

This library provides Arrow and Task implementations in two flavors:
arrows-stdlib: built on top of the Scala Future, without external dependencies. This module also provides ScalaJS artifacts.
libraryDependencies ++= Seq(
"io.trane" %% "arrows-stdlib" % "0.1.23"
)
arrows-twitter: built on top of the Twitter Future with the twitter-util dependency.
libraryDependencies ++= Seq(
"io.trane" %% "arrows-twitter" % "0.1.23"
)
Both implementations have similar behavior, but they mirror the interface of the underlying Future to make the migration easier.
The Arrow and Task implementations are inspired by the paper Generalizing Monads to Arrows, which introduces Arrows as a way to express computations statically. For instance, this monadic computation:
import com.twitter.util.Future
def callServiceA(i: Int) = Future.value(i * 2) // replace by service call
def callServiceB(i: Int) = Future.value(i + 1) // replace by service call
callServiceA(1).flatMap { r =>
callServiceB(r)
}can't be fully inspected statically. It's possible to determine that callServiceA will be invoked, but only after running callServiceA it's possible to identify that callServiceB will be invoked since there's a data dependency.
Arrows are functions that can be composed and reused for multiple executions:
import arrows.twitter._
val callServiceA = Arrow[Int].map(_ * 2) // replace by service call
val callServiceB = Arrow[Int].map(_ + 1) // replace by service call
val myArrow: Arrow[Int, Int] =
callServiceA.andThen(callServiceB)
val result: Future[Int] = myArrow.run(1)The paper also introduces the first operator to deal with scenarios like branching where expressing the computation using Arrows is challenging. It's an interesting technique that simulates a flatMap using tuples and joins/zips, but introduces considerable code complexity.
This library takes a different approach. Instead of avoiding flatMaps, it introduces a special case of Arrow called Task, which is a regular monad. Task is based on ArrowApply also introduced by the paper.
Users can easily express computations that are static using arrows and apply them within flatMap functions to produce Tasks:
val myArrow =
callServiceA.flatMap {
case 0 => Task.value(0)
case i => callServiceB(i)
}
val result: Future[Int] = myArrow.run(1)It's a mixed approach: computations that can be easily expressed statically don't need flatMap and Task, which are normally most of the cases. Only the portion of the computations that require some dynamicity needs to incur the price of using flatMap and Task.
Task is an Arrow without inputs. It's declared as a type alias:
type Task[+T] = Arrow[Unit, T]Additionally, it has a companion object that has methods similar to the ones provided by Future.
Static computations expressed using Arrows have better performance since they avoid many allocations at runtime, but Task can also be as a standalone solution without using Arrow directly. It's equivalent to the IO and Task implementations provided by libraries like Monix, Scalaz 8, and Cats Effect.
Unlike Task, Arrow's' companion object has only a few methods to create new instances. Arrows can be created based on an initial identity arrow through Arrow.apply:
val identityArrow: Arrow[Int, Int] = Arrow[Int]The identity arrow just returns its input, but is useful as a starting point to compose new arrows:
val stringify: Arrow[Int, String] = Arrow[Int].map(_.toString)Additionally, Arrow provides an apply method that produces a Task, which is the expected return type of a flatMap function:
val nonZeroStringify: Arrow[Int, String] =
Arrow[Int].flatMap {
case i if i < 0 => Task.value("")
case i => stringify(i)
}An interesting scenario is recursion with Arrow. For this purpose, it's possible to use Arrow.recursive:
val sum =
Arrow.recursive[List[Int], Int] { self =>
Arrow[List[Int]].flatMap {
case Nil => Task.value(0)
case head :: tail => self(tail).map(_ + head)
}
}Note that self is a reference to the Arrow under creation.
Once the arrow is created, it can be reused for multiple runs:
val result1: Future[Int] = sum.run(List(1, 2))
val result2: Future[Int] = sum.run(List(1, 2, 4))For best performance, keep arrows as vals in a scope that allows reuse
Task can be used as a standalone solution similar to the IO and Task implementations in libraries like Monix, Scalaz 8, and Cats Effect. Their interface mirror the interface of the underlying Future.
Even though Task is similar to Future, it has a different execution mechanism. Futures are strict and start to execute once created. Task only describes a computation that will eventually execute when executed:
val f = Future.value(1).map(println) // prints 1 immediately
val t = Task.value(1).map(println) // doesn't print anything during Task creation
t.run // prints 1Tricks like saving Futures with vals for parallelism doesn't work with Task:
val f1: Future[Int] = Future.value(1) // replace by an async op
val f2: Future[Int] = Future.value(2) // replace by an async op
// at this point both futures are running in parallel, even though
// the second future is only used within the `flatMap` function:
f1.flatMap { i =>
f2.map(_ + i)
}
val t1: Task[Int] = Future.value(1) // replace by an async op
val t2: Task[Int] = Future.value(2) // replace by an async op
// at this point t1 and t2 are not running, so t2 will only run
// when t1 finishes and the `flatMap` function is called:
t1.flatMap { i =>
t2.map(_ + i)
}
The arrows-benchmark sub-project has a set of benchmarks that compare this library to other similar solutions.
Instead of benchmarking specific features in isolation, these benchmarks generate a long chain of transformations using different types of operations like async boundaries, flatMaps, etc. This approach tries to simulate how the implementations would behave in a real-world scenario. Benchmarks that only test one or two operations in isolation are skewed since they make the work of the JIT (Just In Time Compiler) much easier, which is something that rarely happens in practice.
For instance, if only one or two operations are used, it's possible that only one of two implementations of a class are loaded so the JIT can easily compile to native code using monomorphic or bimorphic calls, which are much more efficient. Once the benchmark involves more than two operations, the JIT might have to use megamorphic calls. The same happens with other JIT optimizations like inlining and dead code elimination.
The benchmarks can be executed using a shell script:
arrows> ./benchmark.sh
It'll output the results and csv files for them.
All benchmarks are based on the same mechanism that generates transformation chains, but they have different parameters that determine the kind of operations to be used. Currently, there are four classes with different configurations:
| Class | Async boundaries | Failures | Error handling | Map | FlatMap |
|---|---|---|---|---|---|
SyncSuccessOnlyBenchmarks |
X | X | |||
SyncWithFailuresBenchmarks |
X | X | X | X | |
AsyncSuccessOnlyBenchmarks |
X | X | X | ||
AsyncWithFailuresBenchmarks |
X | X | X | X | X |
It's easy to create new benchmarks with a different configurations. Please feel free to submit a pull request if you'd like to benchmark other combinations of operations.
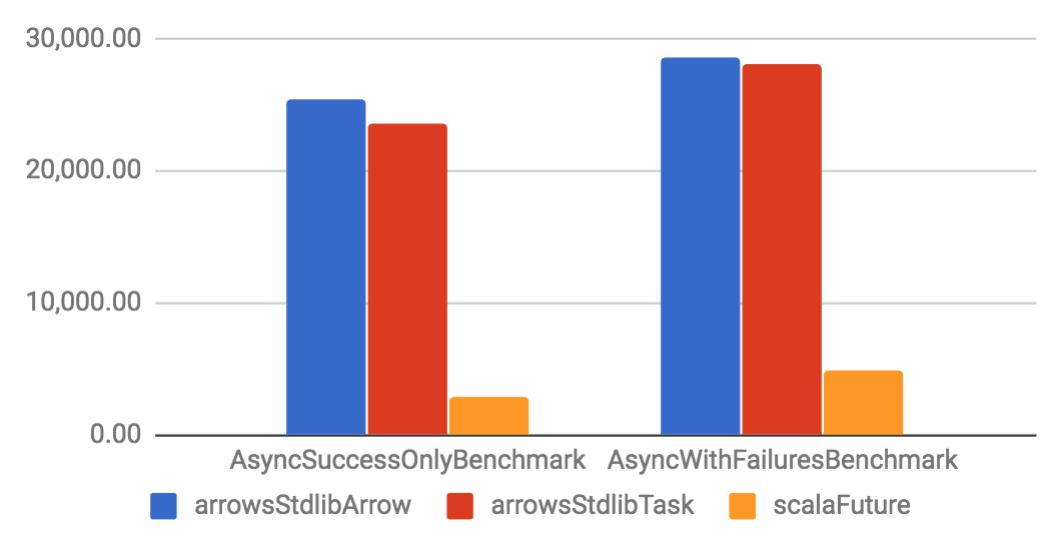
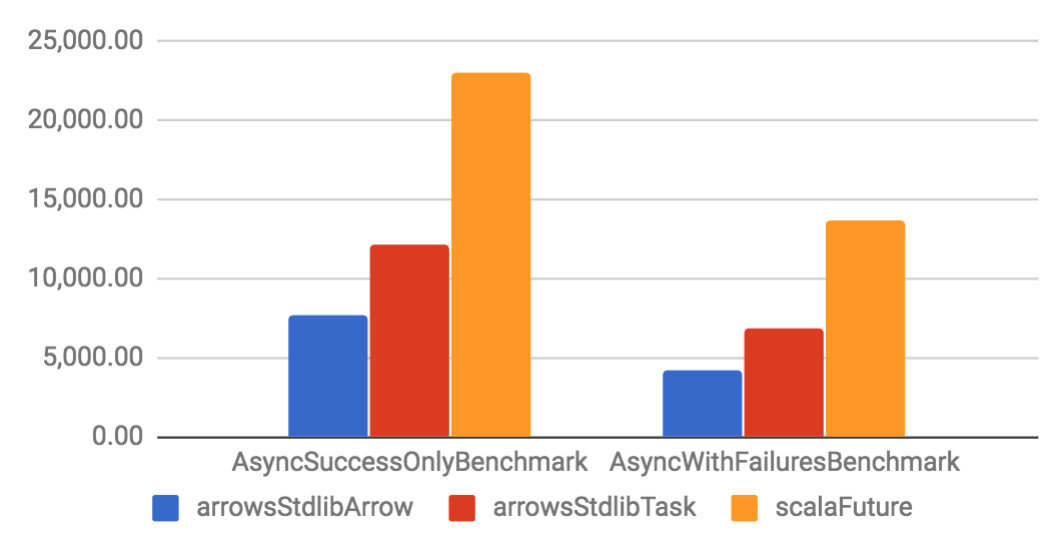
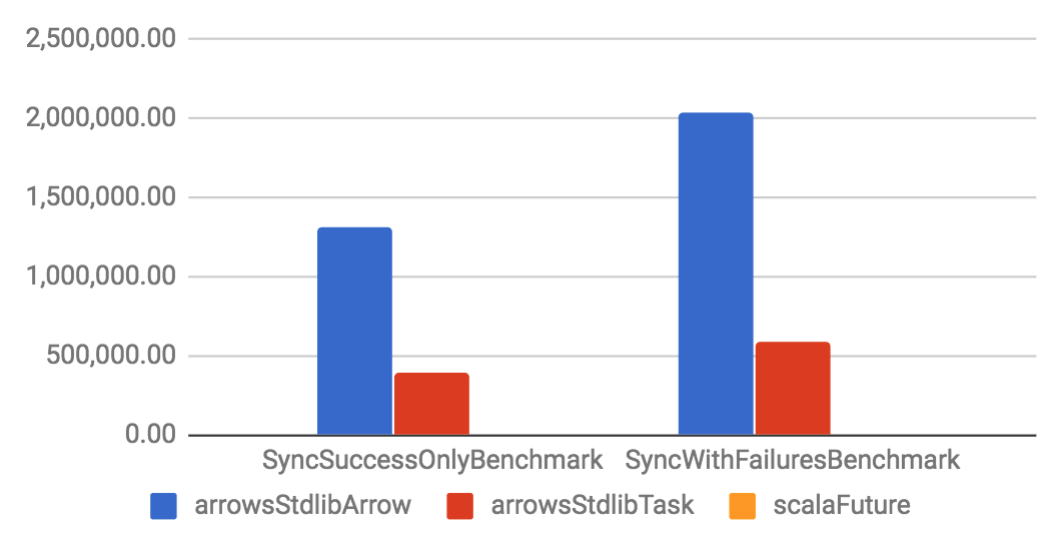
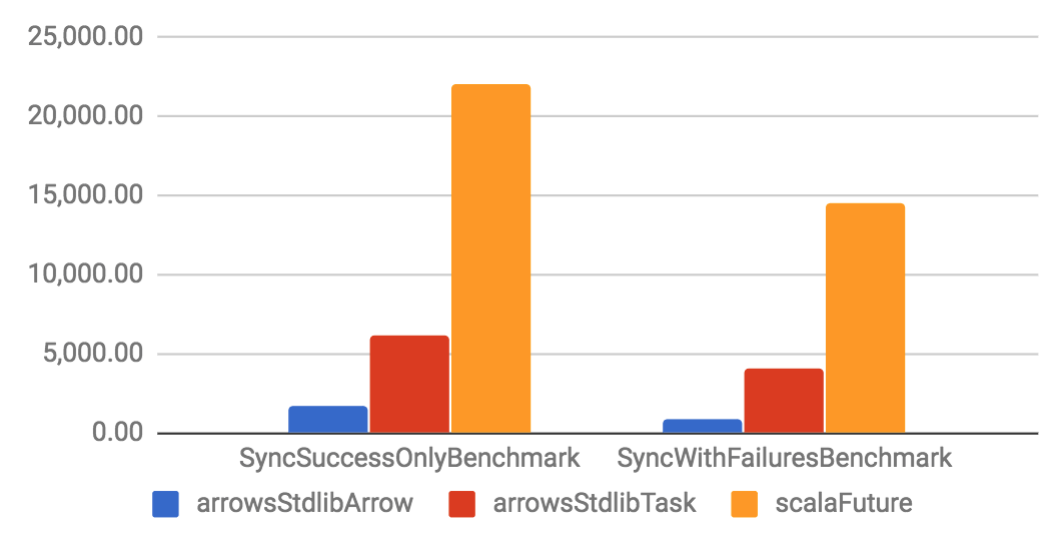
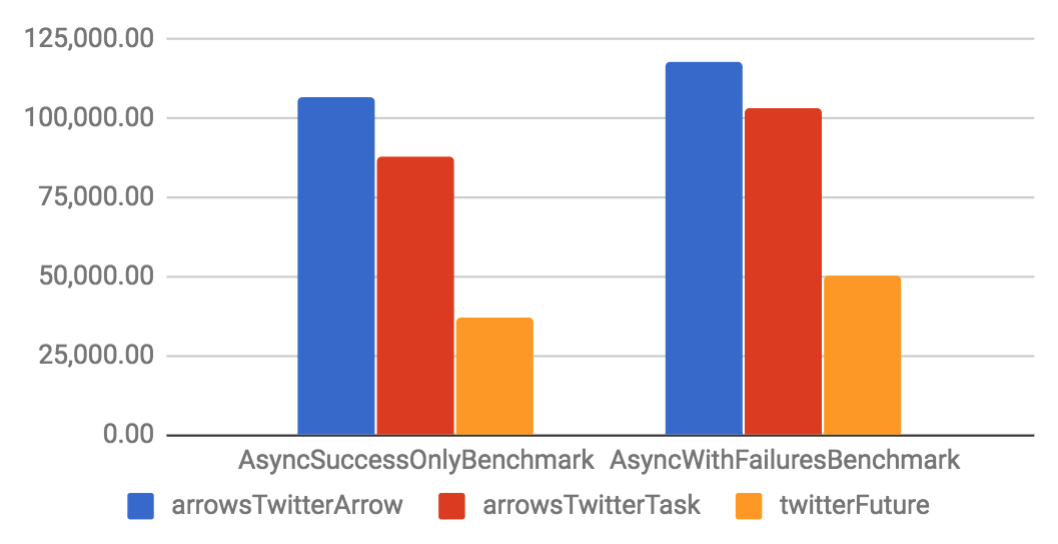
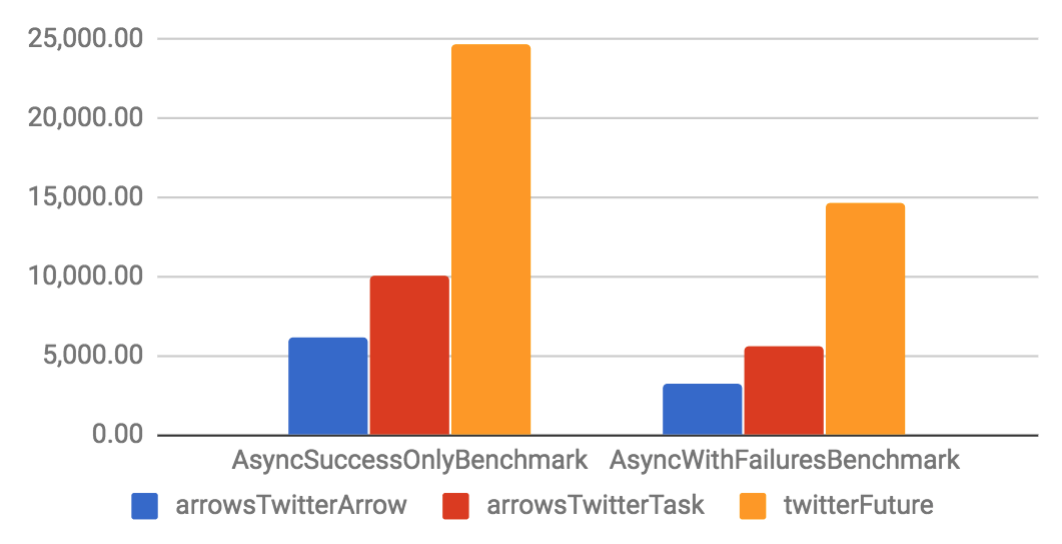
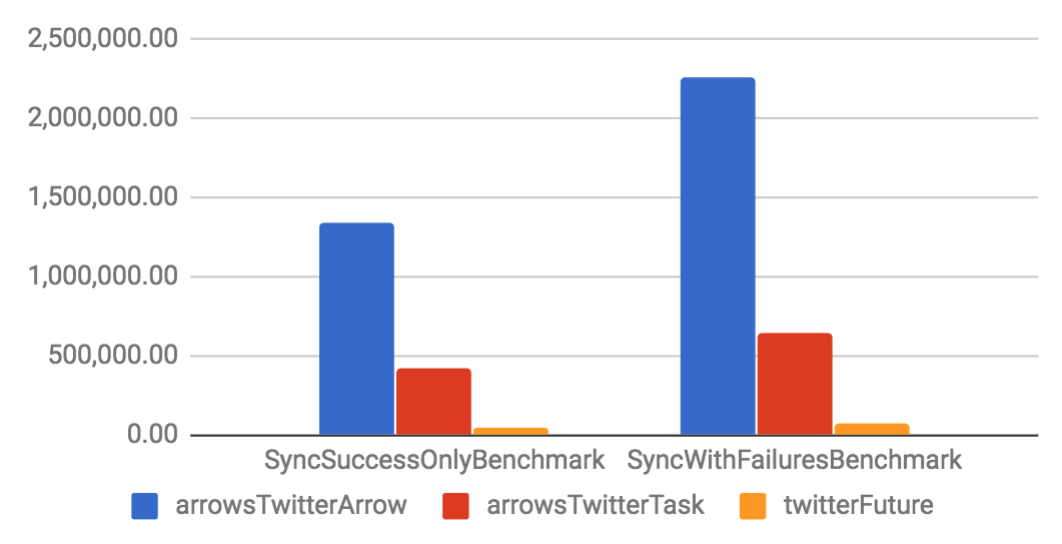
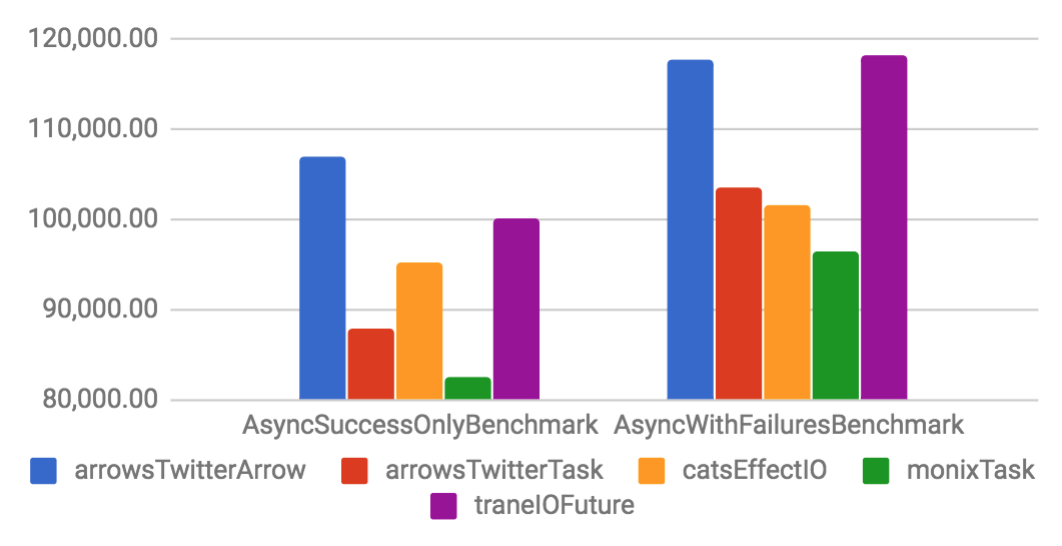
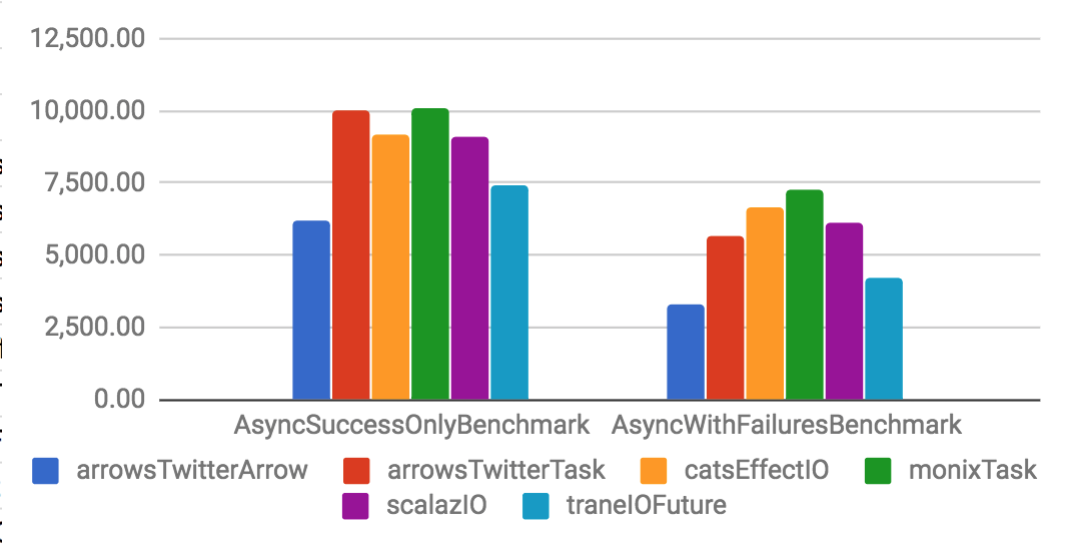
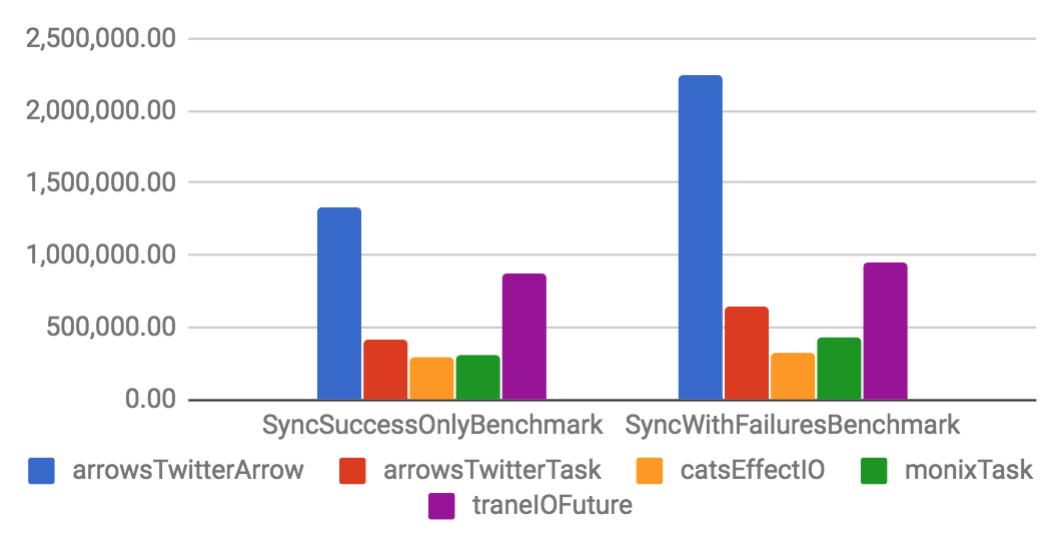
Arrow and Task are implemented on top of a specific Future. They have considerable better throughput and smaller memory footprint if compared to their Future counterparts. When compared to other libraries, Arrow tends to have better performance than other solutions, but Task is only slightly better. That happens because the other libraries are also well optimized.
Async benchmarks
| Throughput (ops/s) | Allocation rate (B/op) |
|---|---|
 |
 |
Sync benchmarks
| Throughput (ops/s) | Allocation rate (B/op) |
|---|---|
 |
 |
Async benchmarks
| Throughput (ops/s) | Allocation rate (B/op) |
|---|---|
 |
 |
Sync benchmarks
| Throughput (ops/s) | Allocation rate (B/op) |
|---|---|
 |
 |
Async benchmarks
| Throughput (ops/s) | Allocation rate (B/op) |
|---|---|
 |
 |
Sync benchmarks
| Throughput (ops/s) | Allocation rate (B/op) |
|---|---|
 |
 |
Given that Task has an interface similar to Future, it's possible to use Scalafix to do most of the migration. Suggested steps:
See the Scalafix documentation for all installation options. An easy way is adding the scalafix plugin to your sbt configuration:
echo -e '\n\n addSbtPlugin("ch.epfl.scala" % "sbt-scalafix" % "0.5.10")' >> project/plugins.sbt# for the Twitter Future
sbt -J-XX:MaxMetaspaceSize=512m 'scalafixCli --rules replace:com.twitter.util.Future/arrows.twitter.Task
# for the Scala Future
sbt -J-XX:MaxMetaspaceSize=512m 'scalafixCli --rules replace:scala.concurrent.Future/arrows.stdlib.TaskThe metaspace option is important to run Scalafix since SBT's default is too low.
Look for places where the change from strict to lazy might change the behavior. See the "Using Task" section to understand the difference.
At this point, it's reasonable to pause the migration and test the system to find potential issues with the migration.
There are deprecated implicit conversions from/to Arrow/Future. They were introduced to make the migration easier. Fix the deprecation warnings by calling the conversion methods directly and making sure that Futures are created within the Task execution, not outside.
As an additional step for even better performance, identify methods that can become Arrows and convert them.
- @fwbrasil (creator)
- @vkostyukov
- you? :)
Please note that this project is released with a Contributor Code of Conduct. By participating in this project, you agree to abide by its terms. See CODE_OF_CONDUCT.md for details.
See the LICENSE file for details.