорошо. Такое явление называется коллизия.
Сперва берется hachCode() ключа. Поэтому для корректной работы HashMap в качестве ключей нужно брать классы, в которых данный метод переопределен.
Далее этот хеш код используется во внутреннем методе — hash() — для определения числа в пределах размера массива table.
Далее по полученному числу, идёт обращение к конкретной ячейке массива table.
Далее два варианта:
- Ячейка пустая — в нее сохраняется новое значение
Node. - Ячейка не пустая — сравнивается значение ключей. Если они равны, новое значение
Nodeперезаписывает старое, если не равны — идёт обращение к элементу next (следующему), идёт сравнение уже с его ключом… И так до тех пор, пока новое значение не перезапишет некоторое старое или не достигнет конца односвязного списка и сохранится там последним элементом.
При поиске элемента по ключу (метод get(<key>)), вычисляется hashCode ключа, потом его значение в пределах массива с помощью hash(), и по полученному числу находится ячейка массива table, в которой уже ведется поиск путем перебора нод и сравнения ключа искомой ноды с ключом текущей.
Операции в Map при идеальном раскладе имеют алгоритмическую сложность O(1), ведь идёт обращение к массиву; независимо от количества элементов операции у массива имеют сложность O(1).
Когда используемая ячейка массива не пустая и там уже есть некоторые ноды, алгоритмическая сложность превращается в линейную O(N), ведь теперь необходимо перебрать элементы, прежде чем найдется нужное место.
Начиная с Java 8, если у односвязного списка node больше 8 элементов (коллизии), он превращается в двоичное дерево. В таком случае алгоритмическая сложность будет уже не O(N), а O(log(N))
Как и HashMap, в Java Hashtable хранит пары ключей/значений в хэш-таблице. Используя Hashtable, вы указываете объект, который используется как ключ, и значение, которое вы ходите связать с этим ключом. Этот ключ затем хэшируется, а полученный хэш-код используется как индекс, в котором значение хранится в таблице.
HashTable - синхронизирован
Констркуторы:
Hashtable();- Этот стандартный конструктор хэщ-таблицы, который создаёт экземпляр класса Hashtable.Hashtable(int size);- Этот конструктор принимает целочисленный параметр и создаёт хэш-таблицу, имеющая начальный размер, заданный размером целочисленного значения.Hashtable(int size, float fillRatio);- Это создаёт хэш-таблицу, в которой есть начальный размер, указанный вsize, и коэффициент заполнения, заданныйfillRatio. Этот коэффициент должен принимать значение между0.0и1.0, и он определяет, насколько полной может быть хэш-таблица прежде чем она будет изменена в размерах.Hashtable(Map < ? extends K, ? extends V > t);- Это построит Hashtable с указанными отображениями.
Класс TreeMap в Java реализует интерфейс Map, используя дерево. TreeMap обеспечивает эффективное средство хранения пар ключ/значение в отсортированном порядке и позволяет быстро извлекать данные.
Следует отметить, что, в отличие от хэш-карты, карта деревьев гарантирует, что ее элементы будут отсортированы в порядке возрастания ключа.
Конструкторы:
TreeMap();- Этот конструктор создает пустое дерево, которое будет сортироваться по естественному порядку его ключей.TreeMap(Comparator comp);- Этот конструктор создает пустую древовидную карту, которая будет сортироваться с использованием компаратора comp.TreeMap(Map m);- Этот конструктор инициализирует древовидную карту с элементами из m, которые будут отсортированы с использованием естественного порядка ключей.TreeMap(SortedMap sm);- Этот конструктор инициализирует карту дерева с записями из SortedMap sm, которые будут отсортированы в том же порядке, что и sm.
TreeMap имплементирует интерфейс NavigableMap, который наследуется от SortedMap. Имплементируя интерфейсы NavigableMap и SortedMap, TreeMap получает дополнительный функционал, которого нет в HashMap, но плата за это — производительность.
Под капотом TreeMap использует структуру данных, которая называется красно-чёрное дерево.
- Порядок элементов.
HashMapиHashtableне гарантируют, что элементы будут храниться в порядке добавления. Кроме того, они не гарантируют, что порядок элементов не будет меняться со временем. В свою очередь,TreeMapгарантирует хранение элементов в порядке добавления или же в соответствии с заданным компаратором. - Допустимые значения.
HashMapпозволяет иметь ключ и значение null,HashTable— нет.TreeMapможет использовать значения null только если это позволяет компаратор. Без использования компаратора (при хранении пар в порядке добавления) значение null не допускается. - Синхронизация. Только
HashTableсинхронизирована, остальные — нет. Если к мапе не будут обращаться разные потоки, рекомендуется использоватьHashMapвместоHashTable.
| Сравнение | HashMap | HashTable | TreeMap |
|---|---|---|---|
| Упорядоченность элементов | Нет | Нет | Да |
| null в качестве значения | Да | Нет | Да/Нет |
| Потокобезопасность | Нет | Да | Нет |
| Алгоритмическая сложность поиска элементов | O(1) | O(1) | O(log n) |
| Структура данных под капотом | Хэш-таблица | Хэш-таблица | Красно-чёрное дерево |
| Методы | Описание |
|---|---|
addAll(colls, e1, e2, e3, ..) |
Добавляет в коллекцию colls элементы e1, e2, e3,... |
fill(list, obj) |
Заменяет в переданном списке все элементы на obj |
nCopies(n, obj) |
Возвращает список, состоящий из n копий объекта obj |
replaceAll(list, oldVal, newVal) |
Заменяет в списке list все значения oldVal на newVal |
copy(dest, src) |
Копирует все элементы из списка src в список dest |
reverse(list) |
Разворачивает список задом наперед |
sort(list) |
Сортирует список в порядке возрастания |
rotate(list, n) |
Циклично сдвигает элементы списка list на n элементов |
shuffle(list) |
Случайно перемешивает элементы списка |
min(colls) |
Находит минимальный элемент коллекции colls |
max(colls) |
Находит максимальный элемент коллекции colls |
frequency(colls, obj) |
Определяет, сколько раз элемент obj встречается в коллекции colls |
binarySearch(list, key) |
Ищет элемент key в отсортированном списке, возвращает индекс. |
disjoint(colls1, colls2) |
Возвращает true, если у коллекций нет общих элементов |
Исключение в Java — представляет проблему, которая возникает в ходе выполнения программы. В случае возникновения в Java исключения (exception), или исключительного события, имеет место прекращение нормального течения программы, и программа/приложение завершаются в аварийном режиме, что не является рекомендованным, и, как следствие, подобные случаи требуют в Java обработку исключений.
Все классы исключений в Java представляют подтипы класса java.lang.Exception. Класс исключений является подклассом класса Throwable. Помимо класса исключений существует также подкласс ошибок, образовавшихся из класса Throwable.
Ошибки представляют аварийное состояние вследствие значительных сбоев, которые не обрабатываются программами Java. Генерирование ошибок предназначено для отображения ошибок, выявленных средой выполнения. Примеры: JVM исчерпал имеющийся объем памяти. Обычно, программы не могут восстановить неполадки, вызванные ошибками.
Класс исключений делится на два основных подкласса: класс IOException и класс RuntimeException.
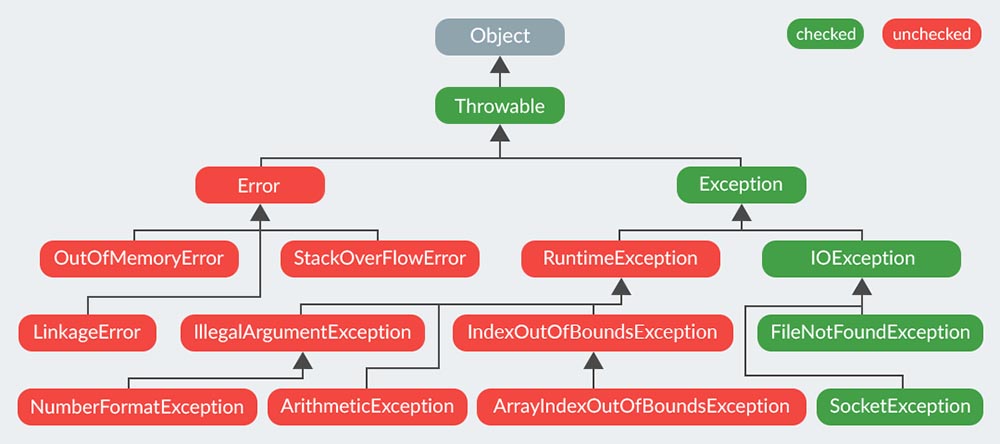
Checked - исключения, которые проверяются во время компиляции. Ксли какой-то код в методе во время исполнения выбьет checked исключение, метод обязан либо обработать его при помощи try-catch, либо пробросить его дальше.
Unchecked - исключения, которые на этапе компиляции не проверяются. То есть метод может генерировать RuntimeException, а компилятор не напомнит каким-то образом это обработать.
Примеры checked исключений: Throwable, Exception, IOException, FileNotFoundException, SocketException
Примеры unchecked исключений: Error, OutOfMemoryError, StackOverFlowError, RuntimeException, IllegalArgumentException
Блок try/catch размещается в начале и конце кода, который может сгенерировать исключение. Код в составе блока try/catch является защищенным кодом, синтаксис использования try/catch выглядит следующим образом:
try {
// Защищенный код
}catch(НазваниеИсключения e1) {
// Блок catch
}Код, предрасположенный к исключениям, размещается в блоке try. В случае возникновения исключения, обработка данного исключения будет производиться соответствующим блоком catch. За каждым блоком try должен немедленно следовать блок catch либо блок finally.
Оператор catch включает объявление типа исключения, которое предстоит обработать. При возникновении исключения в защищенном коде, блок catch (либо блоки), следующий за try, будет проверен. В случае, если тип произошедшего исключения представлен в блоке catch, исключение передается в блок catch аналогично тому, как аргумент передается в параметр метода.
За блоком try могут следовать несколько блоков catch. Синтаксис многократных блоков catch выглядит следующим образом:
try {
// Защищенный код
}catch(ИсключениеТип1 e1) {
// Блок catch
}catch(ИсключениеТип2 e2) {
// Блок catch
}catch(ИсключениеТип3 e3) {
// Блок catch
}Представленные выше операторы демонстрируют три блока catch, однако, после однократного try количество данных используемых блоков может быть произвольным. В случае возникновения исключения в защищенном коде, исключение выводится в первый блок catch в списке. Если тип данных генерируемого исключения совпадает с ИсключениеТип1, он перехватывается в указанной области. В обратном случае, исключение переходит ко второму оператору catch. Это продолжается до тех пор, пока не будет произведен перехват исключения, либо оно не пройдет через все операторы, в случае чего выполнение текущего метода будет прекращено, и исключение будет перенесено к предшествующему методу в стеке вызовов.
В Java finally следует за блоком try либо блоком catch. Блок finally в коде выполняется всегда независимо от наличия исключения.
Использование блока finally позволяет запустить какой-либо оператор, предназначенный для очистки, не зависимо от того, что происходит в защищенном коде.
Блок finally в Java появляется по окончании блоков catch, его синтаксис выглядит следующим образом:
try {
// Защищенный код
}catch(ИсключениеТип1 e1) {
// Блок catch
}catch(ИсключениеТип2 e2) {
// Блок catch
}catch(ИсключениеТип3 e3) {
// Блок catch
}finally {
// Блок finally всегда выполняется.
}Важно:
- Выражение catch не может существовать без оператора try
- При наличии блока try/catch, выражение finally не является обязательным
- Блок try не может существовать при отсутствии выражения catch либо выражения finally
- Существование какого-либо кода в промежутке между блоками try, catch, finally является невозможным
В случае если метод не может осуществить обработку контролируемого исключения, производится соответствующее уведомление при использовании ключевого слова throws в Java. Ключевое слово throws появляется в конце сигнатуры метода.
При использовании ключевого слова throw вы можете произвести обработку вновь выявленного исключения либо исключения, которое было только что перехвачено.
Следует внимательно различать ключевые слова throw и throws в Java, так как throws используется для отложенной обработки контролируемого исключения, а throw, в свою очередь, используется для вызова заданного исключения.
public void deposit(double amount) throws RemoteException {
// Реализация метода
throw new RemoteException();
}В норме, при использовании различных видов ресурсов, таких как потоки, соединения и др., нам предстоит закрыть их непосредственно при использовании блока finally.
Конструкция try-with-resources, также именуемая как автоматическое управление ресурсами, представляет новый механизм обработки исключений, который был представлен в 7-ой версии Java, осуществляя автоматическое закрытие всех ресурсов, используемых в рамках блока try/catch.
Чтобы воспользоваться данным оператором, вам всего лишь нужно разместить заданные ресурсы в круглых скобках, после чего созданный ресурс будет автоматически закрыт по окончании блока.
try(FileReader fr = new FileReader("Путь к файлу")) {
// использование ресурса
}catch() {
// тело catch
}
}При записи собственных классов исключений следует принимать во внимание следующие аспекты:
- Все исключения должны быть дочерними элементами Throwable
- Если вы планируете произвести запись контролируемого исключения с автоматическим использованием за счет правила обработки или объявления, вам следует расширить класс Exception
- Если вы хотите произвести запись исключения на этапе выполнения, вам следует расширить класс RuntimeException
class MyException extends Exception {
}Ошибка указывает на проблему, которая в основном возникает из-за нехватки системных ресурсов. И наше приложение не должно обнаруживать эти типы проблем. Некоторые из примеров ошибок — сбой системы и ошибка нехватки памяти. Ошибки в основном возникают во время выполнения, так как они относятся к непроверенному типу.
Исключения — это проблемы, которые могут возникнуть во время выполнения и во время компиляции. Как правило это происходит в коде, написанном разработчиками. То есть exception более предсказуемые и более зависящие от нас как от разработчиков. В это же время errors более случайны и более независимы от нас, а скорее зависимы от неполадок самой системы, в которой работает наше приложение.
Начиная с JDK 8 в Java появился новый API - Stream API. Его задача - упростить работу с наборами данных, в частности, упростить операции фильтрации, сортировки и другие манипуляции с данными. Вся основная функциональность данного API сосредоточена в пакете java.util.stream.
Одной из отличительных черт Stream API является применение лямбда-выражений, которые позволяют значительно сократить запись выполняемых действий.
При работе со Stream API важно понимать, что все операции с потоками бывают либо терминальными (terminal), либо промежуточными (intermediate).
Промежуточные операции возвращают трансформированный поток. К возвращенному потоку также можно применить ряд промежуточных операций.
Конечные или терминальные операции возвращают конкретный результат. Например, в примере выше метод count() представляет терминальную операцию и возвращает число. После этого никаких промежуточных операций естественно применять нельзя.
Все потоки производят вычисления, в том числе в промежуточных операциях, только тогда, когда к ним применяется терминальная операция.
В основе Stream API лежит интерфейс BaseStream. Его полное определение:
interface BaseStream<T , S extends BaseStream<T , S>>Здесь параметр T означает тип данных в потоке, а S - тип потока, который наследуется от интерфейса BaseStream.
BaseStream определяет базовый функционал для работы с потоками, которые реализуется через его методы:
void close(): закрывает потокboolean isParallel(): возвращает true, если поток является параллельнымIterator<Т> iterator(): возвращает ссылку на итератор потокаSpliterator<Т> spliterator(): возвращает ссылку на сплитератор потокаS parallel(): возвращает параллельный поток (параллельные потоки могут задействовать несколько ядер процессора в многоядерных архитектурах)S sequential(): возвращает последовательный потокS unordered(): возвращает неупорядоченный поток
От интерфейса BaseStream наследуется ряд интерфейсов, предназначенных для создания конкретных потоков:
Stream<T>: используется для потоков данных, представляющих любой ссылочный типIntStream: используется для потоков с типом данных intDoubleStream: используется для потоков с типом данных doubleLongStream: используется для потоков с типом данных long
При работе с потоками, которые представляют определенный примитивный тип - double, int, long проще использовать интерфейсы DoubleStream, IntStream, LongStream. Но в большинстве случаев, как правило, работа происходит с более сложными данными, для которых предназначен интерфейс Stream<T>. Рассмотрим некоторые его методы:
boolean allMatch(Predicate<? super T> predicate): возвращает true, если все элементы потока удовлетворяют условию в предикате. Терминальная операцияboolean anyMatch(Predicate<? super T> predicate): возвращает true, если хоть один элемент потока удовлетворяют условию в предикате. Терминальная операция<R,A> R collect(Collector<? super T,A,R> collector): добавляет элементы в неизменяемый контейнер с типом R. T представляет тип данных из вызывающего потока, а A - тип данных в контейнере. Терминальная операцияlong count(): возвращает количество элементов в потоке. Терминальная операция.Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b): объединяет два потока. Промежуточная операцияStream<T> distinct(): возвращает поток, в котором имеются только уникальные данные с типом T. Промежуточная операцияStream<T> dropWhile(Predicate<? super T> predicate): пропускает элементы, которые соответствуют условию в predicate, пока не попадется элемент, который не соответствует условию. Выбранные элементы возвращаются в виде потока. Промежуточная операция.Stream<T> filter(Predicate<? super T> predicate): фильтрует элементы в соответствии с условием в предикате. Промежуточная операцияOptional<T> findFirst(): возвращает первый элемент из потока. Терминальная операцияOptional<T> findAny(): возвращает первый попавшийся элемент из потока. Терминальная операцияvoid forEach(Consumer<? super T> action): для каждого элемента выполняется действие action. Терминальная операцияStream<T> limit(long maxSize): оставляет в потоке только maxSize элементов. Промежуточная операцияOptional<T> max(Comparator<? super T> comparator): возвращает максимальный элемент из потока. Для сравнения элементов применяется компаратор comparator. Терминальная операцияOptional<T> min(Comparator<? super T> comparator): возвращает минимальный элемент из потока. Для сравнения элементов применяется компаратор comparator. Терминальная операция<R> Stream<R> map(Function<? super T,? extends R> mapper): преобразует элементы типа T в элементы типа R и возвращает поток с элементами R. Промежуточная операция<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper): позволяет преобразовать элемент типа T в несколько элементов типа R и возвращает поток с элементами R. Промежуточная операцияboolean noneMatch(Predicate<? super T> predicate): возвращает true, если ни один из элементов в потоке не удовлетворяет условию в предикате. Терминальная операцияStream<T> skip(long n): возвращает поток, в котором отсутствуют первые n элементов. Промежуточная операция.Stream<T> sorted(): возвращает отсортированный поток. Промежуточная операция.Stream<T> sorted(Comparator<? super T> comparator): возвращает отсортированный в соответствии с компаратором поток. Промежуточная операция.Stream<T> takeWhile(Predicate<? super T> predicate): выбирает из потока элементы, пока они соответствуют условию в predicate. Выбранные элементы возвращаются в виде потока. Промежуточная операция.Object[] toArray(): возвращает массив из элементов потока. Терминальная операция.
Несмотря на то, что все эти операции позволяют взаимодействовать с потоком как неким набором данных наподобие коллекции, важно понимать отличие коллекций от потоков:
- Потоки не хранят элементы. Элементы, используемые в потоках, могут храниться в коллекции, либо при необходимости могут быть напрямую сгенерированы.
- Операции с потоками не изменяют источника данных. Операции с потоками лишь возвращают новый поток с результатами этих операций.
- Для потоков характерно отложенное выполнение. То есть выполнение всех операций с потоком происходит лишь тогда, когда выполняется терминальная операция и возвращается конкретный результат, а не новый поток.
Для создания потока данных можно применять различные методы. В качестве источника потока мы можем использовать коллекции. В частности, в JDK 8 в интерфейс Collection, который реализуется всеми классами коллекций, были добавлены два метода для работы с потоками:
default Stream<E> stream: возвращается поток данных из коллекцииdefault Stream<E> parallelStream: возвращается параллельный поток данных из коллекции
Пример:
public static void main(String[] args) {
ArrayList<String> cities = new ArrayList<String>();
Collections.addAll(cities, "Париж", "Лондон", "Мадрид");
cities.stream() // получаем поток
.filter(s->s.length()==6) // применяем фильтрацию по длине строки
.forEach(s->System.out.println(s)); // выводим отфильтрованные строки на консоль
}Здесь с помощью вызова cities.stream() получаем поток, который использует данные из списка cities. С помощью каждой промежуточной операции, которая применяется к потоку, мы также можем получить поток с учетом модификаций. Например, мы можем изменить предыдущий пример следующим образом:
ArrayList<String> cities = new ArrayList<String>();
Collections.addAll(cities, "Париж", "Лондон", "Мадрид");
Stream<String> citiesStream = cities.stream(); // получаем поток
citiesStream = citiesStream.filter(s->s.length()==6); // применяем фильтрацию по длине строки
citiesStream.forEach(s->System.out.println(s)); // выводим отфильтрованные строки на консольВажно, что после использования терминальных операций другие терминальные или промежуточные операции к этому же потоку не могут быть применены, поток уже употреблен. Например, в следующем случае мы получим ошибку:
citiesStream.forEach(s->System.out.println(s)); // терминальная операция употребляет поток
long number = citiesStream.count(); // здесь ошибка, так как поток уже употреблен
System.out.println(number);
citiesStream = citiesStream.filter(s->s.length()>5); // тоже нельзя, так как поток уже употребленФактически жизненный цикл потока проходит следующие три стадии:
- Создание потока
- Применение к потоку ряда промежуточных операций
- Применение к потоку терминальной операции и получение результата
Кроме вышерассмотренных методов мы можем использовать еще ряд способов для создания потока данных. Один из таких способов представляет метод Arrays.stream(T[] array), который создает поток данных из массива:
Stream<String> citiesStream = Arrays.stream(new String[]{"Париж", "Лондон", "Мадрид"}) ;
citiesStream.forEach(s->System.out.println(s)); // выводим все элементы массиваДля создания потоков IntStream, DoubleStream, LongStream можно использовать соответствующие перегруженные версии этого метода:
IntStream intStream = Arrays.stream(new int[]{1,2,4,5,7});
intStream.forEach(i->System.out.println(i));
LongStream longStream = Arrays.stream(new long[]{100,250,400,5843787,237});
longStream.forEach(l->System.out.println(l));
DoubleStream doubleStream = Arrays.stream(new double[] {3.4, 6.7, 9.5, 8.2345, 121});
doubleStream.forEach(d->System.out.println(d));И еще один способ создания потока представляет статический метод of(T..values) класса Stream:
Stream<String> citiesStream =Stream.of("Париж", "Лондон", "Мадрид");
citiesStream.forEach(s->System.out.println(s));
// можно передать массив
String[] cities = {"Париж", "Лондон", "Мадрид"};
Stream<String> citiesStream2 =Stream.of(cities);
IntStream intStream = IntStream.of(1,2,4,5,7);
intStream.forEach(i->System.out.println(i));
LongStream longStream = LongStream.of(100,250,400,5843787,237);
longStream.forEach(l->System.out.println(l));
DoubleStream doubleStream = DoubleStream.of(3.4, 6.7, 9.5, 8.2345, 121);
doubleStream.forEach(d->System.out.println(d));Для перебора элементов потока применяется метод forEach(), который представляет терминальную операцию. В качестве параметра он принимает объект Consumer<? super String>, который представляет действие, выполняемое для каждого элемента набора. Например:
Stream<String> citiesStream = Stream.of("Париж", "Лондон", "Мадрид","Берлин", "Брюссель");
citiesStream.forEach(s->System.out.println(s));Фактически это будет аналогично перебору всех элементов в цикле for и выполнению с ними действия, а именно вывод на консоль.
Можно сократить метод forEach():
Stream<String> citiesStream = Stream.of("Париж", "Лондон", "Мадрид","Берлин", "Брюссель");
citiesStream.forEach(System.out::println);Для фильтрации элементов в потоке применяется метод filter(), который представляет промежуточную операцию. Он принимает в качестве параметра некоторое условие в виде объекта Predicate<T> и возвращает новый поток из элементов, которые удовлетворяют этому условию:
Stream<String> citiesStream = Stream.of("Париж", "Лондон", "Мадрид","Берлин", "Брюссель");
citiesStream.filter(s->s.length()==6).forEach(s->System.out.println(s));Здесь условие s.length()==6 возвращает true для тех элементов, длина которых равна 6 символам.
Более сложный пример:
class Phone{
private String name;
private int price;
} Stream<Phone> phoneStream = Stream.of(new Phone("iPhone 6 S", 54000), new Phone("Lumia 950", 45000),
new Phone("Samsung Galaxy S 6", 40000));
phoneStream.filter(p->p.getPrice()<50000).forEach(p->System.out.println(p.getName()));Отображение или маппинг позволяет задать функцию преобразования одного объекта в другой, то есть получить из элемента одного типа элемент другого типа. Для отображения используется метод map, который имеет следующее определение:
<R> Stream<R> map(Function<? super T, ? extends R> mapper)Передаваемая в метод map функция задает преобразование от объектов типа T к типу R. И в результате возвращается новый поток с преобразованными объектами.
Преобразуем тип Phone к String:
Stream<Phone> phoneStream = Stream.of(new Phone("iPhone 6 S", 54000), new Phone("Lumia 950", 45000),
new Phone("Samsung Galaxy S 6", 40000));
phoneStream
.map(p-> p.getName()) // помещаем в поток только названия телефонов
.forEach(s->System.out.println(s));Для преобразования объектов в типы Integer, Long, Double определены специальные методы mapToInt(), mapToLong() и mapToDouble() соответственно.
Плоское отображение выполняется тогда, когда из одного элемента нужно получить несколько. Данную операцию выполняет метод flatMap:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)Из одного объекта Phone нам надо получить два объекта с информацией, например, в виде строки. Для этого применим flatMap:
Stream<Phone> phoneStream = Stream.of(new Phone("iPhone 6 S", 54000), new Phone("Lumia 950", 45000),
new Phone("Samsung Galaxy S 6", 40000));
phoneStream
.flatMap(p->Stream.of(
String.format("название: %s цена без скидки: %d", p.getName(), p.getPrice()),
String.format("название: %s цена со скидкой: %d", p.getName(), p.getPrice() - (int)(p.getPrice()*0.1))
))
.forEach(s->System.out.println(s));Коллекции, на основе которых нередко создаются потоки, уже имеют специальные методы для сортировки содержимого. Однако класс Stream также включает возможность сортировки. Такую сортировку мы можем задействовать, когда у нас идет набор промежуточных операций с потоком, которые создают новые наборы данных, и нам надо эти наборы отсортировать.
Для простой сортировки по возрастанию применяется метод sorted():
public static void main(String[] args) {
List<String> phones = new ArrayList<String>();
Collections.addAll(phones, "iPhone X", "Nokia 9", "Huawei Nexus 6P",
"Samsung Galaxy S8", "LG G6", "Xiaomi MI6",
"ASUS Zenfone 3", "Sony Xperia Z5", "Meizu Pro 6",
"Pixel 2");
phones.stream()
.filter(p->p.length()<12)
.sorted() // сортировка по возрастанию
.forEach(s->System.out.println(s));
} Если по каким-то причинам не подходит данный вараинт или же объекты, которые сортируются не реализуют интерфейс Comparable, то можно использовать другую версию sorted(), которая в качестве параметра принимает компаратор.
Метод takeWhile() выбирает из потока элементы, пока они соответствуют условию. Если попадается элемент, который не соответствует условию, то метод завершает свою работу. Выбранные элементы возвращаются в виде потока.
public static void main(String[] args) {
Stream<Integer> numbers = Stream.of(-3, -2, -1, 0, 1, 2, 3, -4, -5);
numbers.takeWhile(n -> n < 0)
.forEach(n -> System.out.println(n));
}При этом несмотря на то, что в потоке больше отрицательных чисел, но метод завершает работу, как только обнаружит первое число, которое не соответствует условию. В этом и состоит отличие, например, от метода filter().
Чтобы в данном случае охватить все элементы, которые меньше нуля, поток следует предварительно отсортировать:
Stream<Integer> numbers = Stream.of(-3, -2, -1, 0, 1, 2, 3, -4, -5);
numbers.sorted().takeWhile(n -> n < 0)
.forEach(n -> System.out.println(n));Метод dropWhile() выполняет обратную задачу - он пропускает элементы потока, которые соответствуют условию до тех пор, пока не встретит элемент, который НЕ соответствует условию:
Stream<Integer> numbers = Stream.of(-3, -2, -1, 0, 1, 2, 3, -4, -5);
numbers.sorted().dropWhile(n -> n < 0)
.forEach(n -> System.out.println(n));Статический метод concat() объединяет элементы двух потоков, возвращая объединенный поток:
public static void main(String[] args) {
Stream<String> people1 = Stream.of("Tom", "Bob", "Sam");
Stream<String> people2 = Stream.of("Alice", "Kate", "Sam");
Stream.concat(people1, people2).forEach(n -> System.out.println(n));
}Метод distinct() возвращает только ункальные элементы в виде потока:
Stream<String> people = Stream.of("Tom", "Bob", "Sam", "Tom", "Alice", "Kate", "Sam");
people.distinct().forEach(p -> System.out.println(p));Метод skip(long n) используется для пропуска n элементов. Этот метод возвращает новый поток, в котором пропущены первые n элементов.
Метод limit(long n) применяется для выборки первых n элементов потоков. Этот метод также возвращает модифицированный поток, в котором не более n элементов.
Зачастую эта пара методов используется вместе для создания эффекта постраничной навигации.
Stream<String> phoneStream = Stream.of("iPhone 6 S", "Lumia 950", "Samsung Galaxy S 6", "LG G 4", "Nexus 7");
phoneStream.skip(1)
.limit(2)
.forEach(s->System.out.println(s));В данном случае метод skip пропускает один первый элемент, а метод limit выбирает два следующих элемента.
Вполне может быть, что метод skip может принимать в качестве параметра число большее, чем количество элементов в потоке. В этом случае будут пропущены все элементы, а в результирующем потоке будет 0 элементов.
И если в метод limit передается число, большее, чем количество элементов, то просто выбираются все элементы потока.
Операции сведения представляют терминальные операции, которые возвращают некоторое значение - результат операции.
Метод count() возвращает количество элементов в потоке данных:
public static void main(String[] args) {
ArrayList<String> names = new ArrayList<String>();
names.addAll(Arrays.asList(new String[]{"Tom", "Sam", "Bob", "Alice"}));
System.out.println(names.stream().count()); // 4
// количество элементов с длиной не больше 3 символов
System.out.println(names.stream().filter(n->n.length()<=3).count()); // 3
} Метод findFirst() извлекает из потока первый элемент, а findAny() извлекает случайный объект из потока (нередко так же первый):
ArrayList<String> names = new ArrayList<String>();
names.addAll(Arrays.asList(new String[]{"Tom", "Sam", "Bob", "Alice"}));
Optional<String> first = names.stream().findFirst();
System.out.println(first.get()); // Tom
Optional<String> any = names.stream().findAny();
System.out.println(first.get()); // TomЕще одна группа операций сведения возвращает логическое значение true или false:
boolean allMatch(Predicate<? super T> predicate): возвращает true, если все элементы потока удовлетворяют условию в предикатеboolean anyMatch(Predicate<? super T> predicate): возвращает true, если хоть один элемент потока удовлетворяют условию в предикатеboolean noneMatch(Predicate<? super T> predicate): возвращает true, если ни один из элементов в потоке не удовлетворяет условию в предикате
public static void main(String[] args) {
ArrayList<String> names = new ArrayList<String>();
names.addAll(Arrays.asList(new String[]{"Tom", "Sam", "Bob", "Alice"}));
// есть ли в потоке строка, длина которой больше 3
boolean any = names.stream().anyMatch(s->s.length()>3);
System.out.println(any); // true
// все ли строки имеют длину в 3 символа
boolean all = names.stream().allMatch(s->s.length()==3);
System.out.println(all); // false
// НЕТ ЛИ в потоке строки "Bill". Если нет, то true, если есть, то false
boolean none = names.stream().noneMatch(s->s=="Bill");
System.out.println(none); // true
} Методы min() и max() возвращают соответственно минимальное и максимальное значение. Поскольку данные в потоке могут представлять различные типы, в том числе сложные классы, то в качестве параметра в эти методы передается объект интерфейса Comparator, который указывает, как сравнивать объекты:
Optional<T> min(Comparator<? super T> comparator)
Optional<T> max(Comparator<? super T> comparator)Оба метода возвращают элемент потока (минимальный или максимальный), обернутый в объект Optional.
public static void main(String[] args) {
ArrayList<Integer> numbers = new ArrayList<Integer>();
numbers.addAll(Arrays.asList(new Integer[]{1,2,3,4,5,6,7,8,9}));
Optional<Integer> min = numbers.stream().min(Integer::compare);
Optional<Integer> max = numbers.stream().max(Integer::compare);
System.out.println(min.get()); // 1
System.out.println(max.get()); // 9
} Метод reduce выполняет терминальные операции сведения, возвращая некоторое значение - результат операции. Он имеет следующие формы:
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(T identity, BinaryOperator<T> accumulator)
U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)Первая форма возвращает результат в виде объекта Optional<T>.
public static void main(String[] args) {
Stream<Integer> numbersStream = Stream.of(1,2,3,4,5,6);
Optional<Integer> result = numbersStream.reduce((x,y)->x*y);
System.out.println(result.get()); // 720
} Объект BinaryOperator<T> представляет функцию, которая принимает два элемента и выполняет над ними некоторую операцию, возвращая результат. При этом метод reduce сохраняет результат и затем опять же применяет к этому результату и следующему элементу в наборе бинарную операцию.
Вторая версия метода reduce() принимает два параметра
Первый параметр - T identity - элемент, который предоставляет начальное значение для функции из второго параметра, а также предоставляет значение по умолчанию, если поток не имеет элементов.
Второй параметр - BinaryOperator<T> accumulator, как и первая форма метода reduce, представляет ассоциативную функцию, которая запускается для каждого элемента в потоке и принимает два параметра. Первый параметр представляяет промежуточный результат функции, а второй параметр - следующий элемент в потоке. Фактически код этого метода будет равноценен следующей записи:
T result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;То есть при первом вызове функция accumulator в качестве первого параметра принимает значение identity, а в качестве второго параметра - первый элемент потока. При втором вызове первым параметром служит результат первого вызова функции accumulator, а вторым параметром - второй элемент в потоке и так далее.
Stream<Integer> numberStream = Stream.of(-4, 3, -2, 1);
int identity = 1;
int result = numberStream.reduce(identity, (x,y)->x * y);
System.out.println(result); // 24Ряд операций сведения, такие как min, max, reduce, возвращают объект Optional<T>. Этот объект фактически обертывает результат операции. После выполнения операции с помощью метода get() объекта Optional мы можем получить его значение
public static void main(String[] args) {
ArrayList<Integer> numbers = new ArrayList<Integer>();
numbers.addAll(Arrays.asList(new Integer[]{1,2,3,4,5,6,7,8,9}));
Optional<Integer> min = numbers.stream().min(Integer::compare);
System.out.println(min.get()); // 1
} Если поток не содержит вообще никаких данных, то в этом случае программа выдаст исключение java.util.NoSuchElementException.
Самой простой способ избежать подобной ситуации - это предварительная проверка наличия значения в Optional с помощью метода isPresent(). Он возврашает true, если значение присутствует в Optional, и false, если значение отсутствует:
ArrayList<Integer> numbers = new ArrayList<Integer>();
Optional<Integer> min = numbers.stream().min(Integer::compare);
if(min.isPresent()){
System.out.println(min.get());
}Метод orElse() позволяет определить альтернативное значение, которое будет возвращаться, если Optional не получит из потока какого-нибудь значения:
// пустой список
ArrayList<Integer> numbers = new ArrayList<Integer>();
Optional<Integer> min = numbers.stream().min(Integer::compare);
System.out.println(min.orElse(-1)); // -1
// непустой список
numbers.addAll(Arrays.asList(new Integer[]{4,5,6,7,8,9}));
min = numbers.stream().min(Integer::compare);
System.out.println(min.orElse(-1)); // 4Метод orElseGet() позволяет задать функцию, которая будет возвращать значение по умолчанию:
public static void main(String[] args) {
ArrayList<Integer> numbers = new ArrayList<Integer>();
Optional<Integer> min = numbers.stream().min(Integer::compare);
Random rnd = new Random();
System.out.println(min.orElseGet(()->rnd.nextInt(100)));
} Еще один метод - orElseThrow позволяет сгенерировать исключение, если Optional не содержит значения:
ArrayList<Integer> numbers = new ArrayList<Integer>();
Optional<Integer> min = numbers.stream().min(Integer::compare);
// генеррация исключения IllegalStateException
System.out.println(min.orElseThrow(IllegalStateException::new));Метод ifPresent() определяет действия со значением в Optional, если значение имеется:
ArrayList<Integer> numbers = new ArrayList<Integer>();
numbers.addAll(Arrays.asList(new Integer[]{4,5,6,7,8,9}));
Optional<Integer> min = numbers.stream().min(Integer::compare);
min.ifPresent(v->System.out.println(v)); // 4В метод ifPresent передается функция, которая принимает один параметр - значение из Optional. В данном случае полученное минимальное число выводится на консоль. Но если бы массив numbers был бы пустым, и соответственно Optional не сдержало бы никакого значения, то никакой ошибки бы не было.
Метод ifPresentOrElse() позволяет определить альтернативную логику на случай, если значение в Optional отсутствует:
ArrayList<Integer> numbers = new ArrayList<Integer>();
Optional<Integer> min = numbers.stream().min(Integer::compare);
min.ifPresentOrElse(
v -> System.out.println(v),
() -> System.out.println("Value not found")
);В метод ifPresentOrElse передается две функции. Первая обрабатывает значение в Optional, если оно присутствует. Вторая функция представляет действия, которые выполняются, если значение в Optional отсутствует.
Большинство операций класса Stream, которые модифицируют набор данных, возвращают этот набор в виде потока. Однако бывают ситуации, когда хотелось бы получить данные не в виде потока, а в виде обычной коллекции, например, ArrayList или HashSet. И для этого у класса Stream определен метод collect. Первая версия метода принимает в качестве параметра функцию преобразования к коллекции:
<R,A> R collect(Collector<? super T,A,R> collector)Параметр R представляет тип результата метода, параметр Т - тип элемента в потоке, а параметр А - тип промежуточных накапливаемых данных. В итоге параметр collector представляет функцию преобразования потока в коллекцию.
Эта функция представляет объект Collector, который определен в пакете java.util.stream. Мы можем написать свою реализацию функции, однако Java уже предоставляет ряд встроенных функций, определенных в классе Collectors:
toList(): преобразование к типу ListtoSet(): преобразование к типу SettoMap(): преобразование к типу Map
List<String> phones = new ArrayList<String>();
Collections.addAll(phones, "iPhone 8", "HTC U12", "Huawei Nexus 6P",
"Samsung Galaxy S9", "LG G6", "Xiaomi MI6", "ASUS Zenfone 2",
"Sony Xperia Z5", "Meizu Pro 6", "Lenovo S850");
List<String> filteredPhones = phones.stream()
.filter(s->s.length()<10)
.collect(Collectors.toList());
for(String s : filteredPhones){
System.out.println(s);
} Set<String> filteredPhones = phones.stream()
.filter(s->s.length()<10)
.collect(Collectors.toSet());Вторая форма метода collect имеет три параметра:
<R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner)supplier: создает объект коллекцииaccumulator: добавляет элемент в коллекциюcombiner: бинарная функция, которая объединяет два объекта
Чтобы сгруппировать данные по какому-нибудь признаку, нам надо использовать в связке метод collect() объекта Stream и метод Collectors.groupingBy(). Допустим, у нас есть следующий класс:
class Phone{
private String name;
private String company;
private int price;
} Stream<Phone> phoneStream = Stream.of(new Phone("iPhone X", "Apple", 600),
new Phone("Pixel 2", "Google", 500),
new Phone("iPhone 8", "Apple",450),
new Phone("Galaxy S9", "Samsung", 440),
new Phone("Galaxy S8", "Samsung", 340));
Map<String, List<Phone>> phonesByCompany = phoneStream.collect(
Collectors.groupingBy(Phone::getCompany));
for(Map.Entry<String, List<Phone>> item : phonesByCompany.entrySet()){
System.out.println(item.getKey());
for(Phone phone : item.getValue()){
System.out.println(phone.getName());
}
System.out.println();
} Итак, для создания групп в метод phoneStream.collect() передается вызов функции Collectors.groupingBy(), которая с помощью выражения Phone::getCompany группирует объекты по компании. В итоге будет создан объект Map, в котором ключами являются названия компаний, а значениями - список связанных с компаниями телефонов.
Метод Collectors.partitioningBy() имеет похожее действие, только он делит элементы на группы по принципу, соответствует ли элемент определенному условию.
Map<Boolean, List<Phone>> phonesByCompany = phoneStream.collect(
Collectors.partitioningBy(p->p.getCompany()=="Apple"));
for(Map.Entry<Boolean, List<Phone>> item : phonesByCompany.entrySet()){
System.out.println(item.getKey());
for(Phone phone : item.getValue()){
System.out.println(phone.getName());
}
System.out.println();
}В данном случае с помощью условия p->p.getCompany()=="Apple" мы смотрим, принадлежит ли телефон компании Apple. Если телефон принадлежит этой компании, то он попадает в одну группу, если нет, то в другую.
Метод Collectors.counting применяется в Collectors.groupingBy() для вычисления количества элементов в каждой группе:
Map<String, Long> phonesByCompany = phoneStream.collect(
Collectors.groupingBy(Phone::getCompany, Collectors.counting()));
for(Map.Entry<String, Long> item : phonesByCompany.entrySet()){
System.out.println(item.getKey() + " - " + item.getValue());
}Метод Collectors.summing применяется для подсчета суммы. В зависимости от типа данных, к которым применяется метод, он имеет следующие формы: summingInt(), summingLong(), summingDouble(). Применим этот метод для подсчета стоимости всех смартфонов по компаниям:
Map<String, Integer> phonesByCompany = phoneStream.collect(
Collectors.groupingBy(Phone::getCompany, Collectors.summingInt(Phone::getPrice)));
for(Map.Entry<String, Integer> item : phonesByCompany.entrySet()){
System.out.println(item.getKey() + " - " + item.getValue());
}С помощью выражения Collectors.summingInt(Phone::getPrice)) мы указываем, что для каждой компании будет вычислять совокупная цена всех ее смартфонов. И поскольку вычисляется результат - сумма для значений типа int, то в качестве типа возвращаемой коллекции используется тип Map<String, Integer>
Методы maxBy и minBy применяются для подсчета минимального и максимального значения в каждой группе. В качестве параметра эти методы принимают функцию компаратора, которая нужна для сравнения значений. Например, найдем для каждой компании телефон с минимальной ценой:
Map<String, Optional<Phone>> phonesByCompany = phoneStream.collect(
Collectors.groupingBy(Phone::getCompany,
Collectors.minBy(Comparator.comparing(Phone::getPrice))));
for(Map.Entry<String, Optional<Phone>> item : phonesByCompany.entrySet()){
System.out.println(item.getKey() + " - " + item.getValue().get().getName());
}В качестве возвращаемого значения операции группировки используется объект Map<String, Optional<Phone>>. Опять же поскольку группируем по компаниям, то ключом будет выступать строка, а значением - объект Optional<Phone>.
Методы summarizingInt() / summarizingLong() / summarizingDouble() позволяют объединить в набор значения соответствующих типов:
Map<String, IntSummaryStatistics> priceSummary = phoneStream.collect(
Collectors.groupingBy(Phone::getCompany,
Collectors.summarizingInt(Phone::getPrice)));
for(Map.Entry<String, IntSummaryStatistics> item : priceSummary.entrySet()){
System.out.println(item.getKey() + " - " + item.getValue().getAverage());
}Метод Collectors.summarizingInt(Phone::getPrice)) создает набор, в который помещаются цены для всех телефонов каждой из групп. Данный набор инкапсулируется в объекте IntSummaryStatistics. Соответственно если бы мы применяли методы summarizingLong() или summarizingDouble(), то соответственно бы получали объекты LongSummaryStatistics или DoubleSummaryStatistics.
У этих объектов есть ряд методов, который позволяют выполнить различные атомарные операции над набором:
getAverage(): возвращает среднее значениеgetCount(): возвращает количество элементов в набореgetMax(): возвращает максимальное значениеgetMin(): возвращает минимальное значениеgetSum(): возвращает сумму элементовaccept(): добавляет в набор новый элемент
Метод mapping позволяет дополнительно обработать данные и задать функцию отображения объектов из потока на какой-нибудь другой тип данных.
Map<String, List<String>> phonesByCompany = phoneStream.collect(
Collectors.groupingBy(Phone::getCompany,
Collectors.mapping(Phone::getName, Collectors.toList())));
for(Map.Entry<String, List<String>> item : phonesByCompany.entrySet()){
System.out.println(item.getKey());
for(String name : item.getValue()){
System.out.println(name);
}
}Выражение Collectors.mapping(Phone::getName, Collectors.toList()) указывает, что в группу будут выделятся названия смартфонов, причем группа будет представлять объект List.
Кроме последовательных потоков Stream API поддерживает параллельные потоки. Распараллеливание потоков позволяет задействовать несколько ядер процессора (если целевая машина многоядерная) и тем самым может повысить производительность и ускорить вычисления. В то же время говорить, что применение параллельных потоков на многоядерных машинах однозначно повысит производительность - не совсем корректно. В каждом конкретном случае надо проверять и тестировать.
Чтобы сделать обычный последовательный поток параллельным, надо вызвать у объекта Stream метод parallel. Кроме того, можно также использовать метод parallelStream() интерфейса Collection для создания параллельного потока из коллекции.
В то же время если рабочая машина не является многоядерной, то поток будет выполняться как последовательный.
List<String> people = Arrays.asList("Tom","Bob", "Sam", "Kate", "Tim");
System.out.println("Последовательный поток");
people.stream().filter(p->p.length()==3).forEach(System.out::println);
System.out.println("\nПараллельный поток");
people.parallelStream().filter(p->p.length()==3).forEach(System.out::println);В данном случае сначала для списка people создаем поток и выполняем над ним ряд операций в последовательном режиме. В частности, находим в списке строки, длина которых равна 3 и выводим их на консоль. В этом случае все операции с потоком будут производиться над элементами списка в том порядке, в котоом элементы идут в списке.
Затем с помощью метода people.parallelStream() для списка создается параллельный поток. Причем применяются те же операции, однако теперь порядок, в котором над элементами списка будут производиться операции, не детерминирован.
В случае с параллельным потоком вывод недетерминирован и может отличаться.
Однако не все функции можно без ущерба для точности вычисления перенести с последовательных потоков на параллельные. Прежде всего такие функции должны быть без сохранения состояния и ассоциативными, то есть при выполнении слева направо давать тот же результат, что и при выполнении справа налево, как в случае с произведением чисел.
Фактически применение параллельных потоков сводится к тому, что данные в потоке будут разделены на части, каждая часть обрабатывается на отдельном ядре процессора, и в конце эти части соединяются, и над ними выполняются финальные операции. Рассмотрим некоторые критерии, которые могут повлиять на производительность в параллельных потоках:
- Размер данных. Чем больше данных, тем сложнее сначала разделять данные, а потом их соединять.
- Количество ядер процессора. Теоретически, чем больше ядер в компьютере, тем быстрее программа будет работать. Если на машине одно ядро, нет смысла применять параллельные потоки.
- Чем проще структура данных, с которой работает поток, тем быстрее будут происходить операции. Например, данные из
ArrayListлегко использовать, так как структура данной коллекции предполагает последовательность несвязанных данных. А вот коллекция типаLinkedList- не лучший вариант, так как в последовательном списке все элементы связаны с предыдущими/последующими. И такие данные трудно распараллелить. - Над данными примитивных типов операции будут производиться быстрее, чем над объектами классов
Как правило, элементы передаются в поток в том же порядке, в котором они определены в источнике данных. При работе с параллельными потоками система сохраняет порядок следования элементов. Исключение составляет метод forEach(), который может выводить элементы в произвольном порядке. И чтобы сохранить порядок следования, необходимо применять метод forEachOrdered:
phones.parallelStream()
.sorted()
.forEachOrdered(s->System.out.println(s));Сохранение порядка в параллельных потоках увеличивает издержки при выполнении. Но если нам порядок не важен, то мы можем отключить его сохранение и тем самым увеличить производительность, использовав метод unordered:
phones.parallelStream()
.sorted()
.unordered()
.forEach(s->System.out.println(s));В Java функциональность отдельного потока заключается в классе Thread. И чтобы создать новый поток, нам надо создать объект этого класса. Но все потоки не создаются сами по себе. Когда запускается программа, начинает работать главный поток этой программы. От этого главного потока порождаются все остальные дочерние потоки.
С помощью статического метода Thread.currentThread() мы можем получить текущий поток выполнения:
public static void main(String[] args) {
Thread t = Thread.currentThread(); // получаем главный поток
System.out.println(t.getName()); // main
}По умолчанию именем главного потока будет main.
Для управления потоком класс Thread предоставляет еще ряд методов. Наиболее используемые из них:
getName(): возвращает имя потокаsetName(String name): устанавливает имя потокаgetPriority(): возвращает приоритет потокаsetPriority(int proirity): устанавливает приоритет потока. Приоритет является одним из ключевых факторов для выбора системой потока из кучи потоков для выполнения. В этот метод в качестве параметра передается числовое значение приоритета - от 1 до 10. По умолчанию главному потоку выставляется средний приоритет - 5.isAlive(): возвращает true, если поток активенisInterrupted(): возвращает true, если поток был прерванjoin(): ожидает завершение потокаrun(): определяет точку входа в потокsleep(): приостанавливает поток на заданное количество миллисекундstart(): запускает поток, вызывая его метод run()
Мы можем вывести всю информацию о потоке:
public static void main(String[] args) {
Thread t = Thread.currentThread(); // получаем главный поток
System.out.println(t); // main
}Первое main будет представлять имя потока (что можно получить через t.getName()), второе значение 5 предоставляет приоритет потока (также можно получить через t.getPriority()), и последнее main представляет имя группы потоков, к которому относится текущий - по умолчанию также main (также можно получить через t.getThreadGroup().getName())
Далее мы рассмотрим, как создавать и использовать потоки. Это довольно легко. Однако при создании многопоточного приложения нам следует учитывать ряд обстоятельств, которые негативно могут сказаться на работе приложения.
На некоторых платформах запуск новых потоков может замедлить работу приложения. Что может иметь большое значение, если нам критичная производительность приложения.
Для каждого потока создается свой собственный стек в памяти, куда помещаются все локальные переменные и ряд других данных, связанных с выполнением потока. Соответственно, чем больше потоков создается, тем больше памяти используется. При этом надо помнить, в любой системе размеры используемой памяти ограничены. Кроме того, во многих системах может быть ограничение на количество потоков. Но даже если такого ограничения нет, то в любом случае имеется естественное ограничение в виде максимальной скорости процессора.
Для создания нового потока мы можем создать новый класс, либо наследуя его от класса Thread, либо реализуя в классе интерфейс Runnable.
Создадим свой класс на основе Thread:
class JThread extends Thread {
JThread(String name){
super(name);
}
public void run(){
System.out.printf("%s started... \n", Thread.currentThread().getName());
try{
Thread.sleep(500);
}
catch(InterruptedException e){
System.out.println("Thread has been interrupted");
}
System.out.printf("%s fiished... \n", Thread.currentThread().getName());
}
}
public class Program {
public static void main(String[] args) {
System.out.println("Main thread started...");
new JThread("JThread").start();
System.out.println("Main thread finished...");
}
}Класс потока называется JThread. Предполагается, что в конструктор класса передается имя потока, которое затем передается в конструктор базового класса. В конструктор своего класса потока мы можем передать различные данные, но главное, чтобы в нем вызывался конструктор базового класса Thread, в который передается имя потока.
И также в JThread переопределяется метод run(), код которого собственно и будет представлять весь тот код, который выполняется в потоке.
В методе main для запуска потока JThread у него вызывается метод start(), после чего начинается выполнение того кода, который определен в методе run:
new JThread("JThread").start();Здесь в методе main в конструктор JThread передается произвольное название потока, и затем вызывается метод start(). По сути этот метод как раз и вызывает переопределенный метод run() класса JThread.
Обратите внимание, что главный поток завершает работу раньше, чем порожденный им дочерний поток JThread.
Аналогично созданию одного потока мы можем запускать сразу несколько потоков:
public static void main(String[] args) {
System.out.println("Main thread started...");
for(int i=1; i < 6; i++)
new JThread("JThread " + i).start();
System.out.println("Main thread finished...");
}При запуске потоков в примерах выше Main thread завершался до дочернего потока. Как правило, более распространенной ситуацией является случай, когда Main thread завершается самым последним. Для этого надо применить метод join(). В этом случае текущий поток будет ожидать завершения потока, для которого вызван метод join:
public static void main(String[] args) {
System.out.println("Main thread started...");
JThread t= new JThread("JThread ");
t.start();
try{
t.join();
}
catch(InterruptedException e){
System.out.printf("%s has been interrupted", t.getName());
}
System.out.println("Main thread finished...");
}Метод join() заставляет вызвавший поток (в данном случае Main thread) ожидать завершения вызываемого потока, для которого и применяется метод join (в данном случае JThread).
Если в программе используется несколько дочерних потоков, и надо, чтобы Main thread завершался после дочерних, то для каждого дочернего потока надо вызвать метод join.
Другой способ определения потока представляет реализация интерфейса Runnable. Этот интерфейс имеет один метод run:
interface Runnable{
void run();
}В методе run() собственно определяется весь тот код, который выполняется при запуске потока.
После определения объекта Runnable он передается в один из конструкторов класса Thread:
Thread(Runnable runnable, String threadName)Для реализации интерфейса определим следующий класс MyThread:
class MyThread implements Runnable {
public void run(){
System.out.printf("%s started... \n", Thread.currentThread().getName());
try{
Thread.sleep(500);
}
catch(InterruptedException e){
System.out.println("Thread has been interrupted");
}
System.out.printf("%s finished... \n", Thread.currentThread().getName());
}
}
public class Program {
public static void main(String[] args) {
System.out.println("Main thread started...");
Thread myThread = new Thread(new MyThread(),"MyThread");
myThread.start();
System.out.println("Main thread finished...");
}
}Реализация интерфейса Runnable во многом аналогична переопределению класса Thread. Также в методе run определяется простейший код, который усыпляет поток на 500 миллисекунд.
В методе main вызывается конструктор Thread, в который передается объект MyThread. И чтобы запустить поток, вызывается метод start().
Поскольку Runnable фактически представляет функциональный интерфейс, который определяет один метод, то объект этого интерфейса мы можем представить в виде лямбда-выражения:
public class Program {
public static void main(String[] args) {
System.out.println("Main thread started...");
Runnable r = ()->{
System.out.printf("%s started... \n", Thread.currentThread().getName());
try{
Thread.sleep(500);
}
catch(InterruptedException e){
System.out.println("Thread has been interrupted");
}
System.out.printf("%s finished... \n", Thread.currentThread().getName());
};
Thread myThread = new Thread(r,"MyThread");
myThread.start();
System.out.println("Main thread finished...");
}
}Примеры потоков ранее представляли поток как последовательный набор операций. После выполнения последней операции завершался и поток. Однако нередко имеет место и другая организация потока в виде бесконечного цикла. Например, поток сервера в бесконечном цикле прослушивает определенный порт на предмет получения данных. И в этом случае мы также можем предусмотреть механизм завершения потока.
Распространенный способ завершения потока представляет опрос логической переменной. И если она равна, например, false, то поток завершает бесконечный цикл и заканчивает свое выполнение.
Определим следующий класс потока:
class MyThread implements Runnable {
private boolean isActive;
void disable(){
isActive=false;
}
MyThread(){
isActive = true;
}
public void run(){
System.out.printf("%s started... \n", Thread.currentThread().getName());
int counter=1; // счетчик циклов
while(isActive){
System.out.println("Loop " + counter++);
try{
Thread.sleep(400);
}
catch(InterruptedException e){
System.out.println("Thread has been interrupted");
}
}
System.out.printf("%s finished... \n", Thread.currentThread().getName());
}
}Переменная isActive указывает на активность потока. С помощью метода disable() мы можем сбросить состояние этой переменной.
Теперь используем этот класс:
public static void main(String[] args) {
System.out.println("Main thread started...");
MyThread myThread = new MyThread();
new Thread(myThread,"MyThread").start();
try{
Thread.sleep(1100);
myThread.disable();
Thread.sleep(1000);
}
catch(InterruptedException e){
System.out.println("Thread has been interrupted");
}
System.out.println("Main thread finished...");
}Итак, вначале запускается дочерний поток: new Thread(myThread,"MyThread").start(). Затем на 1100 миллисекунд останавливаем Main thread и потом вызываем метод myThread.disable(), который переключает в потоке флаг isActive. И дочерний поток завершается.
Еще один способ вызова завершения или прерывания потока представляет метод interrupt(). Вызов этого метода устанавливает у потока статус, что он прерван. Сам метод возвращает true, если поток может быть прерван, в ином случае возвращается false.
При этом сам вызов этого метода НЕ завершает поток, он только устанавливает статус: в частности, метод isInterrupted() класса Thread будет возвращать значение true. Мы можем проверить значение возвращаемое данным методом и прозвести некоторые действия. Например:
class JThread extends Thread {
JThread(String name){
super(name);
}
public void run(){
System.out.printf("%s started... \n", Thread.currentThread().getName());
int counter=1; // счетчик циклов
while(!isInterrupted()){
System.out.println("Loop " + counter++);
}
System.out.printf("%s finished... \n", Thread.currentThread().getName());
}
}
public class Program {
public static void main(String[] args) {
System.out.println("Main thread started...");
JThread t = new JThread("JThread");
t.start();
try{
Thread.sleep(150);
t.interrupt();
Thread.sleep(150);
}
catch(InterruptedException e){
System.out.println("Thread has been interrupted");
}
System.out.println("Main thread finished...");
}
}В классе, который унаследован от Thread, мы можем получить статус текущего потока с помощью метода isInterrupted(). И пока этот метод возвращает false, мы можем выполнять цикл. А после того, как будет вызван метод interrupt, isInterrupted() возвратит true, и соответственно произойдет выход из цикла.
Если основная функциональность заключена в классе, который реализует интерфейс Runnable, то там можно проверять статус потока с помощью метода Thread.currentThread().isInterrupted():
class MyThread implements Runnable {
public void run(){
System.out.printf("%s started... \n", Thread.currentThread().getName());
int counter=1; // счетчик циклов
while(!Thread.currentThread().isInterrupted()){
System.out.println("Loop " + counter++);
}
System.out.printf("%s finished... \n", Thread.currentThread().getName());
}
}
public class Program {
public static void main(String[] args) {
System.out.println("Main thread started...");
MyThread myThread = new MyThread();
Thread t = new Thread(myThread,"MyThread");
t.start();
try{
Thread.sleep(150);
t.interrupt();
Thread.sleep(150);
}
catch(InterruptedException e){
System.out.println("Thread has been interrupted");
}
System.out.println("Main thread finished...");
}
}Однако при получении статуса потока с помощью метода isInterrupted() следует учитывать, что если мы обрабатываем в цикле исключение InterruptedException в блоке catch, то при перехвате исключения статус потока автоматически сбрасывается, и после этого isInterrupted будет возвращать false.
Например, добавим в цикл потока задержку с помощью метода sleep:
public void run(){
System.out.printf("%s started... \n", Thread.currentThread().getName());
int counter=1; // счетчик циклов
while(!isInterrupted()){
System.out.println("Loop " + counter++);
try{
Thread.sleep(100);
}
catch(InterruptedException e){
System.out.println(getName() + " has been interrupted");
System.out.println(isInterrupted()); // false
interrupt(); // повторно сбрасываем состояние
}
}
System.out.printf("%s finished... \n", Thread.currentThread().getName());
}Когда поток вызовет метод interrupt, метод sleep сгенерирует исключение InterruptedException, и управление перейдет к блоку catch. Но если мы проверим статус потока, то увидим, что метод isInterrupted возвращает false. Как вариант, в этом случае мы можем повторно прервать текущий поток, опять же вызвав метод interrupt(). Тогда при новой итерации цикла while метода isInterrupted возвратит true, и поизойдет выход из цикла.
Либо мы можем сразу же в блоке catch выйти из цикла с помощью break:
while(!isInterrupted()){
System.out.println("Loop " + counter++);
try{
Thread.sleep(100);
}
catch(InterruptedException e){
System.out.println(getName() + " has been interrupted");
break; // выход из цикла
}
}Если бесконечный цикл помещен в конструкцию try...catch, то достаточно обработать InterruptedException:
public void run(){
System.out.printf("%s started... \n", Thread.currentThread().getName());
int counter=1; // счетчик циклов
try{
while(!isInterrupted()){
System.out.println("Loop " + counter++);
Thread.sleep(100);
}
}
catch(InterruptedException e){
System.out.println(getName() + " has been interrupted");
}
System.out.printf("%s finished... \n", Thread.currentThread().getName());
}При работе потоки нередко обращаются к каким-то общим ресурсам, которые определены вне потока, например, обращение к какому-то файлу. Если одновременно несколько потоков обратятся к общему ресурсу, то результаты выполнения программы могут быть неожиданными и даже непредсказуемыми. Например, определим следующий код:
public class Program {
public static void main(String[] args) {
CommonResource commonResource= new CommonResource();
for (int i = 1; i < 6; i++){
Thread t = new Thread(new CountThread(commonResource));
t.setName("Thread "+ i);
t.start();
}
}
}
class CommonResource{
int x=0;
}
class CountThread implements Runnable{
CommonResource res;
CountThread(CommonResource res){
this.res=res;
}
public void run(){
res.x=1;
for (int i = 1; i < 5; i++){
System.out.printf("%s %d \n", Thread.currentThread().getName(), res.x);
res.x++;
try{
Thread.sleep(100);
}
catch(InterruptedException e){}
}
}
}Здесь определен класс CommonResource, который представляет общий ресурс и в котором определено одно целочисленное поле x.
Этот ресурс используется классом потока CountThread. Этот класс просто увеличивает в цикле значение x на единицу. Причем при входе в поток значение x=1:
res.x=1;То есть в итоге мы ожидаем, что после выполнения цикла res.x будет равно 4.
В главном классе программы запускается пять потоков. То есть мы ожидаем, что каждый поток будет увеличивать res.x с 1 до 4 и так пять раз.
То есть пока один поток не окончил работу с полем res.x, с ним начинает работать другой поток.
Чтобы избежать подобной ситуации, надо синхронизировать потоки. Одним из способов синхронизации является использование ключевого слова synchronized. Этот оператор предваряет блок кода или метод, который подлежит синхронизации. Для его применения изменим класс CountThread:
class CountThread implements Runnable{
CommonResource res;
CountThread(CommonResource res){
this.res=res;
}
public void run(){
synchronized(res){
res.x=1;
for (int i = 1; i < 5; i++){
System.out.printf("%s %d \n", Thread.currentThread().getName(), res.x);
res.x++;
try{
Thread.sleep(100);
}
catch(InterruptedException e){}
}
}
}
}При создании синхронизированного блока кода после оператора synchronized идет объект-заглушка: synchronized(res). Причем в качестве объекта может использоваться только объект какого-нибудь класса, но не примитивного типа.
Каждый объект в Java имеет ассоциированный с ним монитор. Монитор представляет своего рода инструмент для управления доступа к объекту. Когда выполнение кода доходит до оператора synchronized, монитор объекта res блокируется, и на время его блокировки монопольный доступ к блоку кода имеет только один поток, который и произвел блокировку. После окончания работы блока кода, монитор объекта res освобождается и становится доступным для других потоков.
После освобождения монитора его захватывает другой поток, а все остальные потоки продолжают ожидать его освобождения.
При применении оператора synchronized к методу пока этот метод не завершит выполнение, монопольный доступ имеет только один поток - первый, который начал его выполнение. Для применения synchronized к методу, изменим классы программы:
public class Program {
public static void main(String[] args) {
CommonResource commonResource= new CommonResource();
for (int i = 1; i < 6; i++){
Thread t = new Thread(new CountThread(commonResource));
t.setName("Thread "+ i);
t.start();
}
}
}
class CommonResource{
int x;
synchronized void increment(){
x=1;
for (int i = 1; i < 5; i++){
System.out.printf("%s %d \n", Thread.currentThread().getName(), x);
x++;
try{
Thread.sleep(100);
}
catch(InterruptedException e){}
}
}
}
class CountThread implements Runnable{
CommonResource res;
CountThread(CommonResource res){
this.res=res;
}
public void run(){
res.increment();
}
}Результат работы в данном случае будет аналогичен примеру выше с блоком synchronized. Здесь опять в дело вступает монитор объекта CommonResource - общего объекта для всех потоков. Поэтому синхронизированным объявляется не метод run() в классе CountThread, а метод increment класса CommonResource. Когда первый поток начинает выполнение метода increment, он захватывает монитор объекта CommonResource. А все потоки также продолжают ожидать его освобождения.
Иногда при взаимодействии потоков встает вопрос о извещении одних потоков о действиях других. Например, действия одного потока зависят от результата действий другого потока, и надо как-то известить один поток, что второй поток произвел некую работу. И для подобных ситуаций у класса Object определено ряд методов:
wait(): освобождает монитор и переводит вызывающий поток в состояние ожидания до тех пор, пока другой поток не вызовет методnotify()notify(): продолжает работу потока, у которого ранее был вызван методwait()notifyAll(): возобновляет работу всех потоков, у которых ранее был вызван методwait()
Все эти методы вызываются только из синхронизированного контекста - синхронизированного блока или метода.
Рассмотрим, как мы можем использовать эти методы. Возьмем стандартную задачу - "Производитель-Потребитель" ("Producer-Consumer"): пока производитель не произвел продукт, потребитель не может его купить. Пусть производитель должен произвести 5 товаров, соответственно потребитель должен их все купить. Но при этом одновременно на складе может находиться не более 3 товаров. Для решения этой задачи задействуем методы wait() и notify():
public class Program {
public static void main(String[] args) {
Store store=new Store();
Producer producer = new Producer(store);
Consumer consumer = new Consumer(store);
new Thread(producer).start();
new Thread(consumer).start();
}
}
// Класс Магазин, хранящий произведенные товары
class Store{
private int product=0;
public synchronized void get() {
while (product<1) {
try {
wait();
}
catch (InterruptedException e) {
}
}
product--;
System.out.println("Покупатель купил 1 товар");
System.out.println("Товаров на складе: " + product);
notify();
}
public synchronized void put() {
while (product>=3) {
try {
wait();
}
catch (InterruptedException e) {
}
}
product++;
System.out.println("Производитель добавил 1 товар");
System.out.println("Товаров на складе: " + product);
notify();
}
}
// класс Производитель
class Producer implements Runnable{
Store store;
Producer(Store store){
this.store=store;
}
public void run(){
for (int i = 1; i < 6; i++) {
store.put();
}
}
}
// Класс Потребитель
class Consumer implements Runnable{
Store store;
Consumer(Store store){
this.store=store;
}
public void run(){
for (int i = 1; i < 6; i++) {
store.get();
}
}
}Итак, здесь определен класс магазина, потребителя и покупателя. Производитель в методе run() добавляет в объект Store с помощью его метода put() 6 товаров. Потребитель в методе run() в цикле обращается к методу get объекта Store для получения этих товаров. Оба метода Store - put и get являются синхронизированными.
Для отслеживания наличия товаров в классе Store проверяем значение переменной product. По умолчанию товара нет, поэтому переменная равна 0. Метод get() - получение товара должен срабатывать только при наличии хотя бы одного товара. Поэтому в методе get проверяем, отсутствует ли товар:
while (product<1)Если товар отсутсвует, вызывается метод wait(). Этот метод освобождает монитор объекта Store и блокирует выполнение метода get, пока для этого же монитора не будет вызван метод notify().
Когда в методе put() добавляется товар и вызывается notify(), то метод get() получает монитор и выходит из конструкции while (product<1), так как товар добавлен. Затем имитируется получение покупателем товара. Для этого выводится сообщение, и уменьшается значение product: product--. И в конце вызов метода notify() дает сигнал методу put() продолжить работу.
В методе put() работает похожая логика, только теперь метод put() должен срабатывать, если в магазине не более трех товаров. Поэтому в цикле проверяется наличие товара, и если товар уже есть, то освобождаем монитор с помощью wait() и ждем вызова notify() в методе get().
Таким образом, с помощью wait() в методе get() мы ожидаем, когда производитель добавит новый продукт. А после добавления вызываем notify(), как бы говоря, что на складе освободилось одно место, и можно еще добавлять.
А в методе put() с помощью wait() мы ожидаем освобождения места на складе. После того, как место освободится, добавляем товар и через notify() уведомляем покупателя о том, что он может забирать товар.
Семафоры представляют еще одно средство синхронизации для доступа к ресурсу. В Java семафоры представлены классом Semaphore, который располагается в пакете java.util.concurrent.
Для управления доступом к ресурсу семафор использует счетчик, представляющий количество разрешений. Если значение счетчика больше нуля, то поток получает доступ к ресурсу, при этом счетчик уменьшается на единицу. После окончания работы с ресурсом поток освобождает семафор, и счетчик увеличивается на единицу. Если же счетчик равен нулю, то поток блокируется и ждет, пока не получит разрешение от семафора.
Установить количество разрешений для доступа к ресурсу можно с помощью конструкторов класса Semaphore:
Semaphore(int permits)
Semaphore(int permits, boolean fair)Параметр permits указывает на количество допустимых разрешений для доступа к ресурсу. Параметр fair во втором конструкторе позволяет установить очередность получения доступа. Если он равен true, то разрешения будут предоставляться ожидающим потокам в том порядке, в каком они запрашивали доступ. Если же он равен false, то разрешения будут предоставляться в неопределенном порядке.
Для получения разрешения у семафора надо вызвать метод acquire(), который имеет две формы:
void acquire() throws InterruptedException
void acquire(int permits) throws InterruptedExceptionДля получения одного разрешения применяется первый вариант, а для получения нескольких разрешений - второй вариант.
После вызова этого метода пока поток не получит разрешение, он блокируется.
После окончания работы с ресурсом полученное ранее разрешение надо освободить с помощью метода release():
void release()
void release(int permits)Первый вариант метода освобождает одно разрешение, а второй вариант - количество разрешений, указанных в permits.
Используем семафор в простом примере:
public class Program {
public static void main(String[] args) {
Semaphore sem = new Semaphore(1); // 1 разрешение
CommonResource res = new CommonResource();
new Thread(new CountThread(res, sem, "CountThread 1")).start();
new Thread(new CountThread(res, sem, "CountThread 2")).start();
new Thread(new CountThread(res, sem, "CountThread 3")).start();
}
}
class CommonResource{
int x=0;
}
class CountThread implements Runnable{
CommonResource res;
Semaphore sem;
String name;
CountThread(CommonResource res, Semaphore sem, String name){
this.res=res;
this.sem=sem;
this.name=name;
}
public void run(){
try{
System.out.println(name + " ожидает разрешение");
sem.acquire();
res.x=1;
for (int i = 1; i < 5; i++){
System.out.println(this.name + ": " + res.x);
res.x++;
Thread.sleep(100);
}
}
catch(InterruptedException e){System.out.println(e.getMessage());}
System.out.println(name + " освобождает разрешение");
sem.release();
}
}Итак, здесь есть общий ресурс CommonResource с полем x, которое изменяется каждым потоком. Потоки представлены классом CountThread, который получает семафор и выполняет некоторые действия над ресурсом. В основном классе программы эти потоки запускаются.
Класс Exchanger предназначен для обмена данными между потоками. Он является типизированным и типизируется типом данных, которыми потоки должны обмениваться.
Обмен данными производится с помощью единственного метода этого класса exchange():
V exchange(V x) throws InterruptedException
V exchange(V x, long timeout, TimeUnit unit) throws InterruptedException, TimeoutExceptionПараметр x представляет буфер данных для обмена. Вторая форма метода также определяет параметр timeout - время ожидания и unit - тип временных единиц, применяемых для параметра timeout.
public class Program {
public static void main(String[] args) {
Exchanger<String> ex = new Exchanger<String>();
new Thread(new PutThread(ex)).start();
new Thread(new GetThread(ex)).start();
}
}
class PutThread implements Runnable{
Exchanger<String> exchanger;
String message;
PutThread(Exchanger<String> ex){
this.exchanger=ex;
message = "Hello Java!";
}
public void run(){
try{
message=exchanger.exchange(message);
System.out.println("PutThread has received: " + message);
}
catch(InterruptedException ex){
System.out.println(ex.getMessage());
}
}
}
class GetThread implements Runnable{
Exchanger<String> exchanger;
String message;
GetThread(Exchanger<String> ex){
this.exchanger=ex;
message = "Hello World!";
}
public void run(){
try{
message=exchanger.exchange(message);
System.out.println("GetThread has received: " + message);
}
catch(InterruptedException ex){
System.out.println(ex.getMessage());
}
}
} В классе PutThread отправляет в буфер сообщение "Hello Java!":
message=exchanger.exchange(message);Причем в ответ метод exchange возвращает данные, которые отправил в буфер другой поток. То есть происходит обмен данными. Хотя нам необязательно получать данные, мы можем просто их отправить:
exchanger.exchange(message);Логика класса GetThread аналогична - также отправляется сообщение.
Класс Phaser позволяет синхронизировать потоки, представляющие отдельную фазу или стадию выполнения общего действия. Phaser определяет объект синхронизации, который ждет, пока не завершится определенная фаза. Затем Phaser переходит к следующей стадии или фазе и снова ожидает ее завершения.
Для создания объекта Phaser используется один из конструкторов:
Phaser()
Phaser(int parties)
Phaser(Phaser parent)
Phaser(Phaser parent, int parties)Параметр parties указывает на количество участников (грубо говоря, потоков), которые должны выполнять все фазы действия. Первый конструктор создает объект Phaser без каких-либо участников. Второй конструктор регистрирует передаваемое в конструктор количество участников. Третий и четвертый конструкторы также устанавливают родительский объект Phaser.
Основные методы класса Phaser:
int register(): регистрирует участника, который выполняет фазы, и возвращает номер текущей фазы - обычно фаза 0int arrive(): сообщает, что участник завершил фазу, и возвращает номер текущей фазыint arriveAndAwaitAdvance(): аналогичен методу arrive, только при этом заставляет phaser ожидать завершения фазы всеми остальными участникамиint arriveAndDeregister(): сообщает о завершении всех фаз участником и снимает его с регистрации. Возвращает номер текущей фазы или отрицательное число, если синхронизатор Phaser завершил свою работуint getPhase(): возвращает номер текущей фазы
При работае с классом Phaser обычно сначала создается его объект. Далее нам надо зарегистрировать всех участников. Для регистрации для каждоого участника вызывается метод register(), либо можно обойтись и без этого метода, передав нужное количество участников в конструктор Phaser.
Затем каждый участник выполняет некоторый набор действий, составляющих фазу. А синхронизатор Phaser ждет, пока все участники не завершат выполнение фазы. Чтобы сообщить синхронизатору, что фаза завершена, участник должен вызвать метод arrive() или arriveAndAwaitAdvance(). После этого синхронизатор переходит к следующей фазе.
public class Program {
public static void main(String[] args) {
Phaser phaser = new Phaser(1);
new Thread(new PhaseThread(phaser, "PhaseThread 1")).start();
new Thread(new PhaseThread(phaser, "PhaseThread 2")).start();
// ждем завершения фазы 0
int phase = phaser.getPhase();
phaser.arriveAndAwaitAdvance();
System.out.println("Фаза " + phase + " завершена");
// ждем завершения фазы 1
phase = phaser.getPhase();
phaser.arriveAndAwaitAdvance();
System.out.println("Фаза " + phase + " завершена");
// ждем завершения фазы 2
phase = phaser.getPhase();
phaser.arriveAndAwaitAdvance();
System.out.println("Фаза " + phase + " завершена");
phaser.arriveAndDeregister();
}
}
class PhaseThread implements Runnable{
Phaser phaser;
String name;
PhaseThread(Phaser p, String n){
this.phaser=p;
this.name=n;
phaser.register();
}
public void run(){
System.out.println(name + " выполняет фазу " + phaser.getPhase());
phaser.arriveAndAwaitAdvance(); // сообщаем, что первая фаза достигнута
System.out.println(name + " выполняет фазу " + phaser.getPhase());
phaser.arriveAndAwaitAdvance(); // сообщаем, что вторая фаза достигнута
System.out.println(name + " выполняет фазу " + phaser.getPhase());
phaser.arriveAndDeregister(); // сообщаем о завершении фаз и удаляем с регистрации объекты
}
}Итак, здесь у нас фазы выполняются тремя участниками - главным потоком и двумя потоками PhaseThread. Поэтому при создании объекта Phaser ему передается число 1 - главный поток, а в конструкторе PhaseThread вызывается метод register(). Мы в принципе могли бы не использовать метод register, но тогда нам надо было бы указать Phaser phaser = new Phaser(3), так как у нас три участника.
Фаза для каждого участника представляет минимальный примитивный набор действий: для потоков PhaseThread это вывод сообщения, а для главного потока - подсчет текущей фазы с помощью метода getPhase(). При этом отсчет фаз начинается с нуля. Каждый участник завершает выполнение фазы вызовом метода phaser.arriveAndAwaitAdvance(). При вызове этого метода пока последний участник не завершит выполнение текущей фазы, все остальные участники блокируются.
После завершения выполнения последней фазы происходит отмена регистрации всех участников с помощью метода arriveAndDeregister().
В данном случае получается немного путанный вывод. Так, сообщения о выполнении фазы 1 выводится после сообщения об окончании фазы 0. Что связано с многопоточностью - фазы завершились, но в одном потоке еще не выведено сообщение о завершении, тогда как другие потоки уже начали выполнение следующей фазы. В любом случае все это происходит уже после завершения фазы.
Но чтобы было более наглядно, мы можем использовать sleep в потоках:
public void run(){
System.out.println(name + " выполняет фазу " + phaser.getPhase());
phaser.arriveAndAwaitAdvance(); // сообщаем, что первая фаза достигнута
try{
Thread.sleep(200);
}
catch(InterruptedException ex){
System.out.println(ex.getMessage());
}
System.out.println(name + " выполняет фазу " + phaser.getPhase());
phaser.arriveAndAwaitAdvance(); // сообщаем, что вторая фаза достигнута
try{
Thread.sleep(200);
}
catch(InterruptedException ex){
System.out.println(ex.getMessage());
}
System.out.println(name + " выполняет фазу " + phaser.getPhase());
phaser.arriveAndDeregister(); // сообщаем о завершении фаз и удаляем с регистрации объекты
}Для управления доступом к общему ресурсу в качестве альтернативы оператору synchronized мы можем использовать блокировки. Функциональность блокировок заключена в пакете java.util.concurrent.locks.
Вначале поток пытается получить доступ к общему ресурсу. Если он свободен, то на него накладывает блокировку. После завершения работы блокировка с общего ресурса снимается. Если же ресурс не свободен и на него уже наложена блокировка, то поток ожидает, пока эта блокировка не будет снята.
Классы блокировок реализуют интерфейс Lock, который определяет следующие методы:
void lock(): ожидает, пока не будет получена блокировкаvoid lockInterruptibly() throws InterruptedException: ожидает, пока не будет получена блокировка, если поток не прерванboolean tryLock(): пытается получить блокировку, если блокировка получена, то возвращаетtrue. Если блокировка не получена, то возвращаетfalse. В отличие от методаlock()не ожидает получения блокировки, если она недоступнаvoid unlock(): снимает блокировкуCondition newCondition(): возвращает объектCondition, который связан с текущей блокировкой
Организация блокировки в общем случае довольно проста: для получения блокировки вызывается метод lock(), а после окончания работы с общими ресурсами вызывается метод unlock(), который снимает блокировку.
Объект Condition позволяет управлять блокировкой.
Как правило, для работы с блокировками используется класс ReentrantLock из пакета java.util.concurrent.locks. Данный класс реализует интерфейс Lock.
Для примера возьмем код из темы про оператор synchronized и перепишем данный код с использованием заглушки ReentrantLock:
public void run(){
locker.lock(); // устанавливаем блокировку
try{
res.x=1;
for (int i = 1; i < 5; i++){
System.out.printf("%s %d \n", Thread.currentThread().getName(), res.x);
res.x++;
Thread.sleep(100);
}
}
catch(InterruptedException e){
System.out.println(e.getMessage());
}
finally{
locker.unlock(); // снимаем блокировку
}
}
}Здесь также используется общий ресурс CommonResource, для управления которым создается пять потоков. На входе в критическую секцию устанавливается заглушка:
locker.lock();После этого только один поток имеет доступ к критической секции, а остальные потоки ожидают снятия блокировки. В блоке finally после всей окончания основной работы потока эта блокировка снимается. Причем делается это обязательно в блоке finally, так как в случае возникновения ошибки все остальные потоки окажутся заблокированными.
Применение условий в блокировках позволяет добиться контроля над управлением доступом к потокам. Условие блокировки представлет собой объект интерфейса Condition из пакета java.util.concurrent.locks.
Применение объектов Condition во многом аналогично использованию методов wait/notify/notifyAll класса Object. В частности, мы можем использовать следующие методы интерфейса Condition:
await: поток ожидает, пока не будет выполнено некоторое условие и пока другой поток не вызовет методыsignal/signalAll. Во многом аналогичен методуwaitклассаObjectsignal: сигнализирует, что поток, у которого ранее был вызван методawait(), может продолжить работу. Применение аналогично использованию методуnotifyклассаObjectsignalAll: сигнализирует всем потокам, у которых ранее был вызван методawait(), что они могут продолжить работу. Аналогичен методуnotifyAll()классаObject
Эти методы вызываются из блока кода, который попадает под действие блокировки ReentrantLock. Сначала, используя эту блокировку, нам надо получить объект Condition:
ReentrantLock locker = new ReentrantLock();
Condition condition = locker.newCondition();Как правило, сначала проверяется условие доступа. Если соблюдается условие, то поток ожидает, пока условие не изменится:
while (условие)
condition.await();После выполнения всех действий другим потокам подается сигнал об изменении условия:
condition.signalAll();Важно в конце вызвать метод signal/signalAll, чтобы избежать возможности взаимоблокировки потоков.
Для примера возьмем задачу из темы про методы wait/notify и изменим ее, применяя объект Condition.
Итак, у нас есть склад, где могут одновременно быть размещено не более 3 товаров. И производитель должен произвести 5 товаров, а покупатель должен эти товары купить. В то же время покупатель не может купить товар, если на складе нет никаких товаров:
public class Program {
public static void main(String[] args) {
Store store=new Store();
Producer producer = new Producer(store);
Consumer consumer = new Consumer(store);
new Thread(producer).start();
new Thread(consumer).start();
}
}
// Класс Магазин, хранящий произведенные товары
class Store{
private int product=0;
ReentrantLock locker;
Condition condition;
Store(){
locker = new ReentrantLock(); // создаем блокировку
condition = locker.newCondition(); // получаем условие, связанное с блокировкой
}
public void get() {
locker.lock();
try{
// пока нет доступных товаров на складе, ожидаем
while (product<1)
condition.await();
product--;
System.out.println("Покупатель купил 1 товар");
System.out.println("Товаров на складе: " + product);
// сигнализируем
condition.signalAll();
}
catch (InterruptedException e){
System.out.println(e.getMessage());
}
finally{
locker.unlock();
}
}
public void put() {
locker.lock();
try{
// пока на складе 3 товара, ждем освобождения места
while (product>=3)
condition.await();
product++;
System.out.println("Производитель добавил 1 товар");
System.out.println("Товаров на складе: " + product);
// сигнализируем
condition.signalAll();
}
catch (InterruptedException e){
System.out.println(e.getMessage());
}
finally{
locker.unlock();
}
}
}
// класс Производитель
class Producer implements Runnable{
Store store;
Producer(Store store){
this.store=store;
}
public void run(){
for (int i = 1; i < 6; i++) {
store.put();
}
}
}
// Класс Потребитель
class Consumer implements Runnable{
Store store;
Consumer(Store store){
this.store=store;
}
public void run(){
for (int i = 1; i < 6; i++) {
store.get();
}
}
}Lambda-выражения – это анонимные функции (может и не 100% верное определение для Java, но зато привносит некоторую ясность). Проще говоря, это метод без объявления, т.е. без модификаторов доступа, возвращающие значение и имя.
Функциональные интерфейсы (Functional Interface) – это интерфейсы только с одним абстрактным методом, объявленным в нем
Среди новшеств, которые были привнесены в язык Java с выходом JDK 8, особняком стоят лямбда-выражения. Лямбда представляет набор инструкций, которые можно выделить в отдельную переменную и затем многократно вызвать в различных местах программы.
Основу лямбда-выражения составляет лямбда-оператор, который представляет стрелку ->. Этот оператор разделяет лямбда-выражение на две части: левая часть содержит список параметров выражения, а правая собственно представляет тело лямбда-выражения, где выполняются все действия.
Лямбда-выражение не выполняется само по себе, а образует реализацию метода, определенного в функциональном интерфейсе. При этом важно, что функциональный интерфейс должен содержать только один единственный метод без реализации.
Рассмотрим пример:
public class LambdaApp {
public static void main(String[] args) {
Operationable operation;
operation = (x,y)->x+y;
int result = operation.calculate(10, 20);
System.out.println(result); //30
}
}
interface Operationable{
int calculate(int x, int y);
}В роли функционального интерфейса выступает интерфейс Operationable, в котором определен один метод без реализации - метод calculate. Данный метод принимает два параметра - целых числа, и возвращает некоторое целое число.
По факту лямбда-выражения являются в некотором роде сокращенной формой внутренних анонимных классов, которые ранее применялись в Java. В частности, предыдущий пример мы можем переписать следующим образом:
public class LambdaApp {
public static void main(String[] args) {
Operationable op = new Operationable(){
public int calculate(int x, int y){
return x + y;
}
};
int z = op.calculate(20, 10);
System.out.println(z); // 30
}
}
interface Operationable{
int calculate(int x, int y);
}Чтобы объявить и использовать лямбда-выражение, основная программа разбивается на ряд этапов:
- Определение ссылки на функциональный интерфейс:
Operationable operation;- Создание лямбда-выражения:
operation = (x,y)->x+y;Причем параметры лямбда-выражения соответствуют параметрам единственного метода интерфейса Operationable, а результат соответствует возвращаемому результату метода интерфейса. При этом нам не надо использовать ключевое слово return для возврата результата из лямбда-выражения.
Так, в методе интерфейса оба параметра представляют тип int, значит, в теле лямбда-выражения мы можем применить к ним сложение. Результат сложения также представляет тип int, объект которого возвращается методом интерфейса.
3.Использование лямбда-выражения в виде вызова метода интерфейса:
int result = operation.calculate(10, 20);Так как в лямбда-выражении определена операция сложения параметров, результатом метода будет сумма чисел 10 и 20.
При этом для одного функционального интерфейса мы можем определить множество лямбда-выражений. Например:
Operationable operation1 = (int x, int y)-> x + y;
Operationable operation2 = (int x, int y)-> x - y;
Operationable operation3 = (int x, int y)-> x * y;
System.out.println(operation1.calculate(20, 10)); //30
System.out.println(operation2.calculate(20, 10)); //10
System.out.println(operation3.calculate(20, 10)); //200Одним из ключевых моментов в использовании лямбд является отложенное выполнение (deferred execution). То есть мы определяем в одном месте программы лямбда-выражение и затем можем его вызывать при необходимости неопределенное количество раз в различных частях программы. Отложенное выполнение может потребоваться, к примеру, в следующих случаях:
- Выполнение кода отдельном потоке
- Выполнение одного и того же кода несколько раз
- Выполнение кода в результате какого-то события
- Выполнение кода только в том случае, когда он действительно необходим и если он необходим
Параметры лямбда-выражения должны соответствовать по типу параметрам метода из функционального интерфейса. При написании самого лямбда-выражения тип параметров писать необязательно, хотя в принципе это можно сделать, например:
operation = (int x, int y)->x+y;Если метод не принимает никаких параметров, то пишутся пустые скобки, например:
()-> 30 + 20;Если метод принимает только один параметр, то скобки можно опустить:
n-> n * n;Выше мы рассмотрели лямбда-выражения, которые возвращают определенное значение. Но также могут быть и терминальные лямбды, которые не возвращают никакого значения. Например:
interface Printable{
void print(String s);
}
public class LambdaApp {
public static void main(String[] args) {
Printable printer = s->System.out.println(s);
printer.print("Hello Java!");
}
}Лямбда-выражение может использовать переменные, которые объявлены во вне в более общей области видимости - на уровне класса или метода, в котором лямбда-выражение определено. Однако в зависимости от того, как и где определены переменные, могут различаться способы их использования в лямбдах. Рассмотрим первый пример - использования переменных уровня класса:
public class LambdaApp {
static int x = 10;
static int y = 20;
public static void main(String[] args) {
Operation op = ()->{
x=30;
return x+y;
};
System.out.println(op.calculate()); // 50
System.out.println(x); // 30 - значение x изменилось
}
}
interface Operation{
int calculate();
}Переменные x и y объявлены на уровне класса, и в лямбда-выражении мы их можем получить и даже изменить. Так, в данном случае после выполнения выражения изменяется значение переменной x.
Теперь рассмотрим другой пример - локальные переменные на уровне метода:
public static void main(String[] args) {
int n=70;
int m=30;
Operation op = ()->{
//n=100; - так нельзя сделать
return m+n;
};
// n=100; - так тоже нельзя
System.out.println(op.calculate()); // 100
} Локальные переменные уровня метода мы также можем использовать в лямбдах, но изменять их значение нельзя. Если мы попробуем это сделать, то среда разработки (Netbeans) может нам высветить ошибку и то, что такую переменную надо пометить с помощью ключевого слова final, то есть сделать константой: final int n=70;. Однако это необязательно.
Более того, мы не сможем изменить значение переменной, которая используется в лямбда-выражении, вне этого выражения. То есть даже если такая переменная не объявлена как константа, по сути она является константой.
Существуют два типа лямбда-выражений: однострочное выражение и блок кода. Примеры однострочных выражений демонстрировались выше. Блочные выражения обрамляются фигурными скобками. В блочных лямбда-выражениях можно использовать внутренние вложенные блоки, циклы, конструкции if, switch, создавать переменные и т.д. Если блочное лямбда-выражение должно возвращать значение, то явным образом применяется оператор return:
Operationable operation = (int x, int y)-> {
if(y==0)
return 0;
else
return x/y;
};
System.out.println(operation.calculate(20, 10)); //2
System.out.println(operation.calculate(20, 0)); //0Функциональный интерфейс может быть обобщенным, однако в лямбда-выражении использование обобщений не допускается. В этом случае нам надо типизировать объект интерфейса определенным типом, который потом будет применяться в лямбда-выражении. Например:
public class LambdaApp {
public static void main(String[] args) {
Operationable<Integer> operation1 = (x, y)-> x + y;
Operationable<String> operation2 = (x, y) -> x + y;
System.out.println(operation1.calculate(20, 10)); //30
System.out.println(operation2.calculate("20", "10")); //2010
}
}
interface Operationable<T>{
T calculate(T x, T y);
}Таким образом, при объявлении лямбда-выражения ему уже известно, какой тип параметры будут представлять и какой тип они будут возвращать.
Одним из преимуществ лямбд в java является то, что их можно передавать в качестве параметров в методы. Рассмотрим пример:
public class LambdaApp {
public static void main(String[] args) {
Expression func = (n)-> n%2==0;
int[] nums = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
System.out.println(sum(nums, func)); // 20
}
private static int sum (int[] numbers, Expression func)
{
int result = 0;
for(int i : numbers)
{
if (func.isEqual(i))
result += i;
}
return result;
}
}
interface Expression{
boolean isEqual(int n);
}Функциональный интерфейс Expression определяет метод isEqual(), который возвращает true, если в отношении числа n действует какое-нибудь равенство.
В основном классе программы определяется метод sum(), который вычисляет сумму всех элементов массива, соответствующих некоторому условию. А само условие передается через параметр Expression func. Причем на момент написания метода sum мы можем абсолютно не знать, какое именно условие будет использоваться. Само же условие определяется в виде лямбда-выражения:
Expression func = (n)-> n%2==0;То есть в данном случае все числа должны быть четными или остаток от их деления на 2 должен быть равен 0. Затем это лямбда-выражение передается в вызов метода sum.
При этом можно не определять переменную интерфейса, а сразу передать в метод лямбда-выражение:
int[] nums = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int x = sum(nums, (n)-> n > 5); // сумма чисел, которые больше 5
System.out.println(x); // 30Начиная с JDK 8 в Java можно в качестве параметра в метод передавать ссылку на другой метод. В принципе данный способ аналогичен передаче в метод лямбда-выражения.
Ссылка на метод передается в виде имя_класса::имя_статического_метода (если метод статический) или объект_класса::имя_метода (если метод нестатический). Рассмотрим на примере:
// функциональный интерфейс
interface Expression{
boolean isEqual(int n);
}
// класс, в котором определены методы
class ExpressionHelper{
static boolean isEven(int n){
return n%2 == 0;
}
static boolean isPositive(int n){
return n > 0;
}
}
public class LambdaApp {
public static void main(String[] args) {
int[] nums = { -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5};
System.out.println(sum(nums, ExpressionHelper::isEven));
Expression expr = ExpressionHelper::isPositive;
System.out.println(sum(nums, expr));
}
private static int sum (int[] numbers, Expression func)
{
int result = 0;
for(int i : numbers)
{
if (func.isEqual(i))
result += i;
}
return result;
}
}Здесь также определен функциональный интерфейс Expression, который имеет один метод. Кроме того, определен класс ExpressionHelper, который содержит два статических метода. В принципе их можно было определить и в основном классе программы, но я вынес их в отдельный класс.
В основном классе программы LambdaApp определен метод sum(), который возвращает сумму элементов массива, соответствующих некоторому условию. Условие передается в виде объекта функционального интерфейса Expression.
В методе main два раза вызываем метод sum, передавая в него один и тот же массив чисел, но разные условия. Первый вызов метода sum:
System.out.println(sum(nums, ExpressionHelper::isEven));На место второго параметра передается ExpressionHelper::isEven, то есть ссылка на статический метод isEven() класса ExpressionHelper. При этом методы, на которые идет ссылка, должны совпадать по параметрам и результату с методом функционального интерфейса.
При втором вызове метода sum отдельно создается объект Expression, который затем передается в метод:
Expression expr = ExpressionHelper::isPositive;
System.out.println(sum(nums, expr));Использование ссылок на методы в качестве параметров аналогично использованию лямбда-выражений.
Если нам надо вызвать нестатические методы, то в ссылке вместо имени класса применяется имя объекта этого класса:
interface Expression{
boolean isEqual(int n);
}
class ExpressionHelper{
boolean isEven(int n){
return n%2 == 0;
}
}
public class LambdaApp {
public static void main(String[] args) {
int[] nums = { -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5};
ExpressionHelper exprHelper = new ExpressionHelper();
System.out.println(sum(nums, exprHelper::isEven)); // 0
}
private static int sum (int[] numbers, Expression func)
{
int result = 0;
for(int i : numbers)
{
if (func.isEqual(i))
result += i;
}
return result;
}
}Подобным образом мы можем использовать конструкторы: название_класса::new. Например:
public class LambdaApp {
public static void main(String[] args) {
UserBuilder userBuilder = User::new;
User user = userBuilder.create("Tom");
System.out.println(user.getName());
}
}
interface UserBuilder{
User create(String name);
}
class User{
private String name;
String getName(){
return name;
}
User(String n){
this.name=n;
}
}При использовании конструкторов методы функциональных интерфейсов должны принимать тот же список параметров, что и конструкторы класса, и должны возвращать объект данного класса.
Также метод в Java может возвращать лямбда-выражение. Рассмотрим следующий пример:
interface Operation{
int execute(int x, int y);
}
public class LambdaApp {
public static void main(String[] args) {
Operation func = action(1);
int a = func.execute(6, 5);
System.out.println(a); // 11
int b = action(2).execute(8, 2);
System.out.println(b); // 6
}
private static Operation action(int number){
switch(number){
case 1: return (x, y) -> x + y;
case 2: return (x, y) -> x - y;
case 3: return (x, y) -> x * y;
default: return (x,y) -> 0;
}
}
}В данном случае определен функциональный интерфейс Operation, в котором метод execute принимает два значения типа int и возвращает значение типа int.
Метод action принимает в качестве параметра число и в зависимости от его значения возвращает то или иное лямбда-выражение. Оно может представлять либо сложение, либо вычитание, либо умножение, либо просто возвращает 0. Стоит учитывать, что формально возвращаемым типом метода action является интерфейс Operation, а возвращаемое лямбда-выражение должно соответствовать этому интерфейсу.
В методе main мы можем вызвать этот метод action. Например, сначала получить его результат - лямбда-выражение, которое присваивается переменной Operation. А затем через метод execute выполнить это лямбда-выражение:
Operation func = action(1);
int a = func.execute(6, 5);
System.out.println(a); // 11Либо можно сразу получить и тут же выполнить лямбда-выражение:
int b = action(2).execute(8, 2);
System.out.println(b); // 6В JDK 8 вместе с самой функциональностью лямбда-выражений также было добавлено некоторое количество встроенных функциональных интерфейсов, которые мы можем использовать в различных ситуациях и в различные API в рамках JDK 8. В частности, ряд далее рассматриваемых интерфейсов широко применяется в Stream API - новом прикладном интерфейсе для работы с данными. Рассмотрим основные из этих интерфейсов:
Predicate<T>Consumer<T>Function<T,R>Supplier<T>UnaryOperator<T>BinaryOperator<T>
Функциональный интерфейс Predicate<T> проверяет соблюдение некоторого условия. Если оно соблюдается, то возвращается значение true. В качестве параметра лямбда-выражение принимает объект типа T:
public interface Predicate<T> {
boolean test(T t);
}Например:
public class LambdaApp {
public static void main(String[] args) {
Predicate<Integer> isPositive = x -> x > 0;
System.out.println(isPositive.test(5)); // true
System.out.println(isPositive.test(-7)); // false
}
}Consumer<T> выполняет некоторое действие над объектом типа T, при этом ничего не возвращая:
public interface Consumer<T> {
void accept(T t);
}Например:
public class LambdaApp {
public static void main(String[] args) {
Consumer<Integer> printer = x-> System.out.printf("%d долларов \n", x);
printer.accept(600); // 600 долларов
}
}Функциональный интерфейс Function<T,R> представляет функцию перехода от объекта типа T к объекту типа R:
public interface Function<T, R> {
R apply(T t);
}Например:
public class LambdaApp {
public static void main(String[] args) {
Function<Integer, String> convert = x-> String.valueOf(x) + " долларов";
System.out.println(convert.apply(5)); // 5 долларов
}
}Supplier<T> не принимает никаких аргументов, но должен возвращать объект типа T:
public interface Supplier<T> {
T get();
} public class LambdaApp {
public static void main(String[] args) {
Supplier<User> userFactory = ()->{
Scanner in = new Scanner(System.in);
System.out.println("Введите имя: ");
String name = in.nextLine();
return new User(name);
};
User user1 = userFactory.get();
User user2 = userFactory.get();
System.out.println("Имя user1: " + user1.getName());
System.out.println("Имя user2: " + user2.getName());
}
}
class User{
private String name;
String getName(){
return name;
}
User(String n){
this.name=n;
}
}UnaryOperator<T> принимает в качестве параметра объект типа T, выполняет над ними операции и возвращает результат операций в виде объекта типа T:
public interface UnaryOperator<T> {
T apply(T t);
}Например:
public class LambdaApp {
public static void main(String[] args) {
UnaryOperator<Integer> square = x -> x*x;
System.out.println(square.apply(5)); // 25
}
}BinaryOperator<T> принимает в качестве параметра два объекта типа T, выполняет над ними бинарную операцию и возвращает ее результат также в виде объекта типа T:
public interface BinaryOperator<T> {
T apply(T t1, T t2);
}Например:
public class LambdaApp {
public static void main(String[] args) {
BinaryOperator<Integer> multiply = (x, y) -> x*y;
System.out.println(multiply.apply(3, 5)); // 15
System.out.println(multiply.apply(10, -2)); // -20
}
}Spring - фреймворк с открытым исходным кодом, предназначеный для упрощения разработки enterprise-приложений. Одним из главным преимуществом Spring является его слоистая архитектура, позволяющая вам самим определять какие компоненты будут использованы в вашем приложении. Модули Spring построены на базе основного контейнера, который определяет создание, конфигурация и менеджмент бинов.
Основные фраймворки внутри Springa:
- Основной контейнер (Beans, Core, Context, SpEL) - предоставляет основной функционал Spring, управляющий процессом создания и настройки компонентов приложения. Beans отвечает за BeanFactory которая является сложной реализацией паттерна Фабрика (GoF). Модуль Core обеспечивает ключевые части фреймворка, включая свойства IoC и DI. Context построен на основе Beans и Core и позволяет получить доступ к любому объекту, который определён в настройках. Ключевым элементом модуля Context является интерфейс ApplicationContext. Модуль SpEL обеспечивает мощный язык выражений для манипулирования объектами во время исполнения. В нем есть тернатрные, арефметические, логические операторы. Может получить доступ к элементам коллекций.
- Spring AOP (AOP, Aspects) - отвечает за интеграцию аспектно-ориентированного программирования во фреймворк. Spring AOP обеспечивает сервис управления транзакциями для Spring-приложения.
- Spring Data — дополнительный удобный механизм для взаимодействия с сущностями базы данных, организации их в репозитории, извлечение данных, изменение, в каких то случаях для этого будет достаточно объявить интерфейс и метод в нем, без имплементации. Например с использованием JPA. Состоит из JDBC, ORM, OXM, JMS и модуля Transatcions. JDBC обеспечивает абстрактный слой JDBC и избавляет разработчика от необходимости вручную прописывать монотонный код, связанный с соединением с БД. ORM обеспечивает интеграцию с такими популярными ORM, как Hibernate, JDO, JPA и т.д. Модуль OXM отвечает за связь Объект/XML – XMLBeans, JAXB и т.д. Модуль JMS (Java Messaging Service) отвечает за создание, передачу и получение сообщений. Transactions поддерживает управление транзакциями для классов, которые реализуют определённые методы.
- Spring Web module (Web, Servlet, Portlet, Struts) - Модуль Web обеспечивает такие функции, как загрузка файлов и т.д. Web-MVC содержит реализацию Spring MVC для веб-приложений. Web-Socket обеспечивает поддержку связи между клиентом и сервером, используя Web-Socket-ы в веб-приложениях. Web-Portlet обеспечивает реализацию MVC с среде портлетов.
- Spring MVC framework - реализация паттерна MVC для построения Web-приложений.
- Spring Integration - обеспечивает легкий обмен сообщениями в приложениях на базе Spring и поддерживает интеграцию с внешними системами через декларативные адаптеры. Эти адаптеры обеспечивают более высокий уровень абстракции по сравнению с поддержкой Spring для удаленного взаимодействия, обмена сообщениями и планирования. Основная цель Spring Integration - предоставить простую модель для построения корпоративных решений по интеграции, сохраняя при этом разделение задач, что важно для создания поддерживаемого, тестируемого кода.
- Spring Cloud - инструменты для создания сложных топологий для потоковой и пакетной передачи данных.
- Spring Batch - предоставляет многократно используемые функции, которые необходимы для обработки больших объемов записей, включая ведение журнала / трассировку, управление транзакциями, статистику обработки заданий, перезапуск заданий, пропуск и управление ресурсами. Он также предоставляет более продвинутые технические услуги и функции, которые позволят выполнять пакетные задания чрезвычайно большого объема и с высокой производительностью благодаря методам оптимизации и разделения. Простые и сложные пакетные задания большого объема могут использовать платформу с высокой степенью масштабируемости для обработки значительных объемов информации.
- Spring Kafka - Проект Spring for Apache Kafka (spring-kafka) применяет основные концепции Spring для разработки решений для обмена сообщениями на основе Kafka. Он предоставляет «шаблон» в качестве высокоуровневой абстракции для отправки сообщений. Он также обеспечивает поддержку управляемых сообщениями POJO с @KafkaListener аннотациями и «контейнером слушателя». Эти библиотеки способствуют использованию инъекций зависимостей и декларативных. Во всех этих случаях вы увидите сходство с поддержкой JMS в Spring Framework и поддержкой RabbitMQ в Spring AMQP.
- Spring Security - Фреймворк аутентификации и авторизации: конфигурируемый инструментарий процессов аутентификации и авторизации, поддерживающий много популярных и ставших индустриальными стандартами протоколов, инструментов, практик.
- Тестирование - каркас, поддерживающий классы для написания модульных и интеграционных тестов.
Spring Framework обеспечивает решения многих задач, с которыми сталкиваются Java-разработчики и организации, которые хотят создать информационную систему, основанную на платформе Java. Из-за широкой функциональности трудно определить наиболее значимые структурные элементы, из которых он состоит. Spring Framework не всецело связан с платформой Java Enterprise, несмотря на его масштабную интеграцию с ней, что является важной причиной его популярности.
Spring Framework, вероятно, наиболее известен как источник расширений (features), нужных для эффективной разработки сложных бизнес-приложений вне тяжеловесных программных моделей, которые исторически были доминирующими в промышленности. Ещё одно его достоинство в том, что он ввел ранее неиспользуемые функциональные возможности в сегодняшние господствующие методы разработки, даже вне платформы Java. Этот фреймворк предлагает последовательную модель и делает её применимой к большинству типов приложений, которые уже созданы на основе платформы Java. Считается, что Spring Framework реализует модель разработки, основанную на лучших стандартах индустрии, и делает её доступной во многих областях Java.
Таким образом к достоинствам Spring можно отнести:
- Относительная легкость в изучении и применении фреймворка в разработке и поддержке приложения.
- Внедрение зависимостей (DI) и инверсия управления (IoC) позволяют писать независимые друг от друга компоненты, что дает преимущества в командной разработке, переносимости модулей и т.д..
- Spring IoC контейнер управляет жизненным циклом Spring Bean и настраивается наподобие JNDI lookup (поиска).
- Проект Spring содержит в себе множество подпроектов, которые затрагивают важные части создания софта, такие как вебсервисы, веб программирование, работа с базами данных, загрузка файлов, обработка ошибок и многое другое. Всё это настраивается в едином формате и упрощает поддержку приложения.
Container создаёт объекты, связывает их вместе, настраивает и управляет ими от создания до момента уничтожения. Spring Container получает инструкции какие объекты инстанциировать и как их конфигурировать через метаданные: XML, Аннотации или Java код .
Spring BeanFactory Container Это самый простой контейнер, который обеспечивает базовую поддержку DI и который основан на интерфейсе org.springframework.beans.factory.BeanFactory. Такие интерфейсы, как BeanFactoryAware и DisposableBean всё ещё присутствуют в Spring для обеспечения обратной совместимости.
Бины создаются при вызове метода getBean().
Наиболее часто используемая реализация интерфейса BeanFactory – XmlBeanFactory. XmlBeanFactory получает метаданные из конфигурационного XML файла и использует его для создания настроенного приложения или системы. BeanFactory обычно используется тогда, когда ресурсы ограничены (мобильные устройства). Поэтому, если ресурсы не сильно ограничены, то лучше использовать ApplicationContext.
Spring ApplicationContext Container ApplicationContext является более сложным и более продвинутым Spring Container-ом. Наследует BeanFactory и так же загружает бины, связывает их вместе и конфигурирует их определённым образом. Но кроме этого, ApplicationContext обладает дополнительной функциональностью: общий механизм работы с ресурсами, распознание текстовых сообщений из файлов настройки и отображение событий, которые происходят в приложении различными способами. Этот контейнер определяется интерфейсом org.springframework.context.ApplicationContext.
Бины создаются при "поднятии" контекста все сразу. Если не указана стратегия инициализации.
Чаще всего используются следующие реализации AppicationContext:
- FileSystemXmlApplicationContext - Загружает данные о бине из XML файла. При использовании этой реализации в конструкторе необходимо указать полный адрес конфигурационного файла.
- ClassPathXmlApplicationContext - Этот контейнер также получает данные о бине из XML файла. Но в отличие от FileSystemApplicationContext, в этом случае необходимо указать относительный адрес конфигурационного файла (CLASSPATH).
- AnnotationConfigApplicationContext — метаданные конфигурируются с помощью аннотаций прямо на классах.
- WebApplicationContext — для веб-приложений
- GenericGroovyApplicationContext - эта конфигурация работает по сути так же, как и Xml, только с Groovy-файлами. К тому же, GroovyApplicationContext нормально работает и с Xml-файлом. Принимает на вход строку с конфигурацией контекста. Чтением контекста в данном случае занимается класс GroovyBeanDefinitionReader.
Groovy — объектно-ориентированный язык программирования разработанный для платформы Java как альтернатива языку Java с возможностями Python, Ruby и Smalltalk. Groovy использует Java-подобный синтаксис с динамической компиляцией в JVM байт-код и напрямую работает с другим Java кодом и библиотеками. Язык может использоваться в любом Java проекте или как скриптовый язык.
При этом мы можем указать несколько файлов конфигурации Spring.
Отличия ApplicationContext и BeanFactory
- ApplicationContext загружает все бины при запуске, а BeanFactory - по требованию.
- ApplicationContext расширяет BeanFactory и предоставляет функции, которые подходят для корпоративных приложений: a. поддержка внедрения зависимостей на основе аннотаций; b. удобный доступ к MessageSource (для использования в интернационализации); c. публикация ApplicationEvent - для бинов, реализующих интерфейс ApplicationListener, с помощью интерфейса ApplicationEventPublisher; d. простая интеграция с функциями Spring AOP.
- ApplicationContext поддерживает автоматическую регистрацию BeanPostProcessor и BeanFactoryPostProcessor. Поэтому всегда желательно использовать ApplicationContext, потому что Spring 2.0 (и выше) интенсивно использует BeanPostProcessor.
- ApplicationContext поддерживает практически все типы scope для бинов, а BeanFactory поддерживает только два - Singleton и Prototype.
- В BeanFactory не будут работать транзакции и Spring AOP. Это может привести к путанице, потому что конфигурация с виду будет корректной
- Контейнер создается при запуске приложения
- Контейнер считывает конфигурационные данные (парсинг XML, JavaConfig)
- Из конфигурационных данных создается описание бинов (BeanDafinition) BeanDefenitionReader
- BeanFactoryPostProcessors обрабатывают описание бина
- Контейнер создает бины используя их описание
- Бины инициализируются — значения свойств и зависимости внедряются в бин (настраиваются)
- BeanPostProcessor запускают методы обратного вызова(callback methods)
- Приложение запущено и работает
- Инициализируется закрытие приложения
- Контейнер закрывается
- Вызываются callback methods
Бин (bean) — это не что иное, как самый обычный объект. Разница лишь в том, что бинами принято называть те объекты, которые управляются Spring-ом и живут внутри его DI-контейнера.
По умолчанию бин задается как синглтон в Spring. Таким образом все публичные переменные класса могут быть изменены одновременно из разных мест, а значит бин - не потокобезопасен. Однако поменяв область действия бина на request, prototype, session он станет потокобезопасным, но это скажется на производительности.
Конфигурационный файл спринг определяет все бины, которые будут инициализированы в Spring Context. При создании экземпляра Spring ApplicationContext будет прочитан конфигурационный xml файл и выполнены указанные в нем необходимые инициализации. Отдельно от базовой конфигурации, в файле могут содержаться описание перехватчиков (interceptors), view resolvers, настройки локализации и др.
Определение бина содержит метаданные конфигурации, которые необходимы управляющему контейнеру для получения следующей информации: Как создать бин; Информацию о жизненном цикле бина; Зависимости бина.
В Spring Framework существуют такие свойства, определяющие бины:
- class - Этот атрибут является обязательным и указывает конкретный класс Java-приложения, который будет использоваться для создания бина.
- name - Уникальный идентификатор бина. В случае конфигурации с помощью xml-файла, вы можете использовать свойство “id” и/или “name” для идентификации бина. Атрибут name также может принимать массив String, что позволяет использовать несколько имен. Первый элемент массива будет являться именем и уникальным идентификатором бина, а остальные будут его псевдонимами.
- scope - Это свойство определяет область видимости создаваемых объектов.
- singleton - Определяет один единственный бин для каждого контейнера Spring IoC (используется по умолчанию);
- prototype - контейнер Spring IoC создаёт новый экземпляр бина на каждый полученный запрос т.е. иметь любое количество экземпляров бина;
- request - Создаётся один экземпляр бина на каждый HTTP запрос. Касается исключительно ApplicationContext;
- session - Создаётся один экземпляр бина на каждую HTTP сессию. Касается исключительно ApplicationContext;
- web soccet - Создаётся один экземпляр бина для определенного сокета.
- application - Создаётся один экземпляр бина для жизненного цикла бина. Похоже на синглтон, но когда бобы ограничены областью приложения, значения, однажды установленное в applicationScopedBean, будет сохранено для всех последующих запросов, сеансов и даже для другого приложения сервлета, которое будет обращаться к этому Бобу, при условии, что оно выполняется в том же ServletContext. В то время как одноэлементные бобы ограничены только одним контекстом приложения.
- constructor-arg - Определяет конструктор, использующийся для внедрения зависимости. Более подробно – далее.
- properties - Определяет свойства внедрения зависимости. Более подробно рассмотрим далее.
- initialization method - Здесь определяется метод инициализации бина
- destruction method - Метод уничтожения бина, который будет использоваться при уничтожении контейнера, содержащего бин.
- autowiring mode - Определяет режим автоматического связывания при внедрении зависимости. Более подробно рассмотрим далее.
- lazy-initialization mode - Режим ленивой инициализации даёт контейнеру IoC команду создавать экземпляр бина при первом запросе, а не при запуске приложения.
Классы, аннотированные @Configuration, проксируются через CGLIB. Классы @Component или обычные классы не проксируются и не перехватывают вызовы методов с аннотациями @Bean, что означает, что вызовы не будут маршрутизироваться через контейнер и каждый раз будет возвращаться новый экземпляр бина.
CGLIB (Code Generation Library) - Это библиотека инструментария байтов, используемая во многих средах Java, таких как Hibernate или Spring. Инструментарий байт-кода позволяет манипулировать или создавать классы после фазы компиляции программы.
- Загрузка описаний бинов, создание графа зависимостей(между бинами)
- Создание и запуск BeanFactoryPostProcessors
- Создание бинов
- Spring внедряет значения и зависимости в свойства бина
- Если бин реализует метод setBeanName() из интерфейса NameBeanAware, то ID бина передается в метод
- Если бин реализует BeanFactoryAware, то Spring устанавливает ссылку на bean factory через setBeanFactory() из этого интерфейса.
- Если бин реализует интерфейс ApplicationContextAware, то Spring устанавливает ссылку на ApplicationContext через setApplicationContext().
- BeanPostProcessor это специальный интерфейс, и Spring позволяет бинам имплементировать этот интерфейс. Реализуя метод postProcessBeforeInitialization(), можно изменить экземпляр бина перед его(бина) инициализацией(установка свойств и т.п.)
- Если определены методы обратного вызова, то Spring вызывает их. Например, это метод, аннотированный @PostConstruct или метод initMethod из аннотации @Bean.
- Теперь бин готов к использованию. Его можно получить с помощью метода ApplicationContext#getBean().
- После того как контекст будет закрыт(метод close() из ApplicationContext), бин уничтожается.
- Если в бине есть метод, аннотированный @PreDestroy, то перед уничтожением вызовется этот метод. Если бин имплементирует DisposibleBean, то Spring вызовет метод destroy(), чтобы очистить ресурсы или убить процессы в приложении. Если в аннотации @Bean определен метод destroyMethod, то вызовется и он.
Интерфейс BeanPostProcessor позволяют разработчику самому имплементировать некоторые методы бинов перед инициализацией и после уничтожения экземпляров бина. Имеется возможность настраивать несколько имлементаций BeanPostProcessor и определить порядок их выполнения. Данный интерфейс работает с экземплярами бинов, а это означает, что Spring IoC создаёт экземпляр бина, а затем BeanPostProcessor с ним работает. ApplicationContext автоматически обнаруживает любые бины, с реализацией BeanPostProcessor и помечает их как “post-processors” для того, чтобы создать их определённым способом.
Интерфейс BeanPostProcessor имеет всего два метода: postProcessBeforeInitialization и postProcessAfterInitialization
- Парсирование конфигурации и создание BeanDefinition
Цель первого этапа — это создание всех BeanDefinition. Объекты BeanDefinition — это набор метаданных будущего бина, макет, по которому нужно будет создавать бин в случае необходимости. То есть для каждого бина создается свой объект BeanDefinition, в котором хранится описание того, как создавать и управлять этим конкретным бином. Проще говоря, сколько бинов в программе - столько и объектов BeanDefinition, их описывающих.
BeanDefinition содержат (среди прочего) следующие метаданные:
- Имя класса с указанием пакета: обычно это фактический класс бина.
- Элементы поведенческой конфигурации бина, которые определяют, как бин должен вести себя в контейнере (scope, обратные вызовы жизненного цикла и т.д.).
- Ссылки на другие bean-компоненты, которые необходимы для его работы. Эти ссылки также называются зависимостями.
- Другие параметры конфигурации для установки во вновь созданном объекте - например, ограничение размера пула или количество соединений, используемых в бине, который управляет пулом соединений.
Эти метаданные преобразуются в набор свойств, которые составляют каждое BeanDefinition. В следующей таблице описаны эти свойства:
При конфигурации через аннотации с указанием пакета для сканирования или JavaConfig используется класс AnnotationConfigApplicationContext. Регистрируются все классы с @Configuration для дальнейшего парсирования, затем регистрируется специальный BeanFactoryPostProcessor, а именно BeanDefinitionRegistryPostProcessor, который при помощи класса ConfigurationClassParser парсирует JavaConfig, загружает описания бинов (BeanDefinition), создаёт граф зависимостей (между бинами) и создаёт:
Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256); в которой хранятся все описания бинов, обнаруженных в ходе парсинга конфигурации.
- Настройка созданных BeanDefinition
После первого этапа у нас имеется коллекция Map, в которой хранятся BeanDefinition-ы. BeanFactoryPostProcessor-ы на этапе создания BeanDefinition-ов могут их настроить как нам необходимо. BeanFactoryPostProcessor-ы могут даже настроить саму BeanFactory ещё до того, как она начнет работу по созданию бинов. В интерфейсе BeanFactoryPostProcessor всего один метод:
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}- Создание кастомных FactoryBean (только для XML-конфигурации)
- Создание экземпляров бинов
Сначала BeanFactory из коллекции Map с объектами BeanDefinition достаёт те из них, из которых создаёт все BeanPostProcessor-ы, необходимые для настройки обычных бинов. Создаются экземпляры бинов через BeanFactory на основе ранее созданных BeanDefinition
- Настройка созданных бинов
На данном этапе бины уже созданы, мы можем лишь их донастроить.
Интерфейс BeanPostProcessor позволяет вклиниться в процесс настройки наших бинов до того, как они попадут в контейнер. ApplicationContext автоматически обнаруживает любые бины с реализацией BeanPostProcessor и помечает их как “post-processors” для того, чтобы создать их определенным способом. Например, в Spring есть реализации BeanPostProcessor-ов, которые обрабатывают аннотации @Autowired, @Inject, @Value и @Resource.
Интерфейс несет в себе два метода: postProcessBeforeInitialization(Object bean, String beanName) и postProcessAfterInitialization(Object bean, String beanName). У обоих методов параметры абсолютно одинаковые. Разница только в порядке их вызова. Первый вызывается до init-метода, второй - после.
Как правило, BeanPostProcessor-ы, которые заполняют бины через маркерные интерфейсы или тому подобное, реализовывают метод postProcessBeforeInitialization (Object bean, String beanName), тогда как BeanPostProcessor-ы, которые оборачивают бины в прокси, обычно реализуют postProcessAfterInitialization (Object bean, String beanName).
Прокси — это класс-декорация над бином. Например, мы хотим добавить логику нашему бину, но джава-код уже скомпилирован, поэтому нам нужно на лету сгенерировать новый класс. Этим классом мы должны заменить оригинальный класс так, чтобы никто не заметил подмены.
Есть два варианта создания этого класса:
- либо он должен наследоваться от оригинального класса (CGLIB) и переопределять его методы, добавляя нужную логику;
- либо он должен имплементировать те же самые интерфейсы, что и первый класс(Dynamic Proxy).
По конвенции спринга, если какой-то из BeanPostProcessor-ов меняет что-то в классе, то он должен это делать на этапе postProcessAfterInitialization(). Таким образом мы уверены, что initMethod у данного бина, работает на оригинальный метод, до того, как на него накрутился прокси.
Хронология событий:
- Сначала сработает метод postProcessBeforeInitialization() всех имеющихся BeanPostProcessor-ов.
- Затем, при наличии, будет вызван метод, аннотированный @PostConstruct.
- Если бин имплементирует InitializingBean, то Spring вызовет метод afterPropertiesSet() - не рекомендуется к использованию как устаревший.
- При наличии, будет вызван метод, указанный в параметре initMethod аннотации @Bean.
- В конце бины пройдут через postProcessAfterInitialization (Object bean, String beanName). Именно на данном этапе создаются прокси стандартными BeanPostProcessor-ами. Затем отработают наши кастомные BeanPostProcessor-ы и применят нашу логику к прокси-объектам. После чего все бины окажутся в контейнере, который будет обязательно обновлен методом refresh().
- Но даже после этого мы можем донастроить наши бины ApplicationListener-ами.
- Бины готовы к использованию
Их можно получить с помощью метода ApplicationContext#getBean().
- Закрытие контекста
Когда контекст закрывается (метод close() из ApplicationContext), бин уничтожается.
Если в бине есть метод, аннотированный @PreDestroy, то перед уничтожением вызовется этот метод.
Если бин имплементирует DisposibleBean, то Spring вызовет метод destroy() - не рекомендуется к использованию как устаревший.
Если в аннотации @Bean определен метод destroyMethod, то будет вызван и он.
@PostConstruct
Spring вызывает методы, аннотированные @PostConstruct, только один раз, сразу после инициализации свойств компонента. За данную аннотацию отвечает один из BeanPostProcessor-ов.
Метод, аннотированный @PostConstruct, может иметь любой уровень доступа, может иметь любой тип возвращаемого значения (хотя тип возвращаемого значения игнорируется Spring-ом), метод не должен принимать аргументы. Он также может быть статическим, но преимуществ такого использования метода нет, т.к. доступ у него будет только к статическим полям/методам бина, и в таком случае смысл его использования для настройки бина пропадает.
Одним из примеров использования @PostConstruct является заполнение базы данных. Например, во время разработки нам может потребоваться создать пользователей по умолчанию.
@PreDestroy
Метод, аннотированный @PreDestroy, запускается только один раз, непосредственно перед тем, как Spring удаляет наш компонент из контекста приложения.
Как и в случае с @PostConstruct, методы, аннотированные @PreDestroy, могут иметь любой уровень доступа, но не могут быть статическими.
Целью этого метода может быть освобождение ресурсов или выполнение любых других задач очистки до уничтожения бина, например, закрытие соединения с базой данных.
- XML конфигурация
<bean name="myBean" class="project.spring.beans.MyBean"></bean>- Java code
@configuration
@ComponentScan(value="project.spring.main")
public class MyConfiguration [
@Bean
public MyService getService() {
return new MyService();
}
}Для извлечения бина:
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(MyConfiguration.class);
MyService service = ctx.getBean(MyService.class);- Annotation - внутри кода используются аннотации @Component, @Service, @Repository, @Controller для указания классов как бины.
Если в классе будет статический метод, то при инициализации впервую очередь создастся статический метод (из-за особенностей статических полей), а потом уже Bean, который "навешивается" на статический метод.
При этом Spring не позволяет внедрять бины напрямую в статические поля, нужно создать нестатический сеттер-метод
@Component
public class TestDataInit {
@Autowired
private static OrderItemService orderItemService; //будет null
}
@Component
public class TestDataInit {
private static OrderItemService orderItemService;
@Autowired
public void setOrderItemService(OrderItemService orderItemService) {
TestDataInit.orderItemService = orderItemService;
}
}Центральной частью Spring является подход Inversion of Control, который позволяет конфигурировать и управлять объектами Java с помощью рефлексии. Вместо ручного внедрения зависимостей, фреймворк забирает ответственность за это посредством контейнера. Контейнер отвечает за управление жизненным циклом объекта: создание объектов, вызов методов инициализации и конфигурирование объектов путём связывания их между собой.
Объекты, создаваемые контейнером, также называются управляемыми объектами (beans). Обычно, конфигурирование контейнера, осуществляется путём внедрения аннотаций (начиная с 5 версии J2SE), но также, есть возможность, по старинке, загрузить XML-файлы, содержащие определение bean’ов и предоставляющие информацию, необходимую для создания bean’ов.
Плюсы такого подхода:
- отделение выполнения задачи от ее реализации;
- легкое переключение между различными реализациями;
- большая модульность программы;
- более легкое тестирование программы путем изоляции компонента или проверки его зависимостей и обеспечения взаимодействия компонентов через контракты.
Объекты могут быть получены одним из двух способов:
Dependency Lookup Поиск зависимости — шаблон проектирования, в котором вызывающий объект запрашивает у объекта-контейнера экземпляр объекта с определённым именем или определённого типа.
Dependency Injection Внедрение зависимости — шаблон проектирования, в котором контейнер передает экземпляры объектов по их имени другим объектам с помощью конструктора, свойства или фабричного метода.
Под DI понимают то Dependency Inversion (инверсию зависимостей, то есть попытки не делать жестких связей между вашими модулями/классами, где один класс напрямую завязан на другой), то Dependency Injection (внедрение зависимостей, это когда объекты котиков создаете не вы в main-е и потом передаете их в свои методы, а за вас их создает спринг, а вы ему просто говорите что-то типа "хочу сюда получить котика" и он вам его передает в ваш метод). Мы чаще будем сталкиваться в дальнейших статьях со вторым.
Внедрение зависимости (Dependency injection, DI) — процесс, когда один объект реализует свой функционал через другой. Является специфичной формой «инверсии управления» (Inversion of control, IoC), когда она применяется к управлению зависимостями. В полном соответствии с принципом единой обязанности объект отдаёт заботу о построении требуемых ему зависимостей внешнему, специально предназначенному для этого общему механизму.
К достоинствам применения DI можно отнести:
- Сокращение объема связующего кода. Одним из самых больших плюсов DI является возможность значительного сокращения объема кода, который должен быть написан для связывания вместе различных компонентов приложения. Зачастую этот код очень прост — при создании зависимости должен создаваться новый экземпляр соответствующего объекта.
- Упрощенная конфигурация приложения. За счет применения DI процесс конфигурирования приложения значительно упрощается. Для конфигурирования классов, которые могут быть внедрены в другие классы, можно использовать аннотации или XML-файлы.
- Возможность управления общими зависимостями в единственном репозитории. При традиционном подходе к управлению зависимостями в общих службах, к которым относятся, например, подключение к источнику данных, транзакция, удаленные службы и т.п., вы создаете экземпляры (или получаете их из определенных фабричных классов) зависимостей там, где они нужны — внутри зависимого класса. Это приводит к распространению зависимостей по множеству классов в приложении, что может затруднить их изменение. В случае использования DI вся информация об общих зависимостях содержится в единственном репозитории (в Spring есть возможность хранить эту информацию в XML-файлах или Java классах), что существенно упрощает управление зависимостями и снижает количество возможных ошибок.
- Улучшенная возможность тестирования. Когда классы проектируются для DI, становится возможной простая замена зависимостей. Это особенно полезно при тестировании приложения.
- Стимулирование качественных проектных решений для приложений. Вообще говоря, проектирование для DI означает проектирование с использованием интерфейсов. Используя Spring, вы получаете в свое распоряжение целый ряд средств DI и можете сосредоточиться на построении логики приложения, а не на поддерживающей DI платформе.
Реализация DI в Spring основана на двух ключевых концепциях Java — компонентах JavaBean и интерфейсах. При использовании Spring в качестве поставщика DI вы получаете гибкость определения конфигурации зависимостей внутри своих приложений разнообразными путями (т.е. внешне в XML-файлах, с помощью конфигурационных Java классов Spring или посредством аннотаций Java в коде). Компоненты JavaBean (также называемые POJO (Plain Old Java Object — простой старый объект Java)) предоставляют стандартный механизм для создания ресурсов Java, которые являются конфигурируемыми множеством способов. За счет применения DI объем кода, который необходим при проектировании приложения на основе интерфейсов, снижается почти до нуля. Кроме того, с помощью интерфейсов можно получить максимальную отдачу от DI, потому что бины могут использовать любую реализацию интерфейса для удовлетворения их зависимости.
К типам реализации внедрения зависимостей в Spring относят:
Constructor Dependency Injection — это тип внедрения зависимостей, при котором зависимости компонента предоставляются ему в его конструкторе (или конструкторах). Рекомендуется как основной способ, т.к. даже без спринга внедрение зависимостей будет работать корректно.
public class ConstructorInjection {
private Dependency dependency;
public ConstructorInjection(Dependency dependency) {
this.dependency = dependency;
}
}Setter Dependency Injection — контейнер IoC внедряет зависимости компонента в компонент через методы установки в стиле JavaBean. В основном через сеттеры. При модификации не создает новые экземпляры, в отличии от конструктора. Он при каждой модификации создаёт новый экземпляр.
public class SetterInjection {
private Dependency dependency;
public void setDependency(Dependency dependency) {
this.dependency = dependency;
}
}Процесс внедрения зависимостей в бины при инициализации называется Spring Bean Wiring. Считается хорошей практикой задавать явные связи между зависимостями, но в Spring предусмотрен дополнительный механизм связывания @Autowired. Аннотация может использоваться над конструктор, поле, сеттер-метод или метод конфигурации для связывания по типу. Если в контейнере не будет обнаружен необходимый для вставки бин, то будет выброшено исключение, либо можно указать @Autowired(required = false), означающее, что внедрение зависимости в данном месте не обязательно. Чтобы аннотация заработала, необходимо указать небольшие настройки в конфигурационном файле спринг с помощью элемента context:annotation-config/.
Типы связывания:
- autowire byName
- autowire byType
- autowire by constructor
- autowiring by @Autowired and @Qualifier annotations
Начиная со Spring Framework 4.3, аннотация @Autowired для конструктора больше не требуется, если целевой компонент определяет только один конструктор. Однако, если доступно несколько конструкторов и нет основного/стандартного конструктора, по крайней мере один из конструкторов должен быть аннотирован @Autowired, чтобы указать контейнеру, какой из них использовать.
Мы также можем указать Spring предоставить все бины определенного типа из ApplicationContext, добавив аннотацию @Autowired в поле или метод с массивом или коллекцией этого типа, как показано в следующем примере:
@Autowired
private MovieCatalog[] movieCatalogs;
или:
@Autowired
private Set<MovieCatalog> movieCatalogs;
или:
@Autowired
public void setMovieCatalogs(Set<MovieCatalog> movieCatalogs) {
this.movieCatalogs = movieCatalogs;
}Даже коллекции типа Map могут быть подключены автоматически, если тип ключа - String. Ключами будут имена бинов, а значениями - сами бины, как показано в следующем примере:
public class MovieRecommender {
private Map<String, MovieCatalog> movieCatalogs;
@Autowired
public void setMovieCatalogs(Map<String, MovieCatalog> movieCatalogs){
this.movieCatalogs = movieCatalogs;
}
// ...
}Spring имеет собственную MVC-платформу веб-приложений, которая не была первоначально запланирована. Spring MVC является фреймворком, ориентированным на запросы. В нем определены стратегические интерфейсы для всех функций современной запросно-ориентированной системы. Цель каждого интерфейса — быть простым и ясным, чтобы пользователям было легко его заново имплементировать, если они того пожелают. MVC прокладывает путь к более чистому front-end-коду. Все интерфейсы тесно связаны с Servlet API. Эта связь рассматривается некоторыми как неспособность разработчиков Spring предложить для веб-приложений абстракцию более высокого уровня. Однако эта связь оставляет особенности Servlet API доступными для разработчиков, облегчая все же работу с ним. Наиболее важные интерфейсы, определенные Spring MVC, перечислены ниже:
HandlerMapping: выбор класса и его метода, которые должны обработать данный входящий запрос на основе любого внутреннего или внешнего для этого запроса атрибута или состояния.
HandlerAdapter: вызов и выполнение выбранного метода обработки входящего запроса.
Controller: включен между Моделью (Model) и Представлением (View). Управляет процессом преобразования входящих запросов в адекватные ответы. Действует как ворота, направляющие всю поступающую информацию. Переключает поток информации из модели в представление и обратно.
Класс DispatcherServlet является главным контроллером, которые получает запросы и распределяет их между другими контроллерами. @RequestsMapping указывает, какие именно запросы будут обрабатываться в конкретном контроллере. Может быть несколько экземпляров DispatcherServlet, отвечающих за разные задачи (обработка запросов пользовательского интерфейса, REST служб и т.д.). Каждый экземпляр DispatcherServlet имеет собственную конфигурацию WebApplicationContext, которая определяет характеристики уровня сервлета, такие как контроллеры, поддерживающие сервлет, отображение обработчиков, распознавание представлений, интернационализация, оформление темами, проверка достоверности, преобразование типов и форматирование и т.п.
ContextLoaderListener - слушатель при старте и завершении корневого класса Spring WebApplicationContext. Основным назначением является связывание жизненного цикла ApplicationContext и ServletContext, а так же автоматического создания ApplicationContext. Можно использовать этот класс для доступа к бинам из различных контекстов спринг. Настраивается в web.xml
Model: Этот блок инкапсулирует (объединяет) данные приложения. На практике это POJO-классы.
View: ответственно за возвращение ответа клиенту в виде текстов и изображений. Некоторые запросы могут идти прямо во View, не заходя в Model; другие проходят через все три слоя.
ViewResolver: выбор, какое именно View должно быть показано клиенту. Поддерживает распознавание представлений на основе логического имени, возвращаемого контроллером. Для поддержки различных механизмов распознавания представлений предусмотрено множество классов реализации. Например, класс UrlBasedViewResolver поддерживает прямое преобразование логических имен в URL.
Класс ContentNegotiatingViewResolver поддерживает динамическое распознавание представлений в зависимости от типа медиа, поддерживаемого клиентом (XML, PDF, JSON и т.д.). Существует также несколько реализаций для интеграции с различными технологиями представлений, такими как FreeMarker (FreeMarkerViewResolver), Velocity (VelocityViewResolver) и JasperReports (JasperReportsViewResolver).
HandlerInterceptor: перехват входящих запросов. Сопоставим, но не эквивалентен сервлет-фильтрам (использование не является обязательным и не контролируется DispatcherServlet-ом).
LocaleResolver: получение и, возможно, сохранение локальных настроек (язык, страна, часовой пояс) пользователя.
MultipartResolver: обеспечивает Upload — загрузку на сервер локальных файлов клиента. По умолчанию этот интерфейс не включается в приложении и необходимо указывать его в файле конфигурации. После настройки любой запрос о загрузке будет отправляться этому интерфейсу.
Spring MVC предоставляет разработчику следующие возможности:
- Ясное и прозрачное разделение между слоями в MVC и запросах.
- Стратегия интерфейсов — каждый интерфейс делает только свою часть работы.
- Интерфейс всегда может быть заменен альтернативной реализацией.
- Интерфейсы тесно связаны с Servlet API.
- Высокий уровень абстракции для веб-приложений.
- В веб-приложениях можно использовать различные части Spring, а не только Spring MVC.

Паттерн Front Controller обеспечивает единую точку входа для всех входящих запросов. Все запросы обрабатываются одним фрагментом кода, который затем может делегировать ответственность за обработку запроса другим объектам приложения. Он также обеспечивает интерфейс для общего поведения, такого как безопасность, интернационализация и передача определенных представлений определенным пользователям.
В Spring в качестве Front Controller выступает DispatcherServlet, все действия проходят через него. Как правило в приложении задаётся только один DispatcherServlet с маппингом “/”, который перехватывает все запросы. Это и есть реализация паттерна Front Controller.
Однако иногда необходимо определить два и более DispatcherServlet-а, которые будут отвечать за свой собственный функционал. Например, чтобы один обрабатывал REST-запросы с маппингом “/api”, а другой обычные запросы с маппингом “/default”. Spring предоставляет нам такую возможность, и для начала нужно понять, что:
- Spring может иметь несколько контекстов одновременно. Одним из них будет корневой контекст, а все остальные контексты будут дочерними.
- Все дочерние контексты могут получить доступ к бинам, определенным в корневом контексте, но не наоборот. Корневой контекст не может получить доступ к бинам дочерних контекстов.
- Каждый дочерний контекст внутри себя может переопределить бины из корневого контекста.
Каждый DispatcherServlet имеет свой дочерний контекст приложения. DispatcherServlet по сути является сервлетом(он расширяет HttpServlet), основной целью которого является обработка входящих веб�запросов, соответствующих настроенному шаблону URL. Он принимает входящий URI и находит правильную комбинацию контроллера и вида. Веб-приложение может определять любое количество DispatcherServlet-ов. Каждый из них будет работать в своем собственном пространстве имен, загружая свой собственный дочерний WebApplicationContext (на рисунке - Servlet WebApplicationContext) с вьюшками, контроллерами и т.д. Например, когда нам нужно в одном Servlet WebApplicationContext определить обычные контроллеры, а в другом REST-контроллеры.

WebApplicationContext расширяет ApplicationContext (создаёт и управляет бинами и т.д.), но помимо этого он имеет дополнительный метод getServletContext(), через который у него есть возможность получать доступ к ServletContext-у.
ContextLoaderListener создает корневой контекст приложения (на рисунке - Root WebApplicationContext) и будет использоваться всеми дочерними контекстами, созданными всеми DispatcherServlet. Напомню, что корневой контекст приложения будет общим и может быть только один. Root WebApplicationContext содержит компоненты, которые видны всем дочерним контекстам, такие как сервисы, репозитории, компоненты инфраструктуры и т.д. После создания корневого контекста приложения он сохраняется в ServletContext как атрибут, имя которого:
WebApplicationContext.class.getName() + ".ROOT"Чтобы из контроллера любого дочернего контекста обратиться к корневому контексту приложения, мы можем использовать класс WebApplicationContextUtils, содержащий статические методы:
@Autowired
ServletContext context;
ApplicationContext ac =WebApplicationContextUtils.getWebApplicationContext(context);
if(ac == null){
return "root application context is null";
}ContextLoaderListener vs DispatcherServlet
- ContextLoaderListener создает корневой контекст приложения.
- Каждый DispatcherServlet создаёт себе один дочерний контекст.
- Дочерние контексты могут обращаться к бинам, определенным в корневом контексте.
- Бины в корневом контексте не могут получить доступ к бинам в дочерних контекстах (напрямую).
- Все контексты добавляются в ServletContext.
- Мы можем получить доступ к корневому контексту, используя класс WebApplicationContextUtils.

Filter
Это интерфейс из пакета javax.servlet, имплементации которого выполняют задачи фильтрации либо по пути запроса к ресурсу (сервлету, либо по статическому контенту), либо по пути ответа от ресурса, либо в обоих направлениях.
Фильтры выполняют фильтрацию в методе doFilter. Каждый фильтр имеет доступ к объекту FilterConfig, из которого он может получить параметры инициализации, и ссылку на ServletContext, который он может использовать, например, для загрузки ресурсов, необходимых для задач фильтрации. Фильтры настраиваются в дескрипторе развертывания веб-приложения.
В веб-приложении мы можем написать несколько фильтров, которые вместе называются цепочкой фильтров. Веб-сервер решает, какой фильтр вызывать первым, в соответствии с порядком регистрации фильтров.
Когда вызывается метод doFilter(ServletRequest request, ServletResponse response, FilterChain chain) первого фильтра, веб-сервер создает объект FilterChain, представляющий цепочку фильтров, и передаёт её в метод.

Interceptor
Это интерфейс из пакета org.aopalliance.intercept, предназначенный для аспектно�ориентированного программирования. В Spring, когда запрос отправляется в Controller, перед тем как он в него попадёт, он может пройти через перехватчики Interceptor (0 или более). Это одна из реализаций АОП в Spring. Вы можете использовать Interceptor для выполнения таких задач, как запись в Log, добавление или обновление конфигурации перед тем, как запрос обработается Controller-ом.
Стек перехватчиков: он предназначен для связывания перехватчиков в цепочку в определенном порядке. При доступе к перехваченному методу или полю перехватчик в цепочке перехватчиков вызывается в том порядке, в котором он был определен.

Мы можем использовать Interceptor-ы для выполнения логики до попадания в контроллер, после обработки в контроллере, а также после формирования представления. Также можем запретить выполнение метода контроллера. Мы можем указать любое количество перехватчиков.
Перехватчики работают с HandlerMapping и поэтому должны реализовывать интерфейс HandlerInterceptor или наследоваться от готового класса HandlerInterceptorAdapter. В случае реализации HandlerInterceptor нам нужно переопределить 3 метода, а в случае HandlerInterceptor, только необходимые нам:
- public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) - вызывается после того, как HandlerMapping определил соответствующий контроллер, но до того, как HandlerAdapter вызовет метод контроллера. С помощью этого метода каждый перехватчик может решить, прервать цепочку выполнения или направить запрос на испольнение дальше по цепочке перехватчиков до метода контроллера. Если этот метод возвращает true, то запрос отправляется следующему перехватчику или в контроллер. Если метод возвращает false, то исполнение запроса прекращается, обычно отправляя ошибку HTTP или записывая собственный ответ в response.
- public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) - отработает после контроллера, но перед формированием представления. Мы можем использовать этот метод для добавления дополнительных атрибутов в ModelAndView или для определения времени, затрачиваемого методом-обработчиком на обработку запроса клиента. Вы можете добавить больше объектов модели в представление, но вы не можете изменить HttpServletResponse, так как он уже зафиксирован.
- public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) - отработает после формирования представления. Вызывается только в том случае, если метод preHandle этого перехватчика успешно завершен и вернул true!

Image alt Следует знать, что HandlerInterceptor связан с бином DefaultAnnotationHandlerMapping, который отвечает за применение перехватчиков к любому классу, помеченному аннотацией @Controller.
Чтобы добавить наши перехватчики в конфигурацию Spring, нам нужно переопределить метод addInterceptors () внутри класса, который реализует WebMvcConfigurer:
@Override
public void addInterceptors(InterceptorRegistry registry) {
// LogInterceptor applies to all URLs.
registry.addInterceptor(new LogInterceptor());
// This interceptor applies to URL /admin/oldLogin.
// Using OldURLInterceptor to redirect to new URL.
registry.addInterceptor(new OldLoginInterceptor())
.addPathPatterns("/admin/oldLogin");
// This interceptor applies to URLs like /admin/*
// Exclude /admin/oldLogin
registry.addInterceptor(new AdminInterceptor())
.addPathPatterns("/admin/*")//
.excludePathPatterns("/admin/oldLogin");
}Filter vs. Interceptor
- Перехватчик основан на механизме Reflection, а фильтр основан на обратном вызове функции.
- Фильтр зависит от контейнера сервлета, тогда как перехватчик не зависит от него.
- Перехватчики могут работать только с запросами к контроллерам, в то время как фильтры могут работать почти со всеми запросами (например, js, .css и т.д.).
- Перехватчики в отличии от фильтров могут обращаться к объектам в контейнере Spring, что даёт им более изощренный функционал.
Порядок работы:
- Фильтры до;
- Перехватчики до;
- Метод контроллера;
- Перехватчики после;
- Фильтры после.
HandlerInterceptor в основном похож на Servlet Filter, но в отличие от последнего он просто позволяет настраивать предварительную обработку с возможностью запретить выполнение самого обработчика и настраивать постобработку.
Согласно документации Spring, фильтры более мощные, например, они позволяют обмениваться объектами запроса и ответа, которые передаются по цепочке. Это означает, что фильтры работают больше в области запроса/ответа, в то время как HandlerInterceptors являются бинами и могут обращаться к другим компонентам в приложении. Обратите внимание, что фильтр настраивается в web.xml, а HandlerInterceptor в контексте приложения.
Java Listener
Listener (Слушатель) - это класс, который реализует интерфейс javax.servlet.ServletContextListener. Он инициализируется только один раз при запуске веб�приложения и уничтожается при остановке веб-приложения. Слушатель сидит и ждет, когда произойдет указанное событие, затем «перехватывает» событие и запускает собственное событие. Например, мы хотим инициализировать пул соединений с базой данных до запуска веб-приложения. ServletContextListener - это то, что нам нужно, он будет запускать наш код до запуска веб-приложения.
Все ServletContextListeners уведомляются об инициализации контекста до инициализации любых фильтров или сервлетов в веб-приложении.
Все ServletContextListeners уведомляются об уничтожении контекста после того, как все сервлеты и фильтры уничтожены.
Чтобы создать свой Listener нам достаточно создать класс, имплементирующий интерфейс ServletContextListener и поставить над ним аннотацию @WebListener:
@WebListener
public class MyAppServletContextListener
implements ServletContextListener{
//Run this before web application is started
@Override
public void contextInitialized(ServletContextEvent arg0) {
System.out.println("ServletContextListener started");
}
@Override
public void contextDestroyed(ServletContextEvent arg0) {
System.out.println("ServletContextListener destroyed");
}
}@ModelAttribute - связывает параметр метода или возвращаемое значение метода с именованным атрибутом модели, а затем возвращает его view веб-представлению.
Когда аннатоцаия используется над методом, она указывает, что целью этого метода является добавление одного или нескольких атрибутов в модель. При этом Spring-MVC всегда будет сначала вызывать этот метод, прежде чем вызывать какие-либо методы обработчика запросов. То есть, методы @ModelAttribute вызываются до того, как вызываются методы контроллера, аннотированные @RequestMapping.
@ModelAttribute
public void addAttributes(Model model) {
model.addAttribute("msg", "Welcome to the Netherlands!");
}Также важно, чтобы соответствующий класс был помечен как @ControllerAdvice. Таким образом, Вы можете добавить в модель значения, которые будут определены как глобальные. Это фактически означает, что для каждого запроса существует значение по умолчанию, для каждого метода в части ответа.
Когда аннотация ставится в параметрах метода, она указывает, что аргумент должен быть извлечен из модели. Если такой аргумент отсутствует, его следует сначала создать, а затем добавить в модель, а после того, как он появится в модели, поля аргументов должны быть заполнены из всех параметров запроса, имеющих соответствующие имена.
@RequestMapping(value = "/addEmployee", method = RequestMethod.POST)
public String submit(@ModelAttribute("employee") Employee employee) {
// Code that uses the employee object
return "employeeView";
}Атрибут модели сотрудника заполняется данными из формы, отправленной в конечную точку addEmployee. Spring MVC делает это за кулисами перед вызовом метода submit. Таким образом, он связывает данные формы с Bean. Контроллер с аннотацией @RequestMapping может иметь пользовательские аргументы класса с аннотацией @ModelAttribute. Это то, что обычно называют привязкой данных в Spring-MVC, общий механизм, который избавляет вас от необходимости анализировать каждое поле формы по отдельности.
В Spring MVC интерфейс HandlerExceptionResolver (из пакета org.springframework.web.servlet) предназначен для работы с непредвиденными исключениями, возникающими во время выполнения обработчиков. По умолчанию DispatcherServlet регистрирует класс DefaultHandlerExceptionResolver (из пакета org.springframework.web.servlet.mvc.support). Этот распознаватель обрабатывает определенные стандартные исключения Spring MVC, устанавливая специальный код состояния ответа. Можно также реализовать собственный обработчик исключений, аннотировав метод контроллера с помощью аннотации @ExceptionHandler и передав ей в качестве атрибута тип исключения.
В общем случае обработку исключений можно описать таким образом:
- @ExceptionHandler - указать методы для обработки исключения в классе контроллере. Принимает в себя имя класса обрабатываемого исключения (можно несколько).
- @ControllerAdvice - для глобальной обработки ошибок в приложении Spring MVC. Ставится над классом-контроллером, отлавливает все исключения с методов. Он также имеет полный контроль над телом ответа и кодом состояния.
- HandlerExceptionResolver implementation – позволяет задать глобального обработчика исключений. Реализацию этого интерфейса можно использовать для создания собственных глобальных обработчиков исключений в приложении.
Spring MVC предоставляет очень простую и удобную возможность локализации приложения. Для этого необходимо сделать следующее:
- Создать файл resource bundle, в котором будут заданы различные варианты локализированной информации.
- Определить messageSource в конфигурации Spring используя классы ResourceBundleMessageSource или ResourceBundleMessageSource.
- Определить localceResolver класса CookieLocaleResolver для включения возможности переключения локали.
- С помощью элемента spring:message DispatcherServlet будет определять в каком месте необходимо подставлять локализированное сообщение в ответе.
Перехватчики в Spring (Spring Interceptor) являются аналогом Servlet Filter и позволяют перехватывать запросы клиента и обрабатывать их. Перехватить запрос клиента можно в трех местах: preHandle, postHandle и afterCompletion.
- preHandle — метод используется для обработки запросов, которые еще не были переданы в метода обработчик контроллера. Должен вернуть true для передачи следующему перехватчику или в handler method. False укажет на обработку запроса самим обработчиком и отсутствию необходимости передавать его дальше. Метод имеет возможность выкидывать исключения и пересылать ошибки к представлению.
- postHandle — вызывается после handler method, но до обработки DispatcherServlet для передачи представлению. Может использоваться для добавления параметров в объект ModelAndView.
- afterCompletion — вызывается после отрисовки представления.
Для создания обработчика необходимо расширить абстрактный класс HandlerInterceptorAdapter или реализовать интерфейс HandlerInterceptor. Так же нужно указать перехватчики в конфигурационном файле Spring.
Эти интрефейсы используются для запуска логики при запуске приложения, после создания экземпляра контекста приложения Spring.
ApplicationRunner.run() и CommandLineRunner.run() выполнятся сразу после создания applicationcontext и до запуска приложения. Оба они обеспечивают одинаковую функциональность, и единственное различие между CommandLineRunner и ApplicationRunner состоит в том, что CommandLineRunner.run() принимает String array[], тогда как ApplicationRunner.run() принимает ApplicationArguments в качестве аргумента.
@Component
public class CommandLineAppStartupRunner implements CommandLineRunner {
private static final Logger LOG =
LoggerFactory.getLogger(CommandLineAppStartupRunner.class);
public static int counter;
@Override
public void run(String...args) throws Exception {
LOG.info("Increment counter");
counter++;
}
}Можно запускать несколько CommandLineRunner одновременно, например чтобы распаралелить сложную логику. Управлять их порядком через @Order. Каждый Runner может иметь свои собственные зависимости
Реактивное программирование — это программирование в многопоточной среде.
Реактивный подход повышает уровень абстракции вашего кода и вы можете сконцентрироваться на взаимосвязи событий, которые определяют бизнес-логику, вместо того, чтобы постоянно поддерживать код с большим количеством деталей реализации. Код в реактивном программировании, вероятно, будет короче.
Поток — это последовательность, состоящая из постоянных событий, отсортированных по времени. В нем может быть три типа сообщений: значения (данные некоторого типа), ошибки и сигнал о завершении работы. Рассмотрим то, что сигнал о завершении имеет место для экземпляра объекта во время нажатия кнопки закрытия.
Мы получаем эти cгенерированные события асинхронно, всегда. Согласно идеологии реактивного программирования существуют три вида функций: те, которые должны выполняться, когда некоторые конкретные данные будут отправлены, функции обработки ошибок и другие функции с сигналами о завершении работы программы. Иногда последнее два пункта можно опустить и сосредоточится на определении функций для обработки значений. Слушать(listening) поток означает подписаться(subscribing) на него. То есть функции, которые мы определили это наблюдатели(observers). А поток является субъектом который наблюдают.
Критерии реактивного приложения: Responsive. Разрабатываемая система должна отвечать быстро и за определенное заранее заданное время. Кроме того система должна быть достаточно гибкой для самодиагностики и починки.
Что это значит на практикте? Традиционно при запросе некоторого сервиса мы идем в базу данных, вынимаем необходимый объем информации и отдаем ее пользователю. Здесь все хорошо, если наша система достаточно быстрая и база данных не очень большая. Но что, если время формирования ответа гораздно больше ожидаемого? Кроме того, у пользователя мог пропасть интернет на несколько миллисекунд. Тогда все усилия по выборке данных и формированию ответа пропадают. Вспомните gmail или facebook. Когда у вас плохой интернет, вы не получаете ошибку, а просто ждете результат больше обычного. Кроме того, этот пункт говорит нам о том, что ответы и запросы должны быть упорядочены и последовательны.
Resilient. Система остается в рабочем состоянии даже, если один из компонентов отказал.
Другими словами, компоненты нашей системы должны быть досточно гибкими и изолированными друг от друга. Достигается это путем репликаций. Если, например, одна реплика PostgreSQL отказала, необходимо сделать так, чтобы всегда была доступна другая. Кроме того, наше приложение должно работать во множестве экземпляров.
Elastic. Система должна занимать оптимальное количество ресурсов в каждый промежуток времени. Если у нас высокая нагрузка, то необходимо увеличить количество экзепляров приложения. В случае малой нагрузки ресурсы свободных машин должны быть очищены. Типичный инструменты реализации данного принципа: Kubernetes.
Message Driven. Общение между сервисами должно происходить через асинхронные сообщения. Это значит, что каждый элемент системы запрашивает информацию из другого элемента, но не ожидает получение результата сразу же. Вместо этого он продолжает выполняеть свои задачи. Это позволяет увеличить пользу от системных ресурсов и управлять более гибко возникающими ошибками. Обычно такой результат достигается через реактивное программирование.
- Chain of Responsibility - это поведенческий паттерн проектирования, который позволяет передавать запросы последовательно по цепочке обработчиков. Каждый последующий обработчик решает, может ли он обработать запрос сам и стоит ли передавать запрос дальше по цепи. Ему Spring Security
- Singleton (Одиночка) - Паттерн Singleton гарантирует, что в памяти будет существовать только один экземпляр объекта, который будет предоставлять сервисы. Spring область видимости бина (scope) по умолчанию равна singleton и IoC-контейнер создаёт ровно один экземпляр объекта на Spring IoC-контейнер. Spring-контейнер будет хранить этот единственный экземпляр в кэше синглтон-бинов, и все последующие запросы и ссылки для этого бина получат кэшированный объект. Рекомендуется использовать область видимости singleton для бинов без состояния. Область видимости бина можно определить как singleton или как prototype (создаётся новый экземпляр при каждом запросе бина).
- Model View Controller (Модель-Представление-Контроллер) - Преимущество Spring MVC в том, что ваши контроллеры являются POJO, а не сервлетами. Это облегчает тестирование контроллеров. Стоит отметить, что от контроллеров требуется только вернуть логическое имя представления, а выбор представления остаётся за ViewResolver. Это облегчает повторное использование контроллеров при различных вариантах представления.
- Front Controller (Контроллер запросов) - Spring предоставляет DispatcherServlet, чтобы гарантировать, что входящий запрос будет отправлен вашим контроллерам.Паттерн Front Controller используется для обеспечения централизованного механизма обработки запросов, так что все запросы обрабатываются одним обработчиком. Этот обработчик может выполнить аутентификацию, авторизацию, регистрацию или отслеживание запроса, а затем передать запрос соответствующему контроллеру. View Helper отделяет статическое содержимое в представлении, такое как JSP, от обработки бизнес-логики.
- Dependency injection и Inversion of control (IoC) (Внедрение зависимостей и инверсия управления) - IoC-контейнер в Spring, отвечает за создание объекта, связывание объектов вместе, конфигурирование объектов и обработку всего их жизненного цикла от создания до полного уничтожения. В контейнере Spring используется инъекция зависимостей (Dependency Injection, DI) для управления компонентами приложения. Эти компоненты называются "Spring-бины" (Spring Beans).
- Service Locator (Локатор служб) - ServiceLocatorFactoryBean сохраняет информацию обо всех бинах в контексте. Когда клиентский код запрашивает сервис (бин) по имени, он просто находит этот компонент в контексте и возвращает его. Клиентскому коду не нужно писать код, связанный со Spring, чтобы найти бин. Паттерн Service Locator используется, когда мы хотим найти различные сервисы, используя JNDI. Учитывая высокую стоимость поиска сервисов в JNDI, Service Locator использует кеширование. При запросе сервиса первый раз Service Locator ищет его в JNDI и кэширует объект. Дальнейший поиск этого же сервиса через Service Locator выполняется в кэше, что значительно улучшает производительность приложения.
- Observer-Observable (Наблюдатель) - Используется в механизме событий ApplicationContext. Определяет зависимость "один-ко-многим" между объектами, чтобы при изменении состояния одного объекта все его подписчики уведомлялись и обновлялись автоматически.
- Context Object (Контекстный объект) - Паттерн Context Object, инкапсулирует системные данные в объекте-контексте для совместного использования другими частями приложения без привязки приложения к конкретному протоколу. ApplicationContext является центральным интерфейсом в приложении Spring для предоставления информации о конфигурации приложения.
- Proxy (Заместитель) - позволяет подставлять вместо реальных объектов специальные объекты-заменители. Эти объекты перехватывают вызовы к оригинальному объекту, позволяя сделать что-то до или после передачи вызова оригиналу.
- Factory (Фабрика) - определяет общий интерфейс для создания объектов в суперклассе, позволяя подклассам изменять тип создаваемых объектов.
- Template (Шаблон) - Этот паттерн широко используется для работы с повторяющимся бойлерплейт кодом (таким как, закрытие соединений и т. п.).
Аспектно-ориентированное программирование (АОП) — это парадигма программирования, целью которой является повышение модульности за счет разделения междисциплинарных задач. Это достигается путем добавления дополнительного поведения к существующему коду без изменения самого кода.
ООП, AOP и Spring - взаимодополняющие технологии, которые позволяют решать сложные проблемы путем разделения функционала на отдельные модули. АОП предоставляет возможность реализации сквозной логики - т.е. логики, которая применяется к множеству частей приложения - в одном месте и обеспечения автоматического применения этой логики по всему приложению. Подход Spring к АОП заключается в создании "динамических прокси" для целевых объектов и "привязывании" объектов к конфигурированному совету для выполнения сквозной логики.
Аспект (Aspect) - Это модуль, который имеет набор программных интерфейсов, которые обеспечивают сквозные требования. К примеру, модуль логирования будет вызывать АОП аспект для логирования. В зависимости от требований, приложение может иметь любое количество аспектов.
Объединённая точка (Join point) - Это такая точка в приложении, где мы можем подключить аспект. Другими словами, это место, где начинаются определённые действия модуля АОП в Spring.
Совет (Advice) - Это фактическое действие, которое должно быть предпринято до и/или после выполнения метода. Это конкретный код, который вызывается во время выполнения программы.
- before - Запускает совет перед выполнением метода.
- after - Запускает совет после выполнения метода, независимо от результата его работы (кроме случая остановки работы JVM).
- after-returning - Запускает совет после выполнения метода, только в случае его успешного выполнения.
- after-throwing - Запускает совет после выполнения метода, только в случае, когда этот метод “бросает” исключение.
- around - Запускает совет до и после выполнения метода. При этом инпоинты видят только начало и конец метода. Например, если метод выполняет транзакцию и где-то в середине кода try/catch поймал exception, транзакция все равно будет свершена, rollback не произойдет. В этом случае нужно пробрасывать ошибку за пределы метода.
Срез точек (Pointcut) - Срезом называется несколько объединённых точек (join points), в котором должен быть выполнен совет.
Введение (Introduction) - Это сущность, которая помогает нам добавлять новые атрибуты и/или методы в уже существующие классы.
Целевой объект (Target object) - Это объект на который направлены один или несколько аспектов.
Плетение (Weaving) - Это процесс связывания аспектов с другими объектами приложения для создания совета. Может быть вызван во время компиляции, загрузки или выполнения приложения.
С помощью АОП мы можем прописать, например, что будет выполняться до или после какого-то действия. Прописываем это один раз и этот функционал будет работать везде. Например нам нужно сделать логирование во всех методах @Service, с ООП нам бы пришлось прописывать этот функционал в каждом методе для всех @Service. А с АОП мы можем в конфигах прописать для @Service что будет происходить с каждым вызовом его методов, - в нашем случае писать логи. Элементы АОП такие как аспекты также используются в
AspectJ де-факто является стандартом реализации АОП. Реализация АОП от Spring имеет некоторые отличия:
- Spring AOP немного проще, т.к. нет необходимости следить за процессом связывания.
- Spring AOP поддерживает аннотации AspectJ, таким образом мы можем работать в спринг проекте похожим образом с AspectJ проектом.Spring + AOP поддерживает только proxy-based АОП и может использовать только один тип точек соединения - Method Invocation. AspectJ поддерживает все виды точек соединения.
- Недостатком Spring AOP является работа только со своими бинами, которые существуют в Spring Context.
- @Autowired - используется для автоматического связывания зависимостей в spring beans.
- @Bean - В классах конфигурации Spring, @Bean используется для для непосредственного создания бина.
- @Controller - класс фронт контроллера в проекте Spring MVC.
- @ConditionalOn* - Создает бин если выполняется условие. Condition - функциональный интерфейс, который содержит метод boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata)
- @Sheduler - Таймер. Раз в сколько-то секунд обрабатывать.
- @Resource - Java аннотация, которой можно внедрить зависимость.
- @Requared - применяется к методам-сеттерам и означает, что значение метода должно быть установлено в XML-файле. Если этого не будет сделано, то мы получим BeanInitializationException.
- @RequestMapping - используется для мапинга (связывания) с URL для всего класса или для конкретного метода обработчика.
- @ResponseBody - позволяет отправлять Object в ответе. Обычно используется для отправки данных формата XML или JSON.
- @ResponseEntity - используется для формирования ответа HTTP с пользовательскими параметрами (заголовки, http-код и т.д.). ResponseEntity необходим, только если мы хотим кастомизировать ответ, добавив к нему статус ответа. Во всех остальных случаях будем использовать @ResponseBody.
- @PathVariable - задает динамический маппинг значений из URI внутри аргументов метода обработчика, т.е. позволяет вводить в URI переменную пути в качестве параметра
- @Qualifier - используется совместно с @Autowired для уточнения данных связывания, когда возможны коллизии (например одинаковых имен\типов).
- @Service - указывает что класс осуществляет сервисные функции.
- @Scope - указывает scope у spring bean.
- @Configuration, @ComponentScan и @Bean - для java based configurations.
- AspectJ аннотации для настройки aspects и advices, @Aspect, @Before, @After,@Around, @Pointcut и др.
- @PageableDefault - устанавливает значение по умолчанию для параметра разбиения на страницы
Они все служат для обозначения класса как Бин.
- @Component - Spring определяет этот класс как кандидата для создания bean.
- @Service - класс содержит бизнес-логику и вызывает методы на уровне хранилища. Ничем не отличается от классов с @Component.
- @Repository - указывает, что класс выполняет роль хранилища (объект доступа к DAO). При этом отлавливает определенные исключения персистентности и пробрасывает их как одно непроверенное исключение Spring Framework. Для этого Spring оборачивает эти классы в прокси, и в контекст должен быть добавлен класс PersistenceExceptionTranslationPostProcessor
- @Controller - указывает, что класс выполняет роль контроллера MVC. Диспетчер сервлетов просматривает такие классы для поиска @RequestMapping.
@Controller помечает класс как контроллер HTTP запросов.
В Spring 4.0 была представлена аннотация @RestController. Применив ее к контроллеру автоматически добавляются аннотации @Controller, а так же @ResponseBody применяется ко всем методам.
Если есть два одинаковых бина (по типу и имени) спринг не знает какой именно использовать и выдаёт exeption. Если над одним из этих бинов установленна @Primary, то его использовать предпочтительнее. Но если нам нужно использовать в работе оба этих бина, можно над каждым поставить @Qualifier и задать имя, для идентификации этих бинов.
Используя аннотацию @Profile - мы сопоставляем bean-компонент с этим конкретным профилем; аннотация просто берет имена одного (или нескольких) профилей. Отвечает за то - какие бины буду создаваться, в зависимости от профайла. Фактически реализована с помощью гораздо более гибкой аннотации @Conditional.
Рассмотрим базовый сценарий - у нас есть компонент, который должен быть активным только во время разработки, но не должен использоваться в производстве. Мы аннотируем этот компонент с профилем «dev», и он будет присутствовать в контейнере только во время разработки - в производственном процессе dev просто не будет активен.
Или можно задать @Profile("postgres") и @Profile("mysql"), а в application.properties указать, бин с каким профилем использовать = spring.profiles.active = mysql
По умолчанию, если профиль бина не определен, то он относится к профилю “default”. Spring также предоставляет способ установить профиль по умолчанию, когда другой профиль не активен, используя свойство «spring.profiles.default».
Используется для внедрения prototype bean в singleton bean.
ПРИМЕР - Обычно бины в приложении Spring являтся синглтонами, и для внедрения зависимостей мы используем конструктор или сеттер. Но бывает и другая ситуация: имеется бин Car – синглтон (singleton bean), и ему требуется каждый раз новый экземпляр бина Passenger. То есть Car – синглтон, а Passenger – так называемый прототипный бин (prototype bean). Жизненные циклы бинов разные. Бин Car создается контейнером только раз, а бин Passenger создается каждый раз новый – допустим, это происходит каждый раз при вызове какого-то метода бина Car.Вот здесь то и пригодится внедрение бина с помощью Lookup метода. Оно происходит не при инициализации контейнера, а позднее: каждый раз, когда вызывается метод.
@Component
public class Car {
@Lookup
public Passenger createPassenger() {
return null;
}
public String drive(String name) {
Passenger passenger = createPassenger();
passenger.setName(name);
return "car with " + passenger.getName();
}
}Суть в том, что вы создаете метод-заглушку в бине Car и помечаете его специальным образом – аннотацией @Lookup. Этот метод должен возвращать бин Passenger, каждый раз новый. Контейнер Spring под капотом создаст подкласс и переопределит этот метод и будет вам выдавать новый экземпляр бина Passenger при каждом вызове аннотированного метода. Даже если в вашей заглушке он возвращает null (а так и надо делать, все равно этот метод будет переопределен).
@Component
@Scope("prototype")
public class Passenger {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}Теперь при вызове метода drive() мы можем везти каждый раз нового пассажира. Имя его передаётся в аргументе метода drive(), и затем задается сеттером во вновь созданном экземпляре пассажира.
@Retention - указаываем, в какой момент жизни программного кода будет доступна аннотация
- SOURCE - аннотация доступна только в исходном коде и сбрасывается во время создания .class файла;
- CLASS - аннотация хранится в .class файле, но недоступна во время выполнения программы;
- RUNTIME - аннотация хранится в .class файле и доступна во время выполнения программы.
@Target - указывается, какой элемент программы будет использоваться аннотацией
- PACKAGE - назначением является целый пакет (package);
- TYPE - класс, интерфейс, enum или другая аннотация:
- METHOD - метод класса, но не конструктор (для конструкторов есть отдельный тип CONSTRUCTOR);
- PARAMETER - параметр метода;
- CONSTRUCTOR - конструктор;
- FIELD - поля-свойства класса;
- LOCAL_VARIABLE - локальная переменная (обратите внимание, что аннотация не может быть прочитана во время выполнения программы, то есть, данный тип аннотации может использоваться только на уровне компиляции как, например, аннотация @SuppressWarnings);
- ANNOTATION_TYPE - другая аннотация.
Java-аннотация @Resource может применяться к классам, полям и методам. Она пытается получить зависимость: сначала по имени, затем по типу, затем по описанию (Qualifier). Имя извлекается из имени аннотируемого сеттера или поля, либо берется из параметра name. При аннотировании классов имя не извлекается из имени класса по умолчанию, поэтому оно должно быть указано явно.
Указав данную аннотацию у полей или методов с аргументом name, в контейнере будет произведен поиск компонентов с данным именем, и в контейнере должен быть бин с таким именем:
@Resource(name="namedFile")
private File defaultFile;Если указать её без аргументов, то Spring Framework поможет найти бин по типу. Если в контейнере несколько бинов-кандидатов на внедрение, то нужно использовать аннотацию @Qualifier:
@Resource
@Qualifier("defaultFile")
private File dependency1;
@Resource
@Qualifier("namedFile")
private File dependency2;Разница с @Autowired:
- ищет бин сначала по имени, а потом по типу;
- не нужна дополнительная аннотация для указания имени конкретного бина;
- @Autowired позволяет отметить место вставки бина как необязательное @Autowired(required = false);
- при замене Spring Framework на другой фреймворк, менять аннотацию @Resource не нужно
Размещается над полями, методами, и конструкторами с аргументами. @Inject как и @Autowired в первую очередь пытается подключить зависимость по типу, затем по описанию и только потом по имени. Это означает, что даже если имя переменной ссылки на класс отличается от имени компонента, но они одинакового типа, зависимость все равно будет разрешена:
@Inject
private ArbitraryDependency fieldInjectDependency;
//fieldInjectDependency - отличается от имени компонента, настроенного в контексте приложения:
@Bean
public ArbitraryDependency injectDependency() {
ArbitraryDependency injectDependency = new ArbitraryDependency();
return injectDependency;
}Разность имён injectDependency и fieldInjectDependency не имеет значения, зависимость будет подобрана по типу ArbitraryDependency. Если в контейнере несколько бинов-кандидатов на внедрение, то нужно использовать аннотацию @Qualifier:
@Inject
@Qualifier("defaultFile")
private ArbitraryDependency defaultDependency;
@Inject
@Qualifier("namedFile")
private ArbitraryDependency namedDependency;
//При использовании конкретного имени (Id) бина используем @Named:
@Inject
@Named("yetAnotherFieldInjectDependency")
private ArbitraryDependency yetAnotherFieldInjectDependencyАннотации для внедрения зависимостей.
@Resource (java) пытается получить зависимость: по имени, по типу, затем по описанию. Имя извлекается из имени аннотируемого сеттера или поля, либо берется из параметра name.
@Inject (java) или @Autowired (spring) в первую очередь пытается подключить зависимость по типу, затем по описанию и только потом по имени.
Часто бывает полезно включить или отключить весь класс @Configuration, @Component или отдельные методы @Bean в зависимости от каких-либо условий.
Аннотация @Conditional указывает, что компонент имеет право на регистрацию в контексте только тогда, когда все условия соответствуют. Может применяться:
- над классами прямо или косвенно аннотированными @Component, включая классы @Configuration;
- над методами @Bean;
- как мета-аннотация при создании наших собственных аннотаций-условий.
Условия проверяются непосредственно перед тем, как должно быть зарегистрировано BeanDefinition компонента, и они могут помешать регистрации данного BeanDefinition. Поэтому нельзя допускать, чтобы при проверке условий мы взаимодействовали с бинами (которых еще не существует), с их BeanDefinition-ами можно.
Условия мы определяем в специально создаваемых нами классах, которые должны имплементировать функциональный интерфейс Condition с одним единственным методом, возвращающим true или false:
boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata);Создав свой класс и переопределив в нем метод matches() с нашей логикой, мы должны передать этот класс в аннотацию @Conditional в качестве параметра:
@Configuration
@Conditional(OurConditionClass.class)
class MySQLAutoconfiguration {
//...
}
//Для того, чтобы проверить несколько условий, можно передать в @Conditional несколько классов с условиями:
@Bean
@Conditional(HibernateCondition.class, OurConditionClass.class)
Properties additionalProperties() {
//...
}Если класс @Configuration помечен как @Conditional, то на все методы @Bean, аннотации @Import и аннотации @ComponentScan, связанные с этим классом, также будут распространяться указанные условия.
Для более детальной настройки классов, аннотированных @Configuration, предлагается использовать интерфейс ConfigurationCondition.
В одном классе - одно условие. Для создания более сложных условий можно использовать классы AnyNestedCondition, AllNestedConditions и NoneNestedConditions.
В Spring Framework имеется множество готовых аннотаций (и связанных с ними склассами-условиями, имплементирующими интерфейс Condition), которые можно применять совместно над одним определением бина:
ConditionalOnBean Условие выполняется, в случае если присутствует нужный бин в BeanFactory. ConditionalOnClass Условие выполняется, если нужный класс есть в classpath. ConditionalOnCloudPlatform Условие выполняется, когда активна определенная платформа. ConditionalOnExpression Условие выполняется, когда SpEL выражение вернуло положительное значение. ConditionalOnJava Условие выполняется, когда приложение запущено с определенной версией JVM. ConditionalOnJndi Условие выполняется, только если через JNDI доступен определенный ресурс. ConditionalOnMissingBean Условие выполняется, в случае если нужный бин отсутствует в контейнере. ConditionalOnMissingClass Условие выполняется, если нужный класс отсутствует в classpath. ConditionalOnNotWebApplication Условие выполняется, если контекст приложения не является веб контекстом. ConditionalOnProperty Условие выполняется, если в файле настроек заданы нужные параметры. ConditionalOnResource Условие выполняется, если присутствует нужный ресурс в classpath. ConditionalOnSingleCandidate Условие выполняется, если bean-компонент указанного класса уже содержится в контейнере и он единственный. ConditionalOnWebApplication Условие выполняется, если контекст приложения является веб контекстом.
Spring поддерживает два типа управления транзакциями:
- Программное управление транзакциями: Вы должны управлять транзакциями с помощью программирования. Это способ достаточно гибкий, но его сложно поддерживать. Либо через использование TransactionTemplate, либо через реализацию PlatformTransactionManager напрямую. Используется, если нужно работать с небольшим количеством транзакций.
- Декларативное управление транзакциями: Вы отделяете управление транзакциями от бизнес-логики. Вы используете только аннотации @Transactional и конфигурацией на основе XML для управления транзакциями. Наиболее предпочтительный способ.
Простая реализация PlatformTransactionManager это DataSourceTransactionManager, который на каждую транзакцию в БД будет создавать Connection.
DefaultTransactionDefinition definition = new DefaultTransactionDefinition(); //описание транзакции, можно задавать параметры
TransactionStatus status = transactionManager.getTransaction(); //статус транзакции
try {
fooRepository.insertFoo("name");
transactionManager.commit(status);
} catch (RuntimeException e) {
transactionManager.rollback(status);
}Spring DAO предоставляет возможность работы с доступом к данным с помощью технологий вроде JDBC, Hibernate в удобном виде. Существуют специальные классы: JdbcDaoSupport, HibernateDaoSupport, JdoDaoSupport, JpaDaoSupport.
Класс HibernateDaoSupport является подходящим суперклассом для Hibernate DAO. Он содержит методы для получения сессии или фабрики сессий. Самый популярный метод - getHibernateTemplate(), который возвращает HibernateTemplate. Этот темплейт оборачивает checked-исключения Hibernate в runtime-исключения, позволяя вашим DAO оставаться независимыми от исключений Hibernate.
Интерфейс Model инкапсулирует (объединяет) данные приложения. ModelMap реализует этот интерфейс, с возможностью передавать коллекцию значений. Затем он обрабатывает эти значения, как если бы они были внутри Map. Следует отметить, что в Model и ModelMap мы можем хранить только данные. Мы помещаем данные и возвращаем имя представления.
С другой стороны, с помощью ModelAndView мы возвращаем сам объект. Мы устанавливаем всю необходимую информацию, такую как данные и имя представления, в объекте, который мы возвращаем.
Метод addAttribute отделяет нас от работы с базовой структурой hashmap. По сути addAttribute это обертка над put, где делается дополнительная проверка на null. Метод addAttribute в отличии от put возвращает modelmap.
PreparedStatement - нужен для защиты от SQL-инъекций в запросах, а PreparedStatementCreator - для создания возврата PreparedStatement из connection. При этом он автоматически обрабатывает все исключения (кроме SQLExeption).
SOAP – это целое семейство протоколов и стандартов, для обмена структурированными сообщениями. Это более тяжеловесный и сложный вариант с точки зрения машинной обработки. Поэтому REST работает быстрее.
REST - это не протокол и не стандарт, а архитектурный стиль. У этого стиля есть свои принципы:
Give every “thing” an ID;
Link things together - Например, в страницу (представление) о Mercedes C218 хорошо бы добавить ссылку на страницу конкретно о двигателе данной модели, чтобы желающие могли сразу туда перейти, а не тратить время на поиск этой самой страницы;
Use standard methods - Имеется в виду, экономьте свои силы и деньги заказчика, используйте стандартные методы HTTP, например GET http://www.example.com/cars/00345 для получения данных вместо определения собственных методов вроде getCar?id=00345;
Resources can have multiple representations - Одни и те же данные можно вернуть в XML или JSON для программной обработки или обернутыми в красивый дизайн для просмотра человеком;
Communicate statelessly - Да, RESTful сервис должен быть как идеальный суд – его не должно интересовать ни прошлое подсудимого (клиента), ни будущее – он просто выносит приговор (отвечает на запрос).
Термин RESTful (веб-)сервис всего лишь означает сервис, реализованный с использованием принципов REST.
При этом SOAP и REST – не конкуренты. Они представляют разные весовые категории и вряд ли найдется задача, для которой будет сложно сказать, какой подход рациональнее использовать – SOAP или REST.
Spring Data — дополнительный удобный механизм для взаимодействия с сущностями базы данных, организации их в репозитории, извлечение данных, изменение, в каких то случаях для этого будет достаточно объявить интерфейс и метод в нем, без имплементации.
- CrudRepository - обеспечивает функции CRUD
- PagingAndSortingRepository - предоставляет методы для разбивки на страницы и сортировки записей
- JpaRepository - предоставляет связанные с JPA методы. При этом JpaRepository содержит полный API CrudRepository и PagingAndSortingRepository
Основное понятие в Spring Data — это репозиторий. Это несколько интерфейсов которые используют JPA Entity для взаимодействия с ней. Так например интерфейс ( public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> ) обеспечивает основные операции по поиску, сохранения, удалению данных (CRUD операции).
Т.е. если того перечня что предоставляет интерфейс достаточно для взаимодействия с сущностью, то можно прямо расширить базовый интерфейс для своей сущности, дополнить его своими методами запросов и выполнять операции.
Понятно что этого перечня, скорее всего не хватит для взаимодействия с сущностью, и тут можно расширить свой интерфейс дополнительными методами запросов. Запросы к сущности можно строить прямо из имени метода. Для этого используется механизм префиксов find…By, read…By, query…By, count…By, и get…By, далее от префикса метода начинает разбор остальной части. Вводное предложение может содержать дополнительные выражения, например, Distinct. Далее первый By действует как разделитель, чтобы указать начало фактических критериев. Можно определить условия для свойств сущностей и объединить их с помощью And и Or.
Если нужен специфичный метод или его реализация, которую нельзя описать через имя метода, то это можно сделать через некоторый Customized интерфейс ( CustomizedEmployees) и сделать реализацию вычисления. А можно пойти другим путем, через указание запроса (HQL или SQL), как вычислить данную функцию. Отметив запрос аннотацией @Query.
Нативный запрос можно написать так:
public interface RoleRepository extends JpaRepository<Role, Long>{
Optional<Role> findRoleByRoleName(String name);
@Modifying
@Transactional
@Query(value = "INSERT INTO user_roles (user_id, role_id) VALUE (:user_id, :role_id)", nativeQuery = true)
void insertRoles(@Param("user_id) Long user_id, @Param("role_id") Long role_id);
//можно использовать с EntityGraph, обычным, не NamedEntityGraph
@EntityGraph(value = "customer.products")
List<Customer> findAll(@Nullable Specification<Customer> specification)Поскольку мы используем JPA, нам нужно определить свойства для подключения к базе данных в файле persistence.xml, а не в hibernate.cfg.xml. Создайте новый каталог с именем META-INF в исходной папке проекта, чтобы поместить в него файл persistence.xml.
Затем прописать в вайле свойства для подключения к базе, например:
<persistence-unit name="DataBaseName">
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/sales" />
<property name="javax.persistence.jdbc.user" value="root" />
<property name="javax.persistence.jdbc.password" value="root" />
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
</properties>
</persistence-unit>Для работы с Spring Data JPA нам надо создать два beans-компонента: EntityManagerFactory и JpaTransactionManager. Поэтому создадим другой конфигурационный класс JpaConfig:
@Configuration
@EnableJpaRepositories(basePackages = {"net.codejava.customer"})
@EnableTransactionManagement
public class JpaConfig {
@Bean
public LocalEntityManagerFactoryBean entityManagerFactory() {
LocalEntityManagerFactoryBean factoryBean = new LocalEntityManagerFactoryBean();
factoryBean.setPersistenceUnitName("SalesDB");
return factoryBean;
}
@Bean
public JpaTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(entityManagerFactory);
return transactionManager;
}
}@EnableJpaRepositories: сообщает Spring Data JPA, что нужно искать классы репозитория в указанном пакете (net.codejava) для внедрения соответсвующего кода во время выполнения.
@EnableTransactionManagement: сообщает Spring Data JPA, чтобы тот генерировал код для управления транзакциями во время выполнения.
В этом классе первый метод создаёт экземпляр EntityManagerFactory для управления Persistence Unit нашей SalesDB (это имя указано выше в persistence.xml).
Последний метод создаёт экземпляр JpaTransactionManager для EntityManagerFactory, созданный методом ранее.
Это минимальная необходимая конфигурация для использования Spring Data JPA.
Spring Security предоставляет широкие возможности для защиты приложения. Кроме стандартных настроек для аутентификации, авторизации и распределения ролей и маппинга доступных страниц, ссылок и т.п., предоставляет защиту от различных вариантов атак
Spring Security - это список фильтров в виде класса FilterChainProxy, интегрированного в контейнер сервлетов, и в котором есть поле List. Каждый фильтр реализует какой-то механизм безопасности. Важна последовательность фильтров в цепочке.

Когда мы добавляем аннотацию @EnableWebSecurity добавляется DelegatingFilterProxy, его задача заключается в том, чтобы вызвать цепочку фильтров (FilterChainProxy) из Spring Security.
В Java-based конфигурации цепочка фильтров создается неявно.
Если мы хотим настроить свою цепочку фильтров, мы можем сделать это, создав класс, конфигурирующий наше Spring Security приложение, и имплементировав интерфейс WebSecurityConfigurerAdapter. В данном классе, мы можем переопределить метод:
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.csrf().disable()
.authorizeRequests();
}Именно этот метод конфигурирует цепочку фильтров Spring Security и логика, указанная в этом методе, настроит цепочку фильтров.
Основные классы и интерфейсы
SecurityContext - интерфейс, отражающий контекст безопасности для текущего потока. Является контейнером для объекта типа Authentication. (Аналог - ApplicationContext, в котором лежат бины).
По умолчанию на каждый поток создается один SecurityContext. SecurityContext-ы хранятся в SecurityContextHolder.
Имеет только два метода: getAuthentication() и setAuthentication(Authentication authentication). SecurityContextHolder - это место, где Spring Security хранит информацию о том, кто аутентифицирован. Класс, хранящий в ThreadLocal SecurityContext-ы для каждого потока, и содержащий статические методы для работы с SecurityContext-ами, а через них с текущим объектом Authentication, привязанным к нашему веб-запросу.

Authentication - объект, отражающий информацию о текущем пользователе и его привилегиях. Вся работа Spring Security будет заключаться в том, что различные фильтры и обработчики будут брать и класть объект Authentication для каждого посетителя. Кстати объект Authentication можно достать в Spring MVC контроллере командой SecurityContextHolder.getContext().getAuthentication(). Authentication имеет реализацию по умолчанию - класс UsernamePasswordAuthenticationToken, предназначенный для хранения логина, пароля и коллекции Authorities. Principal - интерфейс из пакета java.security, отражающий учетную запись пользователя. В терминах логин-пароль это логин. В интерфейсе Authentication есть метод getPrincipal(), возвращающий Object. При аутентификации с использованием имени пользователя/пароля Principal реализуется объектом типа UserDetails. Credentials - любой Object; то, что подтверждает учетную запись пользователя, как правило пароль (отпечатки пальцев, пин - всё это Credentials, а владелец отпечатков и пина - Principal). GrantedAuthority - полномочия, предоставленные пользователю, например, роли или уровни доступа. UserDetails - интерфейс, представляющий учетную запись пользователя. Как правило модель нашего пользователя должна имплементировать его. Она просто хранит пользовательскую информацию в виде логина, пароля и флагов isAccountNonExpired, isAccountNonLocked, isCredentialsNonExpired, isEnabled, а также коллекции прав (ролей)пользователя. Данная информация позже инкапсулируется в объекты Authentication. UserDetailsService - интерфейс объекта, реализующего загрузку пользовательских данных из хранилища. Созданный нами объект с этим интерфейсом должен обращаться к БД и получать оттуда юзеров. используется чтобы создать UserDetails объект путем реализации единственного метода этого интерфейса
UserDetails loadUserByUsername(String username) throws UsernameNotFoundException; AuthenticationManager - основной стратегический интерфейс для аутентификации. Имеет только один метод, который срабатывает, когда пользователь пытается аутентифицироваться в системе:
public interface AuthenticationManager {
Authentication authenticate(Authentication authentication)
throws AuthenticationException;
}AuthenticationManager может сделать одну из 3 вещей в своем методе authenticate():
- вернуть Authentication (с authenticated=true), если предполагается, что вход осуществляет корректный пользователь.
- бросить AuthenticationException, если предполагается, что вход осуществляет некорректный пользователь.
- вернуть null, если принять решение не представляется возможным.
Наиболее часто используемая реализация AuthenticationManager - родной класс ProviderManager, который содержит поле private Listproviders со списком AuthenticationProvider-ов и итерирует запрос аутентификации по этому списку AuthenticationProvider-ов. Идея такого разделения - поддержка различных механизмов аутентификации на сайтах.
AuthenticationProvider - интерфейс объекта, выполняющего аутентификацию. Имеет массу готовых реализаций. Также можем задать свой тип аутентификации. Как правило в небольших проектах одна логика аутентификации - по логину и паролю. В проектах побольше логик может быть несколько: Google-аутентификация и т.д., и для каждой из них создается свой объект AuthenticationProvider.
AuthenticationProvider немного похож на AuthenticationManager, но у него есть дополнительный метод, позволяющий вызывающей стороне спрашивать, поддерживает ли он переданный ему объект Authentication, возможно этот AuthenticationProvider может поддерживать только аутентификацию по логину и паролю, но не поддерживать Google�аутентификацию:
boolean supports(java.lang.Class<?> authentication)PasswordEncoder - интерфейс для шифрования/расшифровывания паролей. Одна из популярных реализаций - BCryptPasswordEncoder.
В случае, если нам необходимо добавить логику при успешной/неудачной аутентификации, мы можем создать класс и имплементировать интерфейсы AuthenticationSuccessHandler и AuthenticationFailureHandler соответственно, переопределив их методы.
Как это работает с формой логина и UserDetailsService:
- Пользователь вводит в форму и отправляет логин и пароль.
- UsernamePasswordAuthenticationFilter создает объект Authentication - UsernamePasswordAuthenticationToken, где в качестве Principal - логин, а в качестве Credentials - пароль.
- Затем UsernamePasswordAuthenticationToken передаёт объект Authentication с логином и паролем AuthenticationManager-у.
- AuthenticationManager в виде конкретного класса ProviderManager внутри своего списка объектов AuthenticationProvider, имеющих разные логики аутентификации, пытается аутентифицировать посетителя, вызывая его метод authenticate(). У каждого AuthenticationProvider-а: 1 Метод authenticate() принимает в качестве аргумента незаполненный объект Authentication, например только с логином и паролем, полученными в форме логина на сайте. Затем с помощью UserDetailsService метод идёт в БД и ищет такого пользователя. 2 Если такой пользователь есть в БД, AuthenticationProvider получает его из базы в виде объекта UserDetails. Объект Authentication заполняется данными из UserDetails - в него включаются Authorities, а в Principal записывается сам объект UserDetails, содержащий пользователя. 3 Затем этот метод возвращает заполненный объект Authentication (прошли аутентификацию). Вызывается AuthenticationSuccessHandler. 4 Если логин либо пароль неверные, то выбрасывается исключение. Вызывается AuthenticationFailureHandler.
- Затем этот объект Authentication передается в AccessDecisionManager и получаем решение на получение доступа к запрашиваемой странице (проходим авторизацию).
Аннотации:
- @EnableGlobalMethodSecurity - включает глобальный метод безопасности.
- @EnableWebMvcSecurity - "включает" Spring Security. Не будет работать, если наш класс не наследует WebSecurityConfigurerAdapter
- @Secured используется для указания списка ролей в методе
- @PreAuthorize и @PostAuthorize обеспечивают контроль доступа на основе выражений. @PreAuthorize проверяет данное выражение перед входом в метод, тогда как аннотация @PostAuthorize проверяет его после выполнения метода и может изменить результат.
- @PreFilter для фильтрации аргумента коллекции перед выполнением метода
По сути, Spring Boot это просто набор классов конфигурации, которые создают нужные бины в контексте. Точно так же их можно создать руками, просто Boot это автоматизирует. При этом помогая решить проблему конфликтов разных версий компонентов.
Чтобы ускорить процесс управления зависимостями, Spring Boot неявно упаковывает необходимые сторонние зависимости для каждого типа приложения на основе Spring и предоставляет их разработчику посредством так называемых starter-пакетов (spring-boot-starter-web, spring-boot-starter-data-jpa и т.д.)
Starter-пакеты представляют собой набор удобных дескрипторов зависимостей, которые можно включить в свое приложение. Это позволит получить универсальное решение для всех, связанных со Spring технологий, избавляя программиста от лишнего поиска примеров кода и загрузки из них требуемых дескрипторов зависимостей. Например, если вы хотите начать использовать Spring Data JPA для доступа к базе данных, просто включите в свой проект зависимость spring-boot-starter-data-jpa и все будет готово (вам не придется искать совместимые драйверы баз данных и библиотеки Hibernate)
Например, если вы добавите Spring-boot-starter-web, Spring Boot автоматически сконфигурирует такие зарегистрированные бины, как DispatcherServlet, ResourceHandlers, MessageSource. Если вы используете spring-boot-starter-jdbc, Spring Boot автоматически регистрирует бины DataSource, EntityManagerFactory, TransactionManager и считывает информацию для подключения к базе данных из файла application.properties
В основе "магии" Spring Boot нет ничего магического, он использует совершенно базовые понятия из Spring Framework. В кратком виде процесс можно описать так:
- Аннотация @SpringBootApplication включает сканирование компонентов и авто-конфигурацию через аннотацию @EnableAutoConfiguration
- @EnableAutoConfiguration импортирует класс EnableAutoConfigurationImportSelector
- EnableAutoConfigurationImportSelector загружает список конфигураций из файла META-INF/spring.factories
- Каждая конфигурация пытается сконфигурить различные аспекты приложения (web, JPA, AMQP etc), регистрируя нужные бины и используя различные условия (наличие / отсутствие бина, настройки, класса и т.п.)
- Созданный в итоге AnnotationConfigEmbeddedWebApplicationContext ищет в том же DI контейнере фабрику для запуска embedded servlet container
- Servlet container запускается, приложение готово к работе!
Важное понятие Spring Boot это автоконфигурация. По сути, это просто набор конфигурационных классов, которые создают и регистрируют определенные бины в приложении. По большому счету, даже сам Embedded Servlet Container — это просто еще один бин, который можно сконфигурировать! Пара важных моментов, которые важно знать об автоконфигурации:
- Включается аннотацией @EnableAutoConfiguration
- Работает в последнюю очередь, после регистрации пользовательских бинов
- Принимает решения о конфигурации на основании доступных в classpath классов, свойств в application.properties и т.п.
- Можно включать и выключать разные аспекты автоконфигурации, и применять ее частично (например, только MySQL + JPA, но не веб)
- Всегда отдает приоритет пользовательским бинам. Если ваш код уже зарегистрировал бин DataSource — автоконфигурация не будет его перекрывать
Логика при регистрации бинов управляется набором @ConditionalOn* аннотаций. Можно указать, чтобы бин создавался при наличии класса в classpath (@ConditionalOnClass), наличии существующего бина (@ConditionalOnBean), отсуствии бина (@ConditionalOnMissingBean) и т.п.
Отключить ненужные автоконфигурации можно при помощи свойств exclude и excludeName аннотаций @EnableAutoConfiguration, @ImportAutoConfiguration и @SpringBootApplication. Или в property задать SpringAutoconfiguration exclude и передать имена классов.
Можно отказаться от использования механизма автоконфигурации, вместо этого указывая необходимые автоконфигурации вручную. Для этого надо избавиться от аннотаций @SpringBootApplication и @EnableAutoConfiguration в коде вашего проекта, а для указания нужных конфигурационных классов использовать аннотации @SpringBootConfiguration и @ImportAutoConfiguration. Однако стоит помнить, что используемые автоконфигурации всё ещё могут содержать неиспользуемые компоненты.
Как происходит автоконфигурация в Spring Boot:
- Отмечаем main класс аннотацией @SpringBootApplication (аннотация инкапсулирует в себе:@SpringBootConfiguration, @ComponentScan, @EnableAutoConfiguration), таким образом наличие @SpringBootApplication включает сканирование компонентов, автоконфигурацию и показывает разным компонентам Spring (например, интеграционным тестам), что это Spring Boot приложение.
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}- @EnableAutoConfiguration импортирует класс EnableAutoConfigurationImportSelector. Этот класс не объявляет бины сам, а использует так называемые фабрики.
- Класс EnableAutoConfigurationImportSelector смотрит в файл META-INF/spring.factories и загружает оттуда список значений, которые являются именами классов (авто)конфигураций, которые Spring Boot импортирует. Т.е. аннотация @EnableAutoConfiguration просто импортирует ВСЕ (более 150) перечисленные в spring.factories конфигурации, чтобы предоставить нужные бины в контекст приложения.
- Каждая из этих конфигураций пытается сконфигурировать различные аспекты приложения(web, JPA, AMQP и т.д.), регистрируя нужные бины. Логика при регистрации бинов управляется набором @ConditionalOn* аннотаций. Можно указать, чтобы бин создавался при наличии класса в classpath (@ConditionalOnClass), наличии существующего бина (@ConditionalOnBean), отсуствии бина (@ConditionalOnMissingBean) и т.п. Таким образом наличие конфигурации не значит, что бин будет создан, и в большинстве случаев конфигурация ничего делать и создавать не будет.
- Созданный в итоге AnnotationConfigEmbeddedWebApplicationContext ищет в том же DI контейнере фабрику для запуска embedded servlet container.
- Servlet container запускается, приложение готово к работе!
Чтобы ускорить процесс управления зависимостями, Spring Boot неявно упаковывает необходимые сторонние зависимости для каждого типа приложения на основе Spring и предоставляет их разработчику посредством так называемых starter-пакетов. Starter-пакеты представляют собой набор удобных дескрипторов зависимостей, которые можно включить в свое приложение.
Делаем свой Starter-пакет:
- Создаем AutoConfiguration-класс, который Spring Boot находит при запуске приложения и использует для автоматического создания и конфигурирования бинов.
@Configuration //указываем, что наш класс является конфигурацией (@Configuration)
@ConditionalOnClass({SocialConfigurerAdapter.class, VKontakteConnectionFactory.class}) //означает, что бины будут создаваться при наличии в classpath SocialConfigurerAdapter и VKontakteConnectionFactory. Таким образом, без нужных для нашего стартера зависимостей бины создаваться не будут.
@ConditionalOnProperty(prefix= "ru.shadam.social-vkontakte", name = { "client-id", "client-secret"}) //означает, что бины будут создаваться только при наличии property ru.shadam.social-vkontakte.client-id и ru.shadam.social-vkontakte.client-secret.
@AutoConfigureBefore(SocialWebAutoConfiguration.class)
@AutoConfigureAfter(WebMvcAutoConfiguration.class) //означает, что наш бин будет инициализироваться после WebMvc и до SocialWeb. Это нужно, чтобы к моменту инициализации SocialWeb наши бины уже были зарегистрированы.
public class VKontakteAutoConfiguration {
}- Расширяем SocialConfigurationAdapter, который нужен для того чтобы зарегистрировать нашу ConnectionFactory. Для этого переопределяем метод addConnectionFactories(ConnectionFactoryConfigurer, Environment)
- Создание файла, позволяющего SpringBoot найти наш AutoConfiguration класс. Для этого существует специальный файл spring.factories, который нужно поместить в META-INF папку получающегося jar-файла. В этом файле нам надо указать наш AutoConfiguration-класс.
- Подключить получившийся jar-файл к Spring Boot проекту и задать в конфигурации пути на класс, который создали до этого.
@Value("${maxReadResults}")
private int maxReadResults;- Используется JDK 8+ (Optional, CompletableFuture, Time API, java.util.function, default methods)
- Поддержка Java 9 (Automatic-Module-Name in 5.0, module-info in 6.0+, ASM 6)
- Поддержка HTTP/2 (TLS, Push), NIO/NIO.2, Kotlin
- Поддержка Kotlin
- Реактивность (Web on Reactive Stack)
- Null-safety аннотации(@Nullable), новая документация
- Совместимость с Java EE 8 (Servlet 4.0, Bean Validation 2.0, JPA 2.2, JSON Binding API 1.0)
- Поддержка JUnit 5 + Testing Improvements (conditional and concurrent)
- Удалена поддержка: Portlet, Velocity, JasperReports, XMLBeans, JDO, Guava
Класс RestTemplate является центральным инструментом для выполнения клиентских HTTP-операций в Spring. Он предоставляет несколько утилитных методов для создания HTTP-запросов и обработки ответов.
JdbcTemplate - базовый класс, который управляет обработкой всех событий и связями с БД посредством sql запросов. При этом все пишется программистом, не автоматизированно.
Класс для двунаправленное соединением между клиентом и сервером. Например пользователь чатится с другим пользователем, сокет обрабатывает эти сообщения. Отвечает за создание соединения и пересылку данных.
Классы — это блоки, из которых строится приложение. Так же, как кирпичи в здании. Плохо написанные классы однажды могут принести проблемы.
SOLID — это акроним, образованный из заглавных букв первых пяти принципов ООП и проектирования. Принципы придумал Роберт Мартин в начале двухтысячных, а аббревиатуру позже ввел в обиход Майкл Фэзерс.
- Single Responsibility Principle (Принцип единственной ответственности)
- Open Closed Principle (Принцип открытости/закрытости)
- Liskov’s Substitution Principle (Принцип подстановки Барбары Лисков)
- Interface Segregation Principle (Принцип разделения интерфейса)
- Dependency Inversion Principle (Принцип инверсии зависимостей)
Данный принцип гласит: никогда не должно быть больше одной причины изменить класс.
На каждый объект возлагается одна обязанность, полностью инкапсулированная в класс. Все сервисы класса направлены на обеспечение этой обязанности.
Такие классы всегда будет просто изменять, если это понадобится, потому что понятно, за что класс отвечает, а за что — нет. То есть можно будет вносить изменения и не бояться последствий — влияния на другие объекты. А еще подобный код гораздо проще тестировать, ведь вы покрываете тестами одну функциональность в изоляции от всех остальных.
Представьте себе модуль, который обрабатывает заказы. Если заказ верно сформирован, он сохраняет его в базу данных и высылает письмо для подтверждения заказа:
public class OrderProcessor {
public void process(Order order){
if (order.isValid() && save(order)) {
sendConfirmationEmail(order);
}
}
private boolean save(Order order) {
MySqlConnection connection = new MySqlConnection("database.url");
// сохраняем заказ в базу данных
return true;
}
private void sendConfirmationEmail(Order order) {
String name = order.getCustomerName();
String email = order.getCustomerEmail();
// Шлем письмо клиенту
}
}Такой модуль может измениться по трем причинам. Во-первых может стать другой логика обработки заказа, во-вторых, способ его сохранения (тип базы данных), в-третьих — способ отправки письма подтверждения (скажем, вместо email нужно отправлять SMS).
Принцип единственной обязанности подразумевает, что три аспекта этой проблемы на самом деле — три разные обязанности. А значит, должны находиться в разных классах или модулях. Объединение нескольких сущностей, которые могут меняться в разное время и по разным причинам, считается плохим проектным решением.
Гораздо лучше разделить модуль на три отдельных, каждый из которых будет выполнять одну единственную функцию:
public class MySQLOrderRepository {
public boolean save(Order order) {
MySqlConnection connection = new MySqlConnection("database.url");
// сохраняем заказ в базу данных
return true;
}
}
public class ConfirmationEmailSender {
public void sendConfirmationEmail(Order order) {
String name = order.getCustomerName();
String email = order.getCustomerEmail();
// Шлем письмо клиенту
}
}
public class OrderProcessor {
public void process(Order order){
MySQLOrderRepository repository = new MySQLOrderRepository();
ConfirmationEmailSender mailSender = new ConfirmationEmailSender();
if (order.isValid() && repository.save(order)) {
mailSender.sendConfirmationEmail(order);
}
}
}Этот принцип емко описывают так: программные сущности (классы, модули, функции и т.п.) должны быть открыты для расширения, но закрыты для изменения.
Это означает, что должна быть возможность изменять внешнее поведение класса, не внося физические изменения в сам класс. Следуя этому принципу, классы разрабатываются так, чтобы для подстройки класса к конкретным условиям применения было достаточно расширить его и переопределить некоторые функции.
Поэтому система должна быть гибкой, с возможностью работы в переменных условиях без изменения исходного кода.
Продолжая наш пример с заказом, предположим, что нам нужно выполнять какие-то действия перед обработкой заказа и после отправки письма с подтверждением. Вместо того, чтобы менять сам класс OrderProcessor, мы расширим его и добьемся решения поставленной задачи, не нарушая принцип OCP:
public class OrderProcessorWithPreAndPostProcessing extends OrderProcessor {
@Override
public void process(Order order) {
beforeProcessing();
super.process(order);
afterProcessing();
}
private void beforeProcessing() {
// Осуществим некоторые действия перед обработкой заказа
}
private void afterProcessing() {
// Осуществим некоторые действия после обработки заказа
}
}Это вариация принципа открытости/закрытости, о котором говорилось ранее. Его можно описать так: объекты в программе можно заменить их наследниками без изменения свойств программы.
Это означает, что класс, разработанный путем расширения на основании базового класса, должен переопределять его методы так, чтобы не нарушалась функциональность с точки зрения клиента. То есть, если разработчик расширяет ваш класс и использует его в приложении, он не должен изменять ожидаемое поведение переопределенных методов.
Подклассы должны переопределять методы базового класса так, чтобы не нарушалась функциональность с точки зрения клиента. Подробно это можно рассмотреть на следующем примере.
Предположим у нас есть класс, который отвечает за валидацию заказа и проверяет, все ли из товаров заказа находятся на складе. У данного класса есть метод isValid который возвращает true или false:
public class OrderStockValidator {
public boolean isValid(Order order) {
for (Item item : order.getItems()) {
if (! item.isInStock()) {
return false;
}
}
return true;
}
}Также предположим, что некоторые заказы нужно валидировать иначе: проверять, все ли товары заказа находятся на складе и все ли товары упакованы. Для этого мы расширили класс OrderStockValidator классом OrderStockAndPackValidator:
public class OrderStockAndPackValidator extends OrderStockValidator {
@Override
public boolean isValid(Order order) {
for (Item item : order.getItems()) {
if ( !item.isInStock() || !item.isPacked() ){
throw new IllegalStateException(
String.format("Order %d is not valid!", order.getId())
);
}
}
return true;
}
}Однако в данном классе мы нарушили принцип LSP, так как вместо того, чтобы вернуть false, если заказ не прошел валидацию, наш метод бросает исключение IllegalStateException. Клиенты данного кода не рассчитывают на такое: они ожидают возвращения true или false. Это может привести к ошибкам в работе программы.
Характеризуется следующим утверждением: клиенты не должны быть вынуждены реализовывать методы, которые они не будут использовать.
Принцип разделения интерфейсов говорит о том, что слишком «толстые» интерфейсы необходимо разделять на более мелкие и специфические, чтобы клиенты мелких интерфейсов знали только о методах, необходимых в работе. В итоге, при изменении метода интерфейса не должны меняться клиенты, которые этот метод не используют.
Рассмотрим пример. Разработчик Алекс создал интерфейс "отчет" и добавил два метода: generateExcel() и generatedPdf(). Теперь клиент А хочет использовать этот интерфейс, но он намерен использовать отчеты только в PDF-формате, а не в Excel. Устроит ли его такая функциональность?
Нет. Он должен будет реализовать два метода, один из которых по большому счету не нужен и существует только благодаря Алексу — дизайнеру программного обеспечения. Клиент воспользуется либо другим интерфейсом, либо оставит поле для Excel пустым.
Так в чем же решение? Оно состоит в разделении существующего интерфейса на два более мелких. Один — отчет в формате PDF, второй — отчет в формате Excel. Это даст пользователю возможность использовать только необходимый для него функционал.
Этот принцип SOLID в Java описывают так: зависимости внутри системы строятся на основе абстракций. Модули верхнего уровня не зависят от модулей нижнего уровня. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Программное обеспечение нужно разрабатывать так, чтобы различные модули были автономными и соединялись друг с другом с помощью абстракции.
Классическое применение этого принципа — Spring framework. В рамках Spring framework все модули выполнены в виде отдельных компонентов, которые могут работать вместе. Они настолько автономны, что могут быть с такой же легкостью задействованы в других программных модулях помимо Spring framework.
Это достигнуто за счет зависимости закрытых и открытых принципов. Все модули предоставляют доступ только к абстракции, которая может использоваться в другом модуле.
Попробуем продемонстрировать это на примере. Говоря о принципе единственной ответственности, мы рассматривали некоторый OrderProcessor. Взглянем еще раз на код данного класса:
public class OrderProcessor {
public void process(Order order){
MySQLOrderRepository repository = new MySQLOrderRepository();
ConfirmationEmailSender mailSender = new ConfirmationEmailSender();
if (order.isValid() && repository.save(order)) {
mailSender.sendConfirmationEmail(order);
}
}
}В данном примере наш OrderProcessor зависит от двух конкретных классов MySQLOrderRepository и ConfirmationEmailSender. Приведем также код данных классов:
public class MySQLOrderRepository {
public boolean save(Order order) {
MySqlConnection connection = new MySqlConnection("database.url");
// сохраняем заказ в базу данных
return true;
}
}
public class ConfirmationEmailSender {
public void sendConfirmationEmail(Order order) {
String name = order.getCustomerName();
String email = order.getCustomerEmail();
// Шлем письмо клиенту
}
}Эти классы далеки от того, чтобы называться абстракциями. И с точки зрения принципа DIP было бы правильнее для начала создать некоторые абстракции, которые позволят нам оперировать в дальнейшем ими, а не конкретными реализациями. Создадим два интерфейса MailSender и OrderRepository, которые и станут нашими абстракциями:
public interface MailSender {
void sendConfirmationEmail(Order order);
}
public interface OrderRepository {
boolean save(Order order);
}Теперь имплементируем данные интерфейсы в уже готовых для этого классах:
public class ConfirmationEmailSender implements MailSender {
@Override
public void sendConfirmationEmail(Order order) {
String name = order.getCustomerName();
String email = order.getCustomerEmail();
// Шлем письмо клиенту
}
}
public class MySQLOrderRepository implements OrderRepository {
@Override
public boolean save(Order order) {
MySqlConnection connection = new MySqlConnection("database.url");
// сохраняем заказ в базу данных
return true;
}
}Мы провели подготовительную работу, чтобы наш класс OrderProcessor зависит не от конкретных деталей, а от абстракций. Внесем в него изменения, внедряя наши зависимости в конструкторе класса:
public class OrderProcessor {
private MailSender mailSender;
private OrderRepository repository;
public OrderProcessor(MailSender mailSender, OrderRepository repository) {
this.mailSender = mailSender;
this.repository = repository;
}
public void process(Order order){
if (order.isValid() && repository.save(order)) {
mailSender.sendConfirmationEmail(order);
}
}
}Теперь наш класс зависит от абстракций, а не от конкретных реализаций. Можно без труда менять его поведение, внедряя нужную зависимость в момент создания экземпляра OrderProcessor.
Паттерн — это проверенное и готовое к использованию решение. Это не класс и не библиотека, которую можно подключить к проекту, это нечто большее - он не зависит от языка программирования, не является законченным образцом, который может быть прямо преобразован в код и может быть реализован по-разному в разных языках программирования.
Плюсы использования паттернов:
- снижение сложности разработки за счёт готовых абстракций для решения целого класса проблем
- облегчение коммуникации между разработчиками, позволяя ссылаться на известные паттерны
- унификация деталей решений: модулей и элементов проекта
- возможность отыскав удачное решение, пользоваться им снова и снова
- помощь в выборе выбрать наиболее подходящего варианта проектирования
Минусы:
- слепое следование некоторому выбранному паттерну может привести к усложнению программы
- желание попробовать некоторый паттерн в деле без особых на то оснований
- все паттерны имеют уникальное имя, служащее для их идентификации
- назначение данного паттерн
- задача, которую паттерн позволяет решить
- способ, предлагаемый в паттерне для решения задачи в том контексте, где этот паттерн был найден
- сущности, принимающие участие в решении задачи
- последствия от использования паттерна как результат действий, выполняемых в паттерне
- возможный вариант реализации паттерна
- Основные (Fundamental) - основные строительные блоки других паттернов. Большинство других паттернов использует эти паттерны в той или иной форме
- Порождающие паттерны (Creational) — паттерны проектирования, которые абстрагируют процесс создание экземпляра. Они позволяют сделать систему независимой от способа создания, композиции и представления объектов. Паттерн, порождающий классы, использует наследование, чтобы изменять созданный объект, а паттерн, порождающий объекты, делегирует создание объектов другому объекту
- Структурные паттерны (Structural) определяют различные сложные структуры, которые изменяют интерфейс уже существующих объектов или его реализацию, позволяя облегчить разработку и оптимизировать программу
- Поведенческие паттерны (Behavioral) определяют взаимодействие между объектами, увеличивая таким образом его гибкость
- Делегирование (Delegation pattern) - Сущность внешне выражает некоторое поведение, но в реальности передаёт ответственность за выполнение этого поведения связанному объекту
- Функциональный дизайн (Functional design) - Гарантирует, что каждая сущность имеет только одну обязанность и исполняет её с минимумом побочных эффектов на другие
- Неизменяемый интерфейс (Immutable interface) - Создание неизменяемого объекта
- Интерфейс (Interface) - Общий метод структурирования сущностей, облегчающий их понимание
- Интерфейс-маркер (Marker interface) - В качестве атрибута (как пометки объектной сущности) применяется наличие или отсутствие реализации интерфейса-маркера. В современных языках программирования вместо этого применяются атрибуты или аннотации
- Контейнер свойств (Property container) - Позволяет добавлять дополнительные свойства сущности в контейнер внутри себя, вместо расширения новыми свойствами
- Канал событий (Event channel) - Создаёт централизованный канал для событий. Использует сущность-представитель для подписки и сущность-представитель для публикации события в канале. Представитель существует отдельно от реального издателя или подписчика. Подписчик может получать опубликованные события от более чем одной сущности, даже если он зарегистрирован только на одном канале
- Абстрактная фабрика (Abstract factory) - Класс, который представляет собой интерфейс для создания других классов
- Строитель (Builder) - Класс, который представляет собой интерфейс для создания сложного объекта
- Фабричный метод (Factory method) - Делегирует создание объектов наследникам родительского класса. Это позволяет использовать в коде программы не специфические классы, а манипулировать абстрактными объектами на более высоком уровне
- Прототип (Prototype) - Определяет интерфейс создания объекта через клонирование другого объекта вместо создания через конструктор
- Одиночка (Singleton) - Класс, который может иметь только один экземпляр
- Адаптер (Adapter) - Объект, обеспечивающий взаимодействие двух других объектов, один из которых использует, а другой предоставляет несовместимый с первым интерфейс
- Мост (Bridge) - Структура, позволяющая изменять интерфейс обращения и интерфейс реализации класса независимо
- Компоновщик (Composite) - Объект, который объединяет в себе объекты, подобные ему самому
- Декоратор (Decorator) - Класс, расширяющий функциональность другого класса без использования наследования
- Фасад (Facade) - Объект, который абстрагирует работу с несколькими классами, объединяя их в единое целое
- Приспособленец (Flyweight) - Это объект, представляющий себя как уникальный экземпляр в разных местах программы, но по факту не являющийся таковым
- Заместитель (Proxy) - Объект, который является посредником между двумя другими объектами, и который реализует/ограничивает доступ к объекту, к которому обращаются через него
- Цепочка обязанностей (Chain of responsibility) - Предназначен для организации в системе уровней ответственности
- Команда (Command) - Представляет действие. Объект команды заключает в себе само действие и его параметры
- Интерпретатор (Interpreter) - Решает часто встречающуюся, но подверженную изменениям, задачу
- Итератор (Iterator) - Представляет собой объект, позволяющий получить последовательный доступ к элементам объекта-агрегата без использования описаний каждого из объектов, входящих в состав агрегации
- Посредник (Mediator) - Обеспечивает взаимодействие множества объектов, формируя при этом слабую связанность и избавляя объекты от необходимости явно ссылаться друг на друга
- Хранитель (Memento) - Позволяет, не нарушая инкапсуляцию зафиксировать и сохранить внутренние состояния объекта так, чтобы позднее восстановить его в этих состояниях
- Наблюдатель (Observer) - Определяет зависимость типа «один ко многим» между объектами таким образом, что при изменении состояния одного объекта все зависящие от него оповещаются об этом событии
- Состояние (State) - Используется в тех случаях, когда во время выполнения программы объект должен менять своё поведение в зависимости от своего состояния
- Стратегия (Strategy) - Предназначен для определения семейства алгоритмов, инкапсуляции каждого из них и обеспечения их взаимозаменяемости
- Шаблонный метод (Template method) - Определяет основу алгоритма и позволяет наследникам переопределять некоторые шаги алгоритма, не изменяя его структуру в целом
- Посетитель (Visitor) - Описывает операцию, которая выполняется над объектами других классов. При изменении класса Visitor нет необходимости изменять обслуживаемые классы
Антипаттерн (anti-pattern) — это распространённый подход к решению класса часто встречающихся проблем, являющийся неэффективным, рискованным или непродуктивным.
Poltergeists (полтергейсты) - это классы с ограниченной ответственностью и ролью в системе, чьё единственное предназначение — передавать информацию в другие классы. Их эффективный жизненный цикл непродолжителен. Полтергейсты нарушают стройность архитектуры программного обеспечения, создавая избыточные (лишние) абстракции, они чрезмерно запутанны, сложны для понимания и трудны в сопровождении. Обычно такие классы задумываются как классы-контроллеры, которые существуют только для вызова методов других классов, зачастую в предопределенной последовательности.
Признаки появления и последствия антипаттерна:
- Избыточные межклассовые связи
- Временные ассоциации
- Классы без состояния (содержащие только методы и константы)
- Временные объекты и классы (с непродолжительным временем жизни)
- Классы с единственным методом, который предназначен только для создания или вызова других классов посредством временной ассоциации
- Классы с именами методов в стиле «управления», такие как startProcess
Типичные причины:
- Отсутствие объектно-ориентированной архитектуры (архитектор не понимает объектно-ориентированной парадигмы)
- Неправильный выбор пути решения задачи
- Предположения об архитектуре приложения на этапе анализа требований (до объектно-ориентированного анализа) могут также вести к проблемам на подобии этого антипаттерна
Внесенная сложность (Introduced complexity): Необязательная сложность дизайна. Вместо одного простого класса выстраивается целая иерархия интерфейсов и классов. Типичный пример «Интерфейс - Абстрактный класс - Единственный класс реализующий интерфейс на основе абстрактного».
Инверсия абстракции (Abstraction inversion): Сокрытие части функциональности от внешнего использования, в надежде на то, что никто не будет его использовать.
Неопределённая точка зрения (Ambiguous viewpoint): Представление модели без спецификации её точки рассмотрения.
Большой комок грязи (Big ball of mud): Система с нераспознаваемой структурой.
Божественный объект (God object): Концентрация слишком большого количества функций в одной части системы (классе).
Затычка на ввод данных (Input kludge): Забывчивость в спецификации и выполнении поддержки возможного неверного ввода.
Раздувание интерфейса (Interface bloat): Разработка интерфейса очень мощным и очень сложным для реализации.
Волшебная кнопка (Magic pushbutton): Выполнение результатов действий пользователя в виде неподходящего (недостаточно абстрактного) интерфейса. Например, написание прикладной логики в обработчиках нажатий на кнопку.
Перестыковка (Re-Coupling): Процесс внедрения ненужной зависимости.
Дымоход (Stovepipe System): Редко поддерживаемая сборка плохо связанных компонентов.
Состояние гонки (Race hazard): непредвидение возможности наступления событий в порядке, отличном от ожидаемого.
Членовредительство (Mutilation): Излишнее «затачивание» объекта под определенную очень узкую задачу таким образом, что он не способен будет работать с никакими иными, пусть и очень схожими задачами.
Сохранение или смерть (Save or die): Сохранение изменений лишь при завершении приложения.
Dependency Injection (внедрение зависимости) - это набор паттернов и принципов разработки програмного обеспечения, которые позволяют писать слабосвязный код. В полном соответствии с принципом единой обязанности объект отдаёт заботу о построении требуемых ему зависимостей внешнему, специально предназначенному для этого общему механизму
База данных — организованный и адаптированный для обработки вычислительной системой набор информации
Система управления базами данных (СУБД) - набор средств общего или специального назначения, обеспечивающий создание, доступ к материалам и управление базой данных.
Основные функции СУБД:
- управление данными
- журнализация изменений данных
- резервное копирование и восстановление данных
- поддержка языка определения данных и манипулирования ими
Реляционная модель данных — это логическая модель данных и прикладная теория построения реляционных баз данных. Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation), которая формально определяет свойства различных объектов и их взаимосвязи.
Реляционная модель данных включает в себя следующие компоненты:
- Структурный аспект — данные представляют собой набор отношений
- Аспект целостности — отношения отвечают определенным условиям целостности: уровня домена (типа данных), уровня отношения и уровня базы данных
- Аспект обработки (манипулирования) — поддержка операторов манипулирования отношениями (реляционная алгебра, реляционное исчисление)
- Нормальная форма - свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности и определённое как совокупность требований, которым должно удовлетворять отношение
Простой ключ состоит из одного атрибута (поля). Составной - из двух и более.
Потенциальный ключ - простой или составной ключ, который уникально идентифицирует каждую запись набора данных. При этом потенциальный ключ должен обладать критерием неизбыточности: при удалении любого из полей набор полей перестает уникально идентифицировать запись.
Из множества всех потенциальных ключей набора данных выбирают первичный ключ, все остальные ключи называют альтернативными.
Естественный Ключ – набор атрибутов описываемой записью сущности, уникально её идентифицирующий (например, номер паспорта для человека)
Суррогатный Ключ – автоматически сгенерированное поле, никак не связанное с информационным содержанием записи. Обычно в роли СК выступает автоинкрементное поле типа INTEGER.
Первичный ключ (primary key) уникальный идентификатор записи в табице. В реляционной модели данных один из потенциальных ключей отношения, выбранный в качестве основного ключа (ключа по умолчанию).
Если в отношении имеется единственный потенциальный ключ, он является и первичным ключом. Если потенциальных ключей несколько, один из них выбирается в качестве первичного, а другие называют «альтернативными».
В качестве первичного обычно выбирается тот из потенциальных ключей, который наиболее удобен. Поэтому в качестве первичного ключа, как правило, выбирают тот, который имеет наименьший размер (физического хранения) и/или включает наименьшее количество атрибутов. Другой критерий выбора первичного ключа — сохранение его уникальности со временем. Поэтому в качестве первичного ключа стараются выбирать такой потенциальный ключ, который с наибольшей вероятностью никогда не утратит уникальность.
Внешний ключ (foreign key) — подмножество атрибутов некоторого отношения A, значения которых должны совпадать со значениями некоторого потенциального ключа некоторого отношения B.
Внешние ключи позволяют установить связи между таблицами. Внешний ключ устанавливается для столбцов из зависимой, подчиненной таблицы, и указывает на один из столбцов из главной таблицы. Как правило, внешний ключ указывает на первичный ключ из связанной главной таблицы
Нормализация - процесс замены исходной схемы другой схемой, в которой наборы данных имеют более простую и логичную структуру.
Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную логическую избыточность, и не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение физического объёма базы данных. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в базе данных информации.
Первая нормальная форма (1NF) - Отношение находится в 1NF, если значения всех его атрибутов атомарны (неделимы).
- В каждой ячейке таблицы должно находиться только 1 значение.
- Строки не должны повторяться
Вторая нормальная форма (2NF) - Отношение находится в 2NF, если оно находится в 1NF, и при этом все неключевые атрибуты зависят только от ключа целиком, а не от какой-то его части. Чтобы привести таблицу в 2NF необходимо ее декомпозировать на несколько зависящих друг от друга.
- Таблица в 1NF.
- Все атрибуты зависят целиком от primary key,а не от его части.
Третья нормальная форма (3NF) - Отношение находится в 3NF, если оно находится в 2NF и все неключевые атрибуты не зависят друг от друга.
- Таблица в 2NF.
- Все атрибуты зависят только от primary key, но не от других атрибутов.
Четвёртая нормальная форма (4NF) - Отношение находится в 4NF , если оно находится в 3NF и если в нем не содержатся независимые группы атрибутов, между которыми существует отношение «многие-ко-многим».
- Таблица в 3NF.
- Ключевые атрибуты не должны зависеть от неключевых.
Пятая нормальная форма (5NF) - Отношение находится в 5NF, когда каждая нетривиальная зависимость соединения в ней определяется потенциальным ключом (ключами) этого отношения.
Шестая нормальная форма (6NF) - Отношение находится в 6NF, когда она удовлетворяет всем нетривиальным зависимостям соединения, т.е. когда она неприводима, то есть не может быть подвергнута дальнейшей декомпозиции без потерь. Каждая переменная отношения, которая находится в 6NF, также находится и в 5NF. Введена как обобщение пятой нормальной формы для хронологической базы данных.
Нормальная форма Бойса-Кодда, усиленная 3 нормальная форма (BCNF) - Отношение находится в BCNF, когда каждая её нетривиальная и неприводимая слева функциональная зависимость имеет в качестве своего детерминанта некоторый потенциальный ключ.
Доменно-ключевая нормальная форма (DKNF) - Отношение находится в DKNF, когда каждое наложенное на неё ограничение является логическим следствием ограничений доменов и ограничений ключей, наложенных на данное отношение.
Денормализация базы данных — это процесс осознанного приведения базы данных к виду, в котором она не будет соответствовать правилам нормализации. Обычно это необходимо для повышения производительности и скорости извлечения данных, за счет увеличения избыточности данных.
-
One-To-One (Один-К-Одному) - любому значению атрибута А соответствует только одно значение атрибута В, и наоборот.
Каждый университет гарантированно имеет 1-го ректора: 1 университет → 1 ректор. -
One-To-Many (Один-Ко-Многим) - любому значению атрибута А соответствует 0, 1 или несколько значений атрибута В.
В каждом университете есть несколько факультетов: 1 университет → много факультетов. -
Many-To-One (Многие-К-Одному) - связь многие к одному, обратная связь для OneToMany
Многие университеты находятся в одном городе. -
Many-To-Many (Многие-Ко-Многим) - любому значению атрибута А соответствует 0, 1 или несколько значений атрибута В, и любому значению атрибута В соответствует 0, 1 или несколько значение атрибута А.
1 профессор может преподавать на нескольких факультетах, в то же время на 1-ом факультете может преподавать несколько профессоров: Несколько профессоров - Несколько факультетов.
Каждую из которых можно разделить еще на два вида:
- Bidirectional (пер. - Двунаправленный) - две связи
- Unidirectional (пер. - Однонаправленный ) — ссылка на связь устанавливается у всех Entity, то есть в случае OneToOne A-B в Entity A есть ссылка на Entity B, в Entity B есть ссылка на Entity A, Entity A считается владельцем этой связи (это важно для случаев каскадного удаления данных, тогда при удалении A также будет удалено B, но не наоборот).Unidirectional - ссылка на связь устанавливается только с одной стороны, то есть в случае OneToOne A-B только у Entity A будет ссылка на Entity B, у Entity B ссылки на A не будет.
Индекс (index) — объект базы данных (отдельная таблица), создаваемый с целью повышения производительности выборки данных. Как закладка у книги.
Наборы данных могут иметь большое количество записей, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра набора данных запись за записью может занимать много времени. Индекс формируется из значений одного или нескольких полей и указателей на соответствующие записи набора данных, - таким образом, достигается значительный прирост скорости выборки из этих данных.
CREATE INDEX имя_индекса ON имя_таблицы;Преимущества:
- ускорение поиска и сортировки по определенному полю или набору полей.
- обеспечение уникальности данных.
Недостатки:
- требование дополнительного места на диске и в оперативной памяти и чем больше/длиннее ключ, тем больше размер индекса.
- замедление операций вставки, обновления и удаления записей, поскольку при этом приходится обновлять сами индексы.
Индексы предпочтительней для:
- Поля-счетчика, чтобы в том числе избежать и повторения значений в этом поле;
- Поля, по которому проводится сортировка данных;
- Полей, по которым часто проводится соединение наборов данных. Поскольку в этом случае данные располагаются в порядке возрастания индекса и соединение происходит значительно быстрее;
- Поля, которое объявлено первичным ключом (primary key);
- Поля, в котором данные выбираются из некоторого диапазона. В этом случае как только будет найдена первая запись с нужным значением, все последующие значения будут расположены рядом.
Использование индексов нецелесообразно для:
- Полей, которые редко используются в запросах;
- Полей, которые содержат всего два или три значения, например: мужской, женский пол или значения «да», «нет».
По порядку сортировки:
- упорядоченные — индексы, в которых элементы упорядочены
- возрастающие
- убывающие
- неупорядоченные — индексы, в которых элементы неупорядочены
По источнику данных:
- индексы по представлению (view)
- индексы по выражениям
По воздействию на источник данных:
- кластерный индекс - при определении в наборе данных физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура набора данных в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту. Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными
- некластерный индекс — наиболее типичные представители семейства индексов. В отличие от кластерных, они не перестраивают физическую структуру набора данных, а лишь организуют ссылки на соответствующие записи. Для идентификации нужной записи в наборе данных некластерный индекс организует специальные указатели, включающие в себя: информацию об идентификационном номере файла, в котором хранится запись; идентификационный номер страницы соответствующих данных; номер искомой записи на соответствующей странице; содержимое столбца
По структуре:
- B*-деревья
- B+-деревья
- B-деревья
- Хэши
По количественному составу:
- простой индекс (индекс с одним ключом) — строится по одному полю
- составной (многоключевой, композитный) индекс — строится по нескольким полям при этом важен порядок их следования
- индекс с включенными столбцами — некластеризованный индекс, дополнительно содержащий кроме ключевых столбцов еще и неключевые
- главный индекс (индекс по первичному ключу) — это тот индексный ключ, под управлением которого в данный момент находится набор данных. Набор данных не может быть отсортирован по нескольким индексным ключам одновременно. Хотя, если один и тот же набор данных открыт одновременно в нескольких рабочих областях, то у каждой копии набора данных может быть назначен свой главный индекс
По характеристике содержимого:
- уникальный индекс состоит из множества уникальных значений поля
- плотный индекс (NoSQL) — индекс, при котором, каждом документе в индексируемой коллекции соответствует запись в индексе, даже если в документе нет индексируемого поля
- разреженный индекс (NoSQL) — тот, в котором представлены только те документы, для которых индексируемый ключ имеет какое-то определённое значение (существует)
- пространственный индекс — оптимизирован для описания географического местоположения. Представляет из себя многоключевой индекс состоящий из широты и долготы
- составной пространственный индекс — индекс, включающий в себя кроме широты и долготы ещё какие-либо мета-данные (например теги). Но географические координаты должны стоять на первом месте
- полнотекстовый (инвертированный) индекс — словарь, в котором перечислены все слова и указано, в каких местах они встречаются. При наличии такого индекса достаточно осуществить поиск нужных слов в нём и тогда сразу же будет получен список документов, в которых они встречаются
- хэш-индекс предполагает хранение не самих значений, а их хэшей, благодаря чему уменьшается размер (а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием хэш-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей. Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». Кроме того, так как хэши не уникальны, то для совпадающих хэшей применяются методы разрешения коллизий
- битовый индекс (bitmap index) — метод битовых индексов заключается в создании отдельных битовых карт (последовательностей 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует запись с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства
- обратный индекс (reverse index) — B-tree индекс, но с реверсированным ключом, используемый в основном для монотонно возрастающих значений (например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска
- функциональный индекс, индекс по вычисляемому полю (function-based index) — индекс, ключи которого хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД
- первичный индекс — уникальный индекс по полю первичного ключа
- вторичный индекс — индекс по другим полям (кроме поля первичного ключа)
- XML-индекс — вырезанное материализованное представление больших двоичных XML-объектов (BLOB) в столбце с типом данных xml
По механизму обновления:
- полностью перестраиваемый — при добавлении элемента заново перестраивается весь индекс
- пополняемый (балансируемый) — при добавлении элементов индекс перестраивается частично (например одна из ветви) и периодически балансируется
По покрытию индексируемого содержимого:
- полностью покрывающий (полный) индекс — покрывает всё содержимое индексируемого объекта
- частичный индекс (partial index) — это индекс, построенный на части набора данных, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса
- инкрементный (delta) индекс — индексируется малая часть данных(дельта), как правило, по истечении определённого времени. Используется при интенсивной записи. Например, полный индекс перестраивается раз в сутки, а дельта-индекс строится каждый час. По сути это частичный индекс по временной метке
- индекс реального времени (real-time index) — особый вид инкрементного индекса, характеризующийся высокой скоростью построения. Предназначен для часто меняющихся данных
Индексы в кластерных системах:
- глобальный индекс — индекс по всему содержимому всех сегментов БД (shard)
- сегментный индекс — глобальный индекс по полю-сегментируемому ключу (shard key). Используется для быстрого определения сегмента, на котором хранятся данные в процессе маршрутизации запроса в кластере БД
- локальный индекс — индекс по содержимому только одного сегмента БД
Некластерные индексы - данные физически расположены в произвольном порядке, но логически упорядочены согласно индексу. Такой тип индексов подходит для часто изменяемого набора данных.
При кластерном индексировании данные физически упорядочены, что серьезно повышает скорость выборок данных (но только в случае последовательного доступа к данным). Для одного набора данных может быть создан только один кластерный индекс.
Примерное правило, которым можно руководствоваться при создании индекса - если объем информации (в байтах) НЕ удовлетворяющей условию выборки меньше, чем размер индекса (в байтах) по данному условию выборки, то в общем случае оптимизация приведет к замедлению выборки.
Полное сканирование производится многоблочным чтением. Сканирование по индексу - одноблочным. Также, при доступе по индексу сначала идет сканирование самого индекса, а затем чтение блоков из набора данных. Число блоков, которые надо при этом прочитать из набора зависит от фактора кластеризации. Если суммарная стоимость всех необходимых одноблочных чтений больше стоимости полного сканирования многоблочным чтением, то полное сканирование выгоднее и оно выбирается оптимизатором.
Таким образом, полное сканирование выбирается при слабой селективности предикатов зароса и/или слабой кластеризации данных, либо в случае очень маленьких наборов данных.
Транзакция - это воздействие на базу данных, переводящее её из одного целостного состояния в другое и выражаемое в изменении данных, хранящихся в базе данных.
Требования, для наиболее эфективной и безопасной работы транзакций.
Атомарность (atomicity) гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной.
Согласованность (consistency) требование, подразумевающее, что в результате работы транзакции данные будут допустимыми. Это вопрос не технологии, а бизнес-логики: например, если количество денег на счете не может быть отрицательным, логика транзакции должна проверять, не выйдет ли в результате отрицательных значений.
Изолированность (isolation). Во время выполнения транзакции параллельные транзакции не должны оказывать влияние на её результат.
Долговечность (durability). Независимо от проблем на нижних уровнях изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу. Другими словами, если пользователь получил подтверждение от системы, что транзакция выполнена, он может быть уверен, что сделанные им изменения не будут отменены из-за какого-либо сбоя.
В порядке увеличения изолированности транзакций и, соответственно, надёжности работы с данными:
- Чтение незавершенных транзакций (read uncommitted) — чтение незафиксированных изменений как своей транзакции, так и параллельных транзакций. Если несколько параллельных транзакций пытаются изменять одну и ту же строку таблицы, то в окончательном варианте строка будет иметь значение, определенное всем набором успешно выполненных транзакций. Гарантирует только отсутствие потерянных обновлений.
Типичный способ реализации данного уровня изоляции — блокировка данных на время выполнения команды изменения, что гарантирует, что команды изменения одних и тех же строк, запущенные параллельно, фактически выполнятся последовательно, и ни одно из изменений не потеряется. Транзакции, выполняющие только чтение, при данном уровне изоляции никогда не блокируются.
- Чтение завершенных транзакций (read committed) — На этом уровне обеспечивается защита от чернового, «грязного» чтения, тем не менее, в процессе работы одной транзакции другая может быть успешно завершена и сделанные ею изменения зафиксированы. В итоге первая транзакция будет работать с другим набором данных. По умолчанию в MySql и PostgreSQL
Работает либо через Блокирование читаемых и изменяемых данных, т.е. пишущая транзакция блокирует изменяемые данные для читающих транзакций, работающих на уровне read committed или более высоком, до своего завершения, препятствуя, таким образом, «грязному» чтению, а данные, блокируемые читающей транзакцией, освобождаются сразу после завершения операции SELECT (таким образом, ситуация «неповторяющегося чтения» может возникать на данном уровне изоляции).
Либо Сохранение нескольких версий параллельно изменяемых строк, т.е. при каждом изменении строки СУБД создаёт новую версию этой строки, с которой продолжает работать изменившая данные транзакция, в то время как любой другой «читающей» транзакции возвращается последняя зафиксированная версия. Преимущество такого подхода в том, что он обеспечивает бо́льшую скорость, так как предотвращает блокировки. Однако он требует, по сравнению с первым, существенно бо́льшего расхода оперативной памяти, которая тратится на хранение версий строк. Кроме того, при параллельном изменении данных несколькими транзакциями может создаться ситуация, когда несколько параллельных транзакций произведут несогласованные изменения одних и тех же данных (поскольку блокировки отсутствуют, ничто не помешает это сделать). Тогда та транзакция, которая зафиксируется первой, сохранит свои изменения в основной БД, а остальные параллельные транзакции окажется невозможно зафиксировать (так как это приведёт к потере обновления первой транзакции). Единственное, что может в такой ситуации СУБД — это откатить остальные транзакции и выдать сообщение об ошибке «Запись уже изменена».
- Повторяемость чтения (repeatable read) — Уровень, при котором читающая транзакция «не видит» изменения данных, которые были ею ранее прочитаны. При этом никакая другая транзакция не может изменять данные, читаемые текущей транзакцией, пока та не оконч