
Evaluation abstraction for Keras models. Example Notebook
Requires keras-model-specs. We support python 3+.
probs, labels = evaluator.evaluate(data_dir=data_dir, top_k=2, confusion_matrix=True, save_confusion_matrix_path='cm.png')
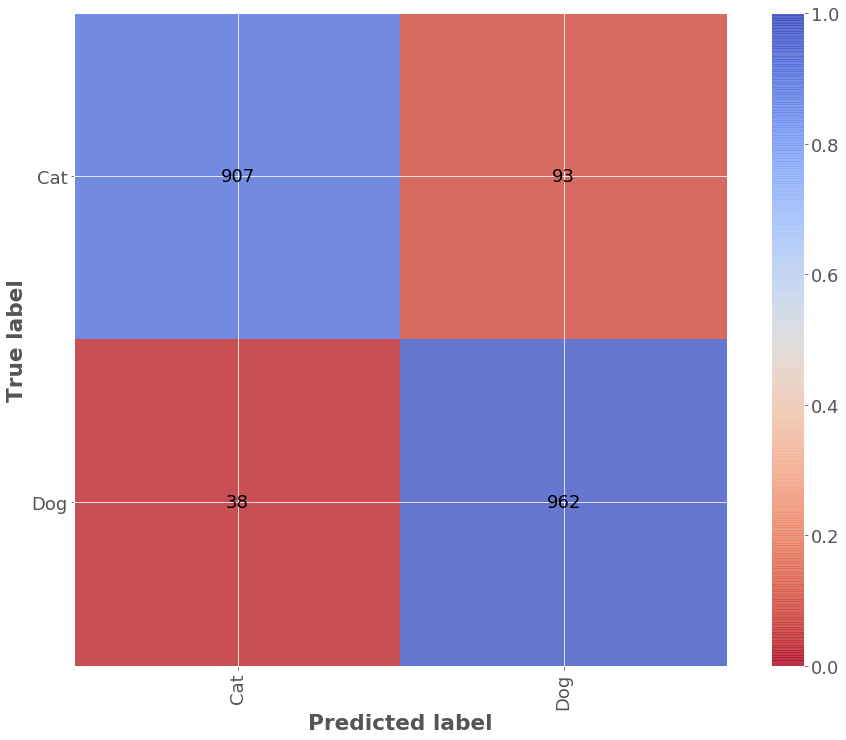
evaluator.show_results('average')
| model | f1_score | fdr | positives | sensitivity | specificity | auroc | negatives | precision | accuracy |
|---|---|---|---|---|---|---|---|---|---|
| mobilenet_v1.h5 | 0.934 | 0.064 | 1869 | 0.934 | 0.934 | 0.807 | 131 | 0.936 | 0.934 |
evaluator.show_results('individual')
| class | sensitivity | precision | f1_score | specificity | FDR | AUROC | TP | FP | FN | % of samples |
|---|---|---|---|---|---|---|---|---|---|---|
| cats | 0.907 | 0.960 | 0.933 | 0.962 | 0.040 | 1.0 | 907 | 38 | 93 | 50.0 |
| dogs | 0.962 | 0.912 | 0.936 | 0.907 | 0.088 | 1.0 | 962 | 93 | 38 | 50.0 |
mean, lower, upper = evaluator.plot_confidence_interval('accuracy', confidence_value=0.95)
Plot the Classifier Confidence Interval:
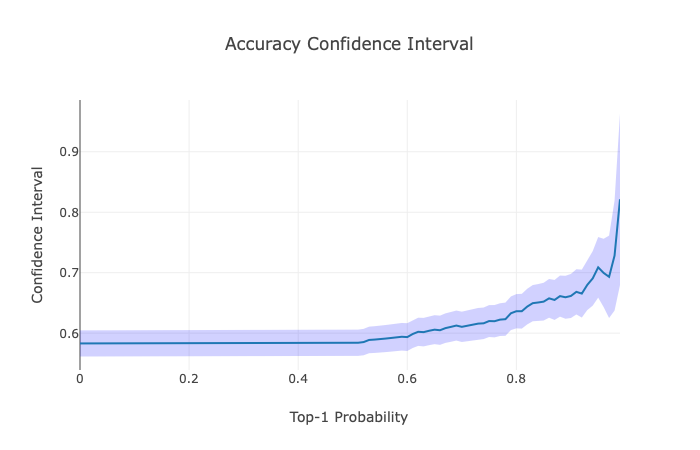
Plot the errors in which the classifier was more confident:
evaluator.plot_most_confident('errors', n_images=20)

And many more functions to evaluate and visualize results in the following lines and in the Example Notebook and Report Template
Clone the repository
git clone https://github.com/triagemd/keras-eval.git
To install project dependencies, inside the root folder run
script/up
To create an IPython kernel do the following in the virtual environment:
source .venv/bin/activate
pip install ipykernel
ipython kernel install --user --name=keras-eval.venv
Easy predictions and evaluations for a single model or an ensemble of many models.
The format to load models is the following:
For a single model
# The input is the model path
model_path = '/model_folder/resnet_50/model.h5'
# Inside model folder, there should be a '/model_folder/resnet_50/model_spec.json' file
with the following format as example:
{
"name": "your_name",
"preprocess_args": [
156.2336961908687,
122.03200584422879,
109.9825961313363
],
"preprocess_func": "mean_subtraction",
"target_size": [
299,
299,
3
]
}
For an ensemble of models
# The input is the parent folder
ensemble_models_dir = '/model_folder'
# That folder must contain several folders containing the models we want to load with their respective specs
# e.g. '/model_folder/resnet_50/model.h5', '/model_folder/resnet_50/model_spec.json', '/model_folder/densenet201/model.h5', '/model_folder/densenet201/model_spec.json'
Apply Data Augmentation at Test time
We include the addition of data_augmentation as an argument in evaluate(). It is a dictionary consisting of 3 elements:
- 'scale_sizes': 'default' (4 similar scales to Original paper) or a list of sizes. Each scaled image then will be cropped into three square parts. For each square, we then take the 4 corners and the center "target_size" crop as well as the square resized to "target_size".
- 'transforms': list of transforms to apply to these crops in addition to not applying any transform ('horizontal_flip', 'vertical_flip', 'rotate_90', 'rotate_180', 'rotate_270' are supported now).
- 'crop_original': 'center_crop' mode allows to center crop the original image prior do the rest of transforms, scalings + croppings.
If 'scale_sizes' is None the image will be resized to "target_size" and transforms will be applied over that image.
For instance: data_augmentation={'scale_sizes':'default', 'transforms':['horizontal_flip', 'rotate_180'], 'crop_original':'center_crop'}
For 144 crops as the GoogleNet paper, select data_augmentation={'scale_sizes':'default', 'transforms':['horizontal_flip']}.
This results in 4x3x6x2 = 144 crops per image.
probs, labels = evaluator.evaluate(data_dir=data_dir, top_k=2, confusion_matrix=True, data_augmentation={'scale_sizes': [356, 284], 'transforms': ['horizontal_flip'], 'crop_original': 'center_crop'})
To evaluate on coarse classes after training on granular classes
Given a model trained on M classes and test set based on N classes (M > N), allow the evaluation on sets of classes by providing a concept dictionary.
Case 1: Regular evaluation
E.g. Training scenario:
[class_0]
[class_1]
[class_2]
[class_3]
Regular evaluation scenario:
[class_0]
[class_1]
[class_2]
[class_3]
Results for regular evaluation:
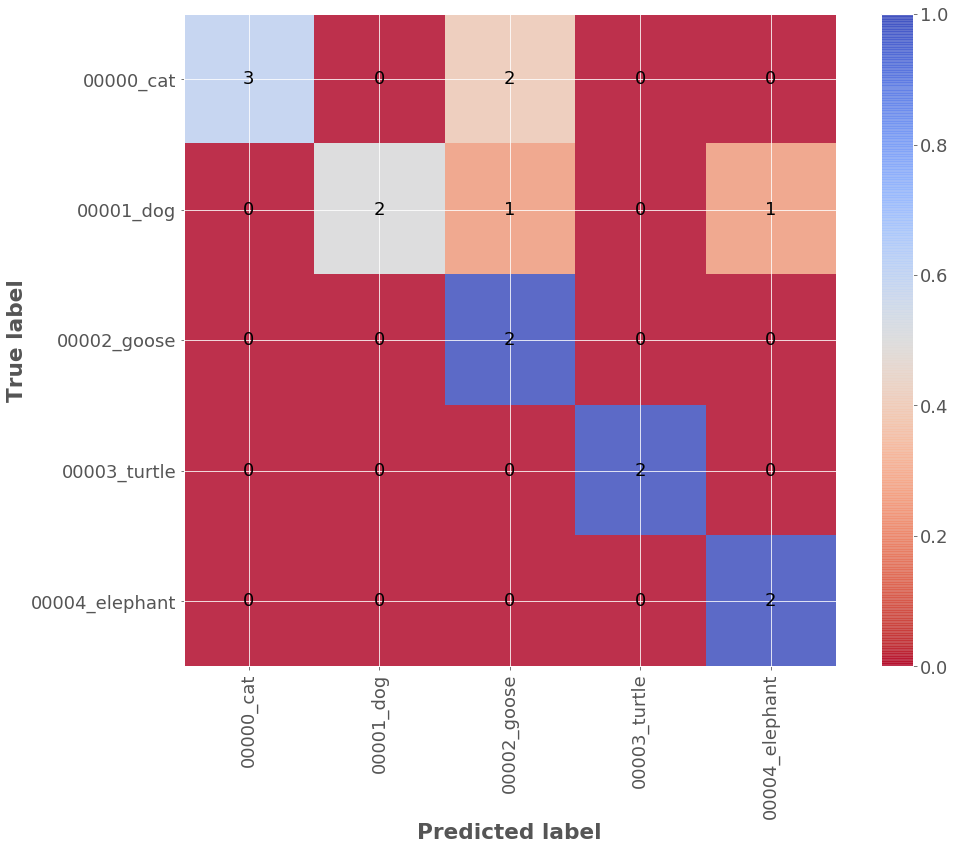
| model | accuracy | precision | f1_score | number_of_samples | number_of_classes |
|---|---|---|---|---|---|
| animals_combine_classes.hdf5 | 0.733 | 0.876 | 0.744 | 15 | 5 |
Case 2: Class consolidated evaluation Evaluate on classes grouped on sets of training classes. Class consolidated evaluation scenario:
[test_set_0] class_0 or class_1
[test_set_1] class_2 or class_3
The probability changes during class consolidation as seen below:
probability(test_set_0) = probability(class_0) + probability(class_1)
probability(test_set_1) = probability(class_2) + probability(class_3)
For this purpose, the mapping between the training and testing dictionary must be provided as a .json file with the following format:
[
{
"class_index": 0,
"class_name": "00000_cat",
"group": "00000_domestic"
},
{
"class_index": 1,
"class_name": "00001_dog",
"group": "00000_domestic"
},
{
"class_index": 2,
"class_name": "00002_goose",
"group": "00001_water"
},
{
"class_index": 3,
"class_name": "00003_turtle",
"group": "00001_water"
},
{
"class_index": 4,
"class_name": "00004_elephant",
"group": "00002_wild"
}
]
Results for class consolidated evaluation:
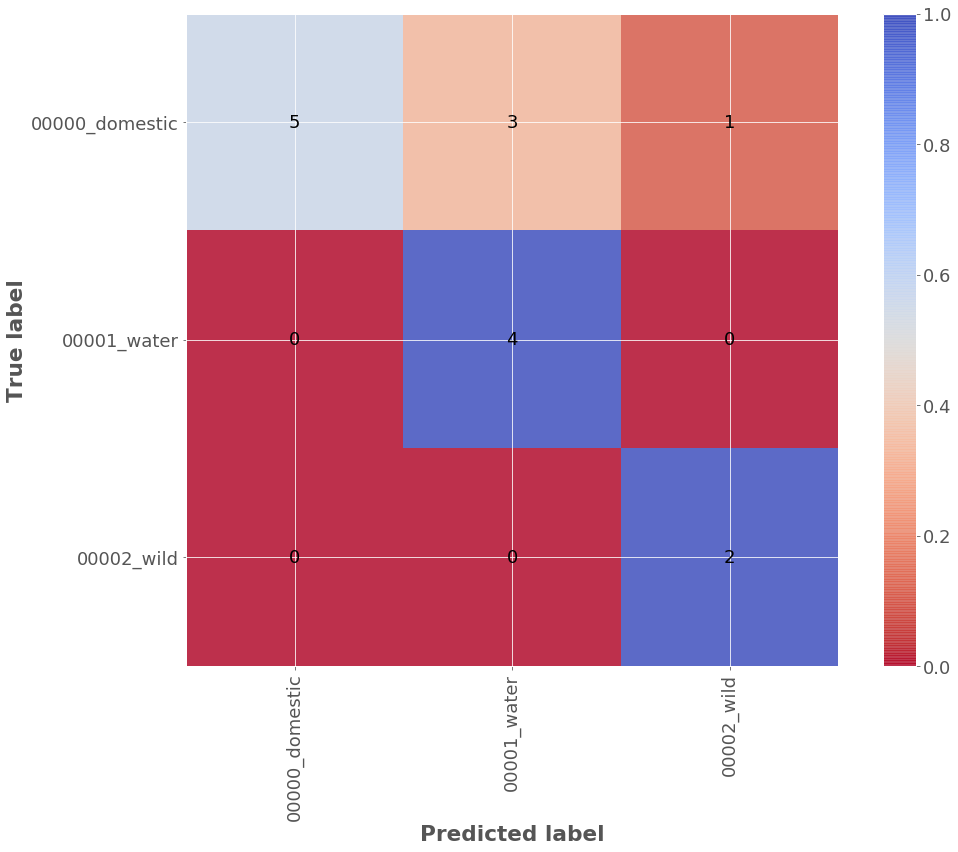
| model | accuracy | precision | f1_score | number_of_samples | number_of_classes |
|---|---|---|---|---|---|
| animals_combine_classes.hdf5 | 0.733 | 0.841 | 0.729 | 15 | 3 |
You can specify all the following options.
Evaluator
from keras_eval.eval import Evaluator
evaluator = Evaluator(
data_dir=None,
concepts=None,
concept_dictionary_path=None,
ensemble_models_dir=None,
model_path=model_path,
loss_function='categorical_crossentropy',
metrics=['accuracy'],
batch_size=32,
verbose=0)
Evaluate a set of images.
Each sub-folder under 'data_dir/' will be considered as a different class. E.g. 'data_dir/class_1/dog.jpg' , 'data_dir/class_2/cat.jpg'
If you are evaluating an ensemble of models, we currently allow for these probability combination modes: 'maximum', 'arithmetic', 'geometric', 'harmonic'
evaluate
data_dir = 'tests/files/catdog/test/'
probabilities, labels = evaluator.evaluate(data_dir=None, top_k=2, filter_indices=None, confusion_matrix=False, save_confusion_matrix_path=None, verbose=1)
# probabilities.shape = [n_models, n_samples, n_classes]
# labels.shape = [n_samples, n_classes]
Predict class probabilities of a set of images from a folder.
predict
folder_path = 'tests/files/catdog/test/cat/'
probs = evaluator.predict(folder_path)
Predict class probabilities of a single image
predict
image_path = 'tests/files/catdog/test/cat/cat-1.jpg'
probs = evaluator.predict(image_path)
After making predictions you can access to evaluator.image_paths to get a list of the files forwarded.
You can also add more options once the Evaluator object has been created, like loading more models or setting class names and abbreviations to show in the confusion matrix.
add_model
model_path = '/your_model_path/model.h5
# Also supports model custom objects
custom_objects = None
evaluator.add_model(model_path, custom_objects)
add_model_ensemble
model_path = '/your_model_ensemble_path/'
evaluator.add_model_ensemble(model_path)
set_concepts
concepts = [{'label':'Cat', 'id': 'cats'},
{'label':'Dog', 'id': 'dogs'},]
evaluator.set_concepts(concepts)
For more information check the Example Notebook and the source code.
This library is mantained by @triagemd. To report any problem or issue, please use the Issues section.